내 방식대로 이분탐색을 정리 해보려고 한다.
이분탐색
이분 탐색은 탐색 범위가 클 때 사용한다.
예를 들어 탐색 범위가 0~1,000,000,000,000 이라면 완전 탐색으로는 최악의 경우 O(1,000,000,000,000) = 1,000,000,000,000으로 약 1만초 가량 걸린다고 볼 수 있다.
이분 탐색을 쓰면 O(n) = logn으로 1만초가 0.0000004초로 줄어든다.
큰 범위 내에서 쓰기는 정말 좋은데, 사용할 수 있는 조건이 있다.
기울기가 일정해야 한다
탐색할 숫자들의 기울기가 일정해야 한다는 점으로, 계속 상승하거나 계속 하락하는 추세를 보여아 한다.
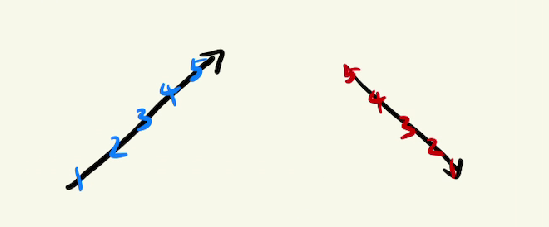
위와 같이 정렬이 되어있어야 하고, 증가 혹은 하락 추세를 보여야 한다.
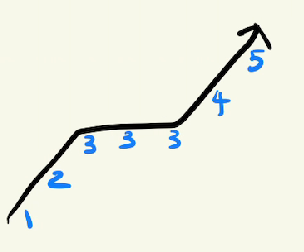
이렇게 중복되는 수가 있어도 정렬만 되어있다면 적용이 가능하다.
다만 정답이 여러개가 나올 수 있으므로 upper bound, lower bound중 어느것을 쓸건지 고려 해봐야 한다.
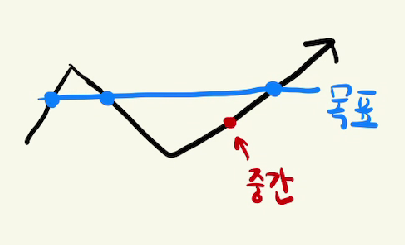
이분탐색은 중간 좌표를 오른쪽, 왼쪽으로 움직여서 목표에 도달하는 탐색이라고 할 수 있는데(실제로는 시작, 끝 좌표를 움직인다), 위를 보면 목표가 왼쪽인지 오른쪽인지 알 수 없다.
그래서 그래프가 꺾이는 모습이 나오면 이분탐색을 적용할 수 없다.
y축으로 생각해보자
그런데 꺾이는 그래프에서도 쓸 수 있는 방법이 있다.
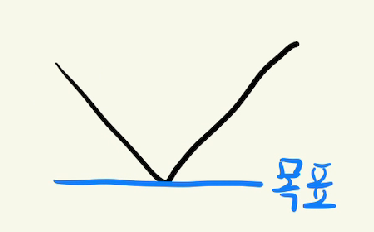
위와 다르게 목표지점이 어딘지는 모르지만 최솟값이나 최대값인 경우에 유용한 방법인데,
탐색을 x축 기준으로 하는 것이 아닌 y축 기준으로 하는 것이다.
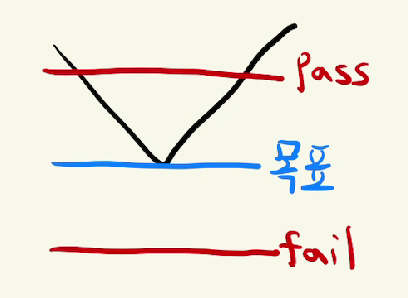
해당 값이 그래프에 범위 안에 있는지 확인하면서 범위를 수정해가면 된다.
그래프 범위 밖에 있다면 fail, 그래프 범위 안에 있다면 pass로
아래와 같이 그래프가 꺾이는 모양을 없앨 수 있다.
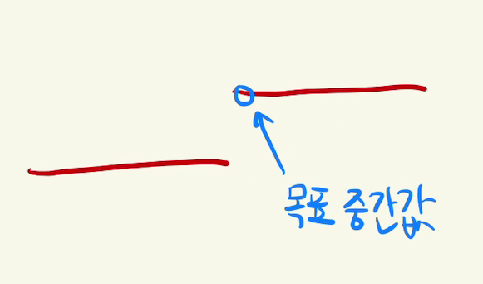
값이 2가지 밖에 없고 중복값이 대부분 이므로 lower bound를 써서 풀어야 한다.
내가 쓰는 방식
여러 풀이를 보면 mid와 end가 쓰이는 방식이 사람마다 다르다.
나는 mid를 범위에서 빼버리지 않고, start, end를 (0,N) 보다 (0,N-1)로 쓴다.
그래서 이렇다.
def find(arr, num):
start = 0
end = len(arr) - 1
while start < end:
mid = (start + end)//2
if num <= arr[mid]:
end = mid
else:
start = mid+1
return end