
문제
프로그래머스 연습문제
- Lv 1. 숫자 짝꿍 (Python)
https://school.programmers.co.kr/learn/courses/30/lessons/131128
코드 구현
from collections import Counter
def solution(X, Y):
answer = ''
X = Counter(X)
Y = Counter(Y)
for i in range(9, -1, -1):
if(X[str(i)] != 0 and Y[str(i)] != 0):
can_make_couple = min(X[str(i)], Y[str(i)])
answer += str(i) * can_make_couple
if (len(answer) == 0):
return "-1"
if(answer[0] == "0"):
return "0"
return answer풀이
- 처음에 생각했던 알고리즘
- 정렬 → 순서대로 비교하며 중복으로 있는 숫자를 우선 다 뽑아내서 커플로 만들고 →
X와Y에서는 제거 - 남은 숫자들을 순회하며 → 만약 짝을 만들 수 있는 같은 숫자면 → 커플로 만들고 →
X와Y에서 제거 - 사실상 제한사항 첫번째에 있는 조건에 의해 무조건… 시간 초과가 날 것 같았다.
왜냐하면 남은 숫자들을 순회하는 과정에서2중 for문을 돌기 때문에 자릿수가 큰 숫자들이라면 너무 오랜 시간이 걸리게 된다.
- 정렬 → 순서대로 비교하며 중복으로 있는 숫자를 우선 다 뽑아내서 커플로 만들고 →
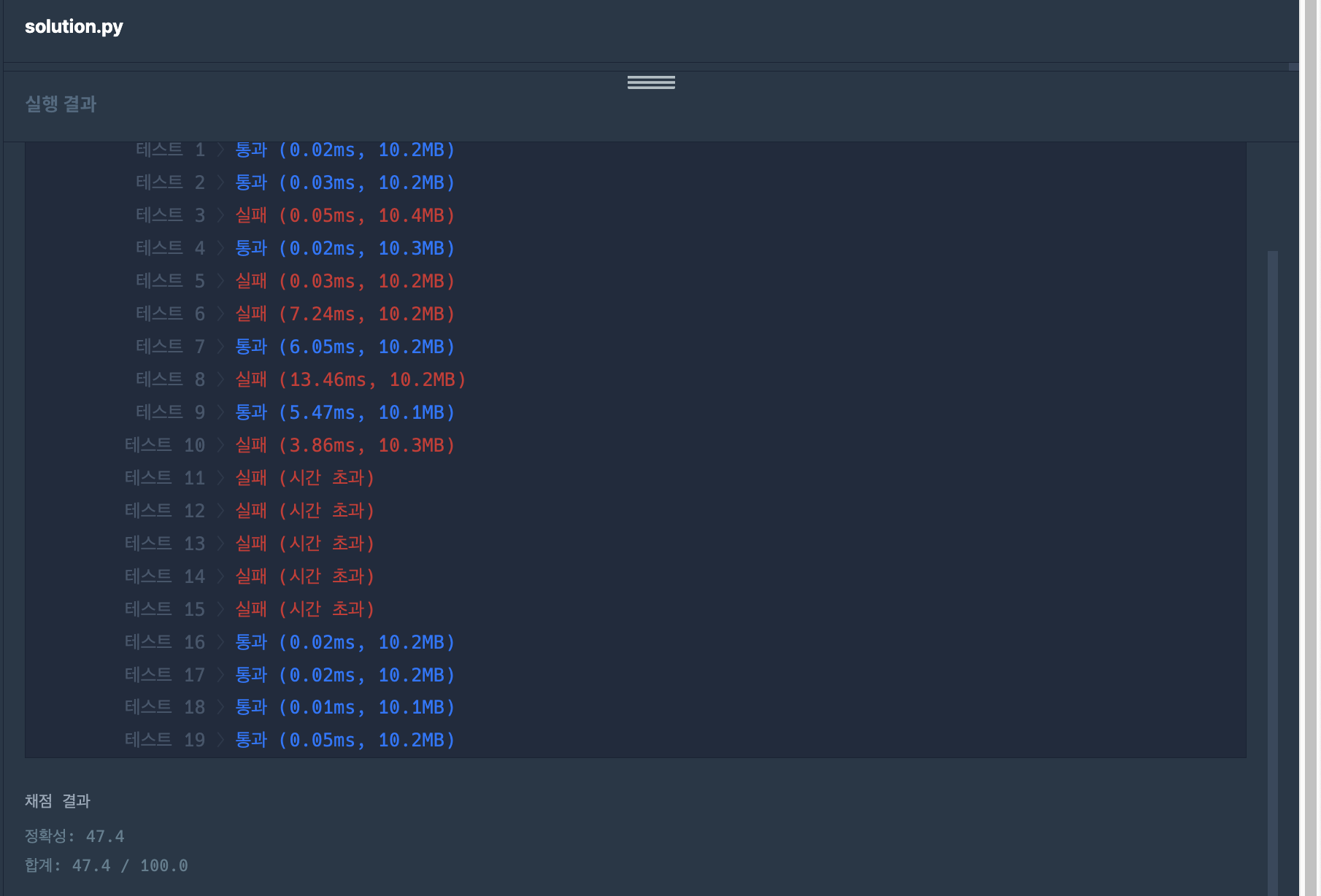
-
따라서 찾아봤던 첫번째 방법
- 조합들을 만드는 과정에서 두 리스트에서 하나씩 뽑아내어 조합을 만드는 함수를 찾아보았다.
itertools.product(X, Y, repeat=1):X에서 1개,Y에서 1개씩 뽑아서 중복 순열을 만들어준다.- 그러나 이런식으로 만들게되면 중복되는 문자가 겹치게 되어 순열에 담기게 된다.
- ex)
X= "12321",Y= "42531", 정렬하여 순서대로 중복 뽑아내기 = ['1'] 밖에 들어가지 않게 됨
그 다음product()으로 순열을 만들어서 짝을 만들게 되면, [('2', '2'), ('2', '2'), ('3', '3')] 이 생성된다.
즉, 2가 중복되어 들어가게 되어버린다. - 따라서 이 방법도 실패 …
-
💡 최종 정답
collections.Counter()라는 클래스를 찾게 되었다.Counter에 문자열을 넣게되면 문자열 내의 각 문자들이 몇 번씩 나타나는지를 알려주는 객체가 반환된다.- 따라서
X와Y를Counter()에 넣어서 각 숫자들이 몇번씩 나오는지 만들어놓고 →for문으로 9~0까지 순회하였을 때 → 만약 해당 숫자가 1개라도 서로 존재하고 있다면 → 둘 중 최솟값 (== 짝꿍을 만들 수 있는 최대 횟수) 을 구하여 해당 수를 최솟값 개수만큼answer에 넣어준다 !!! - ex)
X= "12321",Y= "42531"
Counter({'1': 2, '2': 2, '3': 1})
Counter({'4': 1, '2': 1, '5': 1, '3': 1, '1': 1})
9부터 0까지 순회 → 둘 다 들어있는 3 발견 →둘 중 최솟값 (짝꿍 만들 수 있는 최대 횟수) * “3”을 answer에 추가 → … → 정답 : “321”
What I learned
다른 사람 정답 코드
Counter() 없이 count()만으로도 가능하였다…
for i in range(9,-1,-1) :
answer += (str(i) * min(X.count(str(i)), Y.count(str(i))))▶️ collections.Counter()
참고 : https://www.daleseo.com/python-collections-counter/
from collections import Counter
Counter(["hi", "hey", "hi", "hi", "hello", "hey"])
>>> Counter({'hi': 3, 'hey': 2, 'hello': 1})
Counter("hello world")
>>> Counter({'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
c = Counter("hello world")
c.get["없는값"]
c["없는값"]
>>> # 없는 값을 가져오려 하면 0을 반환▶️ collections.Counter().most_common()
데이터의 개수가 많은 순으로 정렬된 배열을 리턴
from collections import Counter
Counter('hello world').most_common()
>>> [('l', 3), ('o', 2), ('h', 1), ('e', 1), (' ', 1), ('w', 1), ('r', 1), ('d', 1)]이 메서드의 인자로 숫자 K를 넘기면 그 숫자 만큼만 리턴하기 때문에, 가장 개수가 많은 K개의 데이터를 얻을 수 있다.
from collections import Counter
Counter('hello world').most_common(1)
>>> [('l', 3)]▶️ itertools.product(A, B, repeat=)
참고 : https://lar542.github.io/Python/2019-07-11-python2/
repeat의 수만큼 A와 B에서 뽑아서 중복 순열을 만들어준다. (기본값 = 1)
from itertools import product
iterable1 = 'ABCD'
iterable2 = 'xy'
iterable3 = '1234'
>>> list(product(iterable1, iterable2, iterable3))
# [('A', 'x', '1'), ('A', 'x', '2'), ('A', 'x', '3'), ('A', 'x', '4'), ('A', 'y', '1'), ('A', 'y', '2'), ('A', 'y', '3'), ('A', 'y', '4'), ('B', 'x', '1'),
# ('B', 'x', '2'), ('B', 'x', '3'), ('B', 'x', '4'), ('B', 'y', '1'), ('B', 'y', '2'), ('B', 'y', '3'), ('B', 'y', '4'), ('C', 'x', '1'), ('C', 'x', '2'),
# ('C', 'x', '3'), ('C', 'x', '4'), ('C', 'y', '1'), ('C', 'y', '2'), ('C', 'y', '3'), ('C', 'y', '4'), ('D', 'x', '1'), ('D', 'x', '2'), ('D', 'x', '3'),
# ('D', 'x', '4'), ('D', 'y', '1'), ('D', 'y', '2'), ('D', 'y', '3'), ('D', 'y', '4')]▶️ ””.join(리스트), ”구분자”.join(리스트)
참고 : https://blockdmask.tistory.com/468
a = ['a', 'b', 'c', 'd', '1', '2', '3']
# 리스트를 문자열로 변환
result = "".join(a)
print(result)
>>> "abcd123"
# 구분자를 포함하여 리스트를 문자열로 변환
result = "_".join(a)
print(result)
>>> "a_b_c_d_1_2_3"
데굴데굴