1. GROUP BY
- GROUP BY절과 집계함수
SELECT expr1, expr2, ...
FROM ...
(WHERE) ...
AND ...
GROUP BY ... <-- WHERE 절과 ORDER BY 절 사이에 위치
(ORDER BY) ... -- 괄호는 생략 가능SELECT station_name FROM subway_statistics WHERE gubun = '승차' GROUP BY station_name --여기에 명시한 컬럼들은 SELECT 절에도 명시 ORDER BY station_name;
- 조회 결과 일부만 발췌
2. 집계함수
: 집계함수는 SELECT 절에서만 사용 가능
- COUNT(expr): expr의 전체 개수 집계
- MAX(expr): expr의 최대값 반환
- MIN(expr): expr의 최소값 반환
- SUM(expr): expr의 합계 반환
- AVG(expr): expr의 평균값 반환
- VARIANCE(expr): expr의 분산 반환
- STDDEV(expr): expr의 표준편차 반환
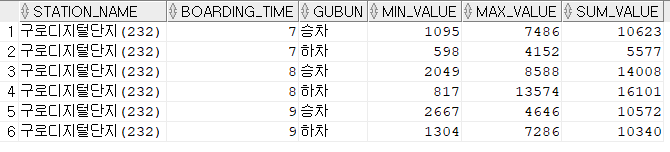
구로디지털단지역 시간별 승하차 인원 조회하기
SELECT station_name ,boarding_time ,gubun ,MIN(passanger_number) min_value ,MAX(passanger_number) max_value ,SUM(passanger_number) sum_value FROM subway_statistics WHERE station_name in ('구로디지털단지(232)') GROUP BY station_name, boarding_time, gubun ORDER BY station_name, boarding_time, gubun;
3. HAVING절
: GROUP BY 절과 함께 사용되면 집계함수 결과 값으로 조건을 걸 때 사용.
SELECT station_name ,boarding_time ,gubun ,MIN(passanger_number) min_value ,MAX(passanger_number) max_value ,SUM(passanger_number) sum_value FROM subway_statistics GROUP BY station_name, boarding_time, gubun HAVING SUM(passanger_number) BETWEEN 15000 AND 16000 ORDER BY 6 DESC; <-6번째 컬럼(SUM) 내림차순 정렬

4. 집합쿼리
- UNION ALL: 두 집합을 하나로 통합하여 조회(중복 데이터 포함)
-- 새로운 쿼리 생성 CREATE TABLE emp08 ( emp_id2 NUMBER NOT NULL, emp_name2 VARCHAR2(100) NOT NULL, gender VARCHAR2(10), age NUMBER, hire_date DATE, etc VARCHAR2(300), CONSTRAINT emp08_pk PRIMARY KEY (emp_id2) );
데이터 입력
INSERT INTO emp08 ( emp_id2, emp_name2, gender, age, hire_date ) VALUES (1, '선덕여왕', '여성', 23, TO_DATE('2018-02-01', 'YYYY-MM-DD')); INSERT INTO emp08 ( emp_id2, emp_name2, gender, age, hire_date ) VALUES (2, '허난설헌', '여성', 33, TO_DATE('2018-02-01', 'YYYY-MM-DD')); INSERT INTO emp08 ( emp_id2, emp_name2, gender, age, hire_date ) VALUES (3, '김만덕', '여성', 43, TO_DATE('2018-02-01', 'YYYY-MM-DD')); INSERT INTO emp08 ( emp_id2, emp_name2, gender, age, hire_date ) VALUES (4, '장희빈', '여성', 35, TO_DATE('2018-02-01', 'YYYY-MM-DD')); INSERT INTO emp08 ( emp_id2, emp_name2, gender, age, hire_date ) VALUES (5, '신사임당', '여성', 45, TO_DATE('2018-02-01', 'YYYY-MM-DD'));
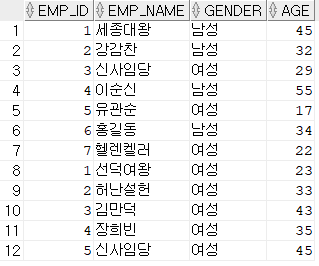
기존 emp03과 emp08의 UNION ALL 집합(중복 데이터도 조회됨)
SELECT emp_id, emp_name, gender, age FROM emp03 UNION ALL SELECT emp_id2, emp_name2, gender, age <- SELECT절의 수, 데이터형 일치해야 함 FROM emp08;
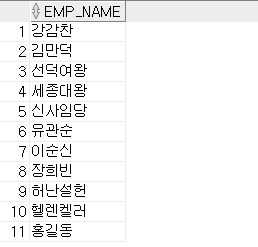
- UNION: 두 집합을 하나로 통합하여 조회(합집합, 중복 제거)
SELECT emp_name FROM emp03 UNION SELECT emp_name2 FROM emp08 ORDER BY 1; --1번 컬럼(emp_name)을 기준으로 오름차순(ASC) 정렬
중복된 신사임당 데이터가 제거됨.
여기서 다른 컬럼(emp_id 등)을 명시하면 제거되지 않고 모두 조회됨.
- INTERSECT: 두 집합의 공통원소만 조회(교집합)
SELECT emp_name FROM emp03 INTERSECT SELECT emp_name2 FROM emp08 ORDER BY 1;
만약 공통원소가 없다면 빈 데이터로 조회됨.
- MINUS: 첫 번째 쿼리 결과에서 두번 째 쿼리 결과를 제외하고 조회(차집합)
SELECT emp_name FROM emp03 MINUS SELECT emp_name2 FROM emp08 ORDER BY 1;
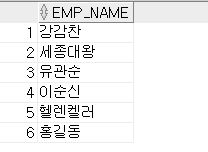
공통원소인 심사임당 데이터가 제거됨.
여기서도 역시 emp_id 처럼 중복데이터가 아닌 컬럼이 명시될 경우 제거되지 않음.
※집합 연산자는 무조건 첫 번째 SELECT 문의 컬럼 명으로 조회됨.

Data analysis beginner