Pandas
- Panel Data의 약자
- Python 전용 오픈소스 데이터분석 및 조작 라이브러리
- 다양한 파일 형식 지원
- 데이터 정제 및 조작에 특화된 라이브러리
- 데이터 이상치, 결측치, 중복 제거 등 다양한 기능을 제공
- 데이터 필터링, 병합, 피벗 등을 지원하여 복잡한 데이터를 손쉽게 분석
- DataFrame, Series 자료 구조 지원
- DataFrame : 2차원 이상
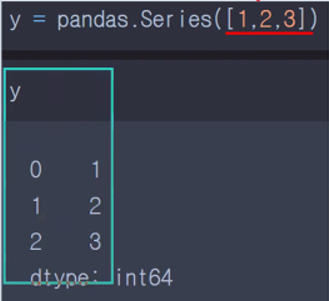
- Series : 1차원
- ndarray를 활용하여 만든 자료 구조이기 때문에 Numpy Library와 상호작용이 뛰어남
- DataFrame - 2차원의 자료구조
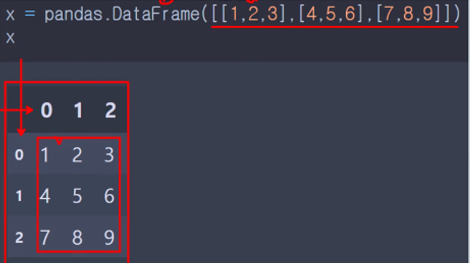
- Series - 1차원의 자료구조
- Pandas 라이브러리 로딩
import pandas as pd
Series
- Series 다루기
-
Series 생성
-
pd.Series(시퀀스 자료구조)
pop = pd.Series([9668465, 3391946, 2642828, 1450062]) poppop = pd.Series([9668465, 3391946, 2642828, 1450062], index = ['서울', '부산', '인천', '광주']) pop파이썬은 사실 모든 자료가 "객체"형태임
# 원본을 복사했다고 생각하고, 복제 변수명에 대입해서 사용했더니, # 같은 객체를 가리키게 되서 원본 유지가 안된다... # 그래서 copy() 함수를 사용해서 복제본을 만들고, 원본을 유지할 수 있다! pop2 = pop.copy() pop2[2] = 1 print(pop2) print(pop)
-
-
Series 속성
-
Seires 값 확인
display(pop.values) display(pop.array) -
Series 인덱스명 확인
pop.index -
Series 자료형 확인
pop.dtype -
Series type 확인
type(pop) -
Series에 이름 지정 → 컬럼명 지정
# Series는 DataFrame에서 열을 하나 떼온 것과 같음 pop.name = '인구' pop -
Series에 index 이름 지정
pop.index.name = '도시' pop -
Series 연산
pop / 1000000
-
-
데이터를 판다스 Series 객체로 생성
icecream = pd.Series([500, 800, 200], index=['메로나', '누가바', '빠삐코'], name='가격') icecreamicecream.index.name = '종류' icecream
-
Series 인덱싱, 슬라이싱
- Series 인덱싱 → 딕셔너리(Key값)처럼 index 이름으로 접근 가능!
pop[1], pop['부산'] - Series 다중인덱싱
pop[[0,3,1]]pop[['서울','광주','부산']]
- Series 인덱싱 → 딕셔너리(Key값)처럼 index 이름으로 접근 가능!
-
iloc와 loc 속성
-iloc(integer location) : "행번호"를 가지고 값을 인덱싱하는 방법
-loc(location) : "인덱스 이름"을 가지고 값을 인덱싱하는 방법
-iloc, loc : 함수가 아닌 속성
- iloc 인덱싱 → "행번호" 접근
pop.iloc[0] - iloc 슬라이싱
pop.iloc[:2] - loc 인덱싱 → "인덱스 이름"으로 접근
pop.loc["부산"] - loc 슬라이싱 → loc는 iloc와 다르게 끝값을 "포함"
pop.loc[:"부산"] - loc와 iloc 다중인덱싱
pop.loc[['광주', '부산']]pop.iloc[[3,1]]# 응용! target = ['광주','부산'] pop.loc[target]
- iloc 인덱싱 → "행번호" 접근
-
Series boolean 인덱싱
- 인구수가 250만 이상인 데이터를 추출
pop[pop >= 2500000] - 인구수가 250만 ~ 500만까지의 도시는?
# and는 비교연산자 → 단일 값에 대해서만 가능 # &는 논리연산자 → 다중값(시퀀스 자료구조) 가능 pop[(pop >=2500000) & (pop <= 5000000)]
- 인구수가 250만 이상인 데이터를 추출

- 실습
딕셔너리로 Series 생성
# IT 직군의 월평균임금(내림 적용)
data = {'IT 기획자':8644000, '데이터분석가':7158000, '응용SW개발자':6426000, 'IT품질관리자':8294000}
# 딕셔너리 자료형을 Series로 형변화
sw_M_wage = pd.Series(data)
sw_M_wagedata2 = {'IT 기획자':9543000, '데이터분석가':11226000, '시스템SW개발자':5100000, 'IT마케터':7801000}
sw_M_wage2 = pd.Series(data2)
sw_M_wage2월 평균임금 계산
# ndarray 기반 → 요소별 연산이 가능
(sw_M_wage / 23).astype(np.int64)
sw_M_wage두 회사의 임금 차이를 계산
# NaN : 결측치(비어있는 값) : 연산이 되지않고 Null 값으로 나오게 됨
wage_minus = sw_M_wage2 - sw_M_wage
wage_minus비어있지 않은 데이터만 보려면?
# notnull() → 비었는지, 안 비었는지 물어봄 → boolean 마스크를 반환!!
print(wage_minus.notnull())
wage_minus[wage_minus.notnull()]비어있는 데이터만 보려면?
# isnull() → 비었는지, 안 비었는지 물어봄 → boolean 마스크를 반환!!
print(wage_minus.isnull())
wage_minus[wage_minus.isnull()]-
Series 추가, 수정, 삭제
-
수정
sw_M_wage2['IT 기획자'] = 9999000 sw_M_wage2 -
추가
sw_M_wage2['IT컨설턴트'] = 9805000 sw_M_wage2 -
삭제
del sw_M_wage2['IT 기획자']
-

노는게 제일 좋아~!