
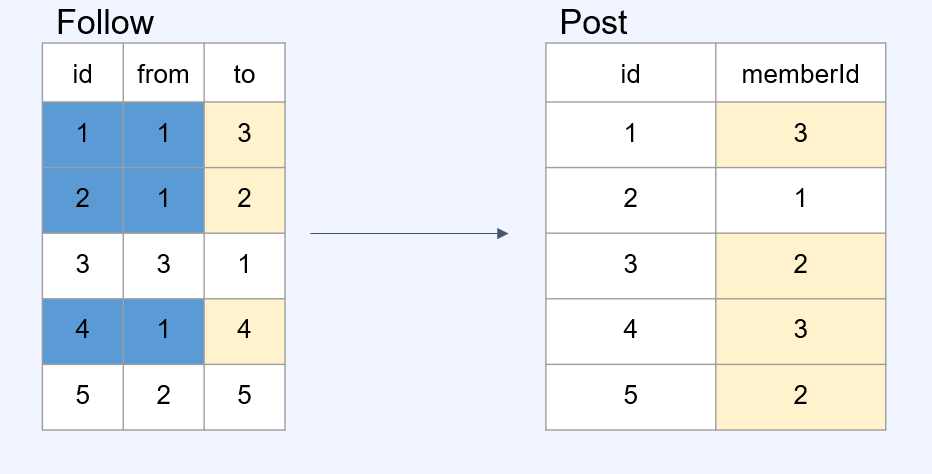
pull model
- 조회 시점의 부하를 쓰기 시점의 부하로 치환 (쓰기 성능↑ , 조회 성능↓ , 시간 복잡도↑ , 공간 복잡도↓)
- 장점 : 원본 데이터를 직접 참조하기에 정합성 보장에 유리
- 단점 :
ex) 1번 유저(from)가 팔로워들(to)의 게시물(post)을 타임라인에 띄우려면 Post Table에
to.id(post.memberId)로 조회를 해야하기에 조회에 많은 부하가 발생
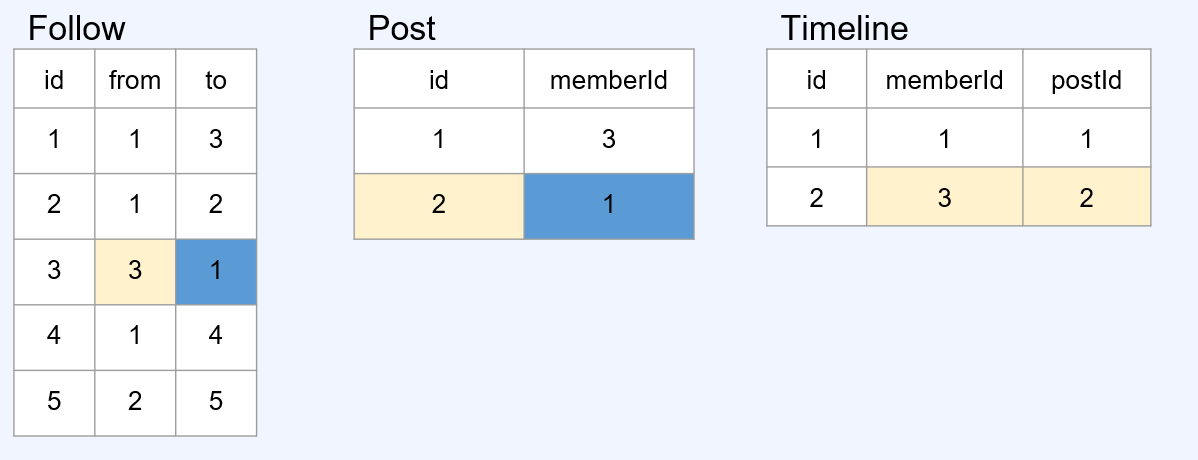
push model
- 쓰기 시점의 부하를 조회 시점의 부하로 치환 (쓰기 성능↓ , 조회 성능↑)
- 시간 복잡도↓ , 공간 복잡도↑
ex) 1억 명의 팔로워를 가진 유튜버가 게시물 한개를 올리면 1억개의 TimeLine write가 발생

코드를 거의 아트의 경지로 끌어올려서 내가 코드고 코드가 나인 물아일체의 경지