
Kafka란
Kafka : Event-Streaming platform
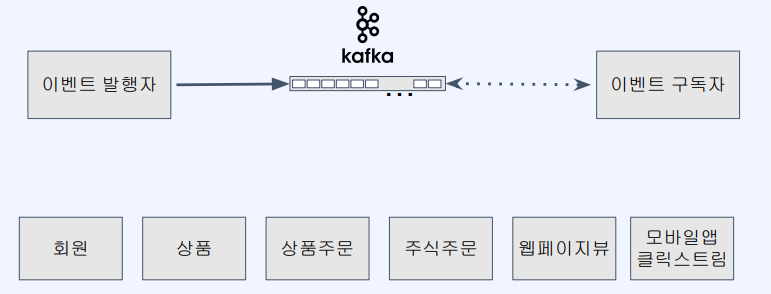
이벤트가 발생했을 때 Kafka에 이벤트를 저장하고 이벤트 구독자에게 전달된다
Kafka를 사용하지 않을 경우
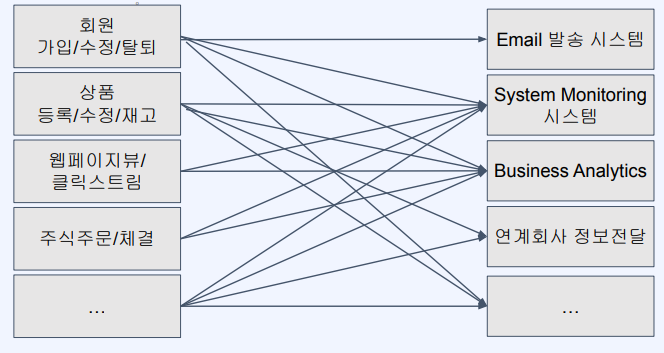
- 시스템끼리 직접적으로 연결 되어있다
- 장애상황 시 문제가 발생
Kafka를 사용할 경우
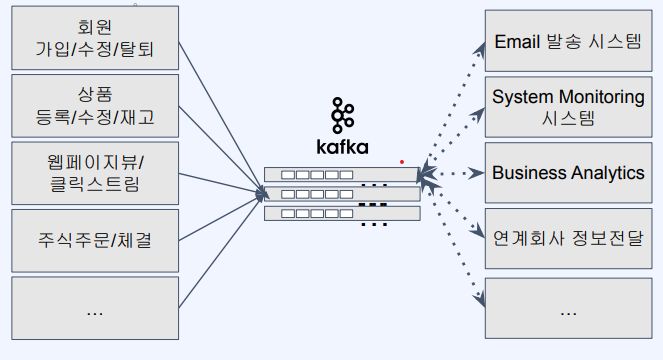
- 프로세스의 단순화
- 장애상황 시 이벤트가 쌓이고 복구가 되었을 경우 이벤트를 소비함
- 직접 연결되어 있지 않고 이벤트가 쌓이기에 장애상황 시 큰 에러가 발생하지 않음
Kafka를 사용하지 않은 동기 방식의 상품등록 시스템 프로세스
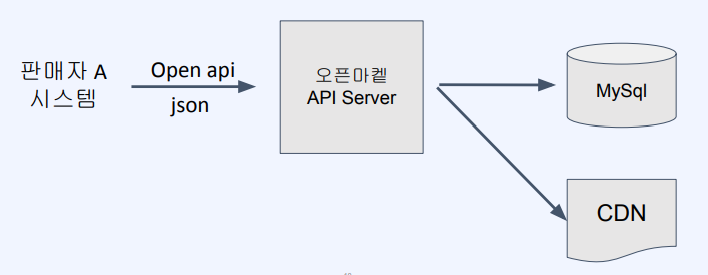
- 데이터베이스의 긴 트랜잭션을 기다려야 함
- 상품의 이미지 url을 다운받고 CDN에 업로드 하는 시간이 매우 가변적
- 트랜잭션이 실패했을 경우 사용자가 다시 업로드 해야함
Kafka를 사용한 비동기 방식의 상품등록 시스템 프로세스
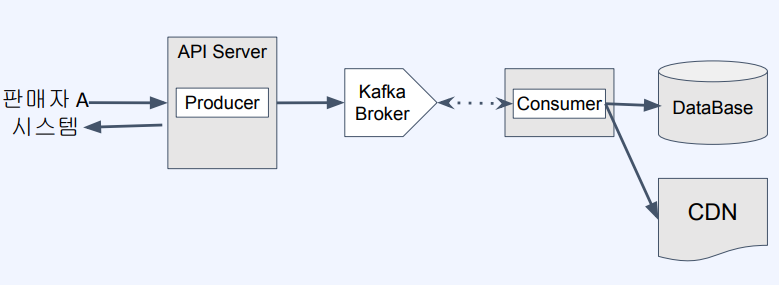
- 데이터를 Kafka Broker에 넣어두고 실제 트랜잭션을 타지 않기에 사용자 입장에서 매우 빠르게 느껴짐
Kafka Cluster
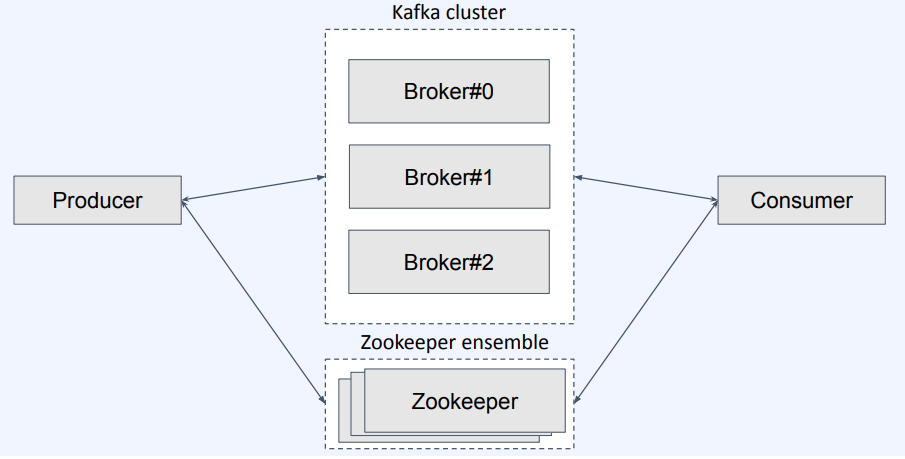
- Kafka는 에러에 대응하기 위해 브로커를 클러스터 구조로 만들어놨다
- 하나의 서버에 장애가 나면 다른 브로커가 대체함
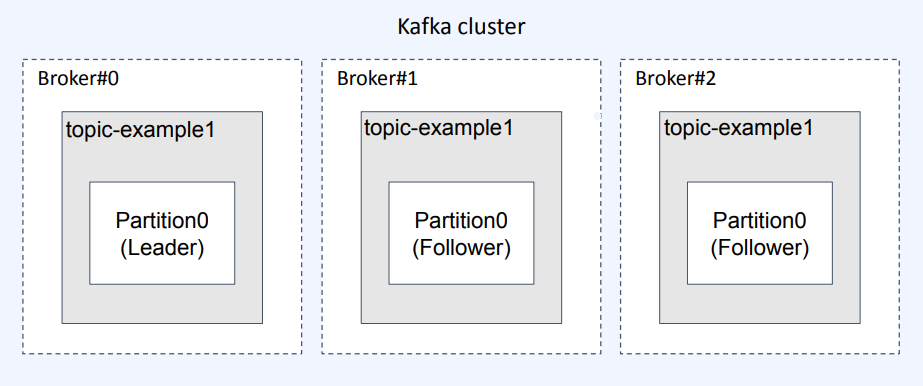
- topic은 하나의 주제(데이터, 메세지의 종류)를 구별하기 위한 기본 단위
- 브로커에는 많은 topic이 존재 가능
- 프로듀서나 컨슈머가 메세지를 발행하거나 cunsume할 때 topic을 지정 해줘야함
- 브로커는 topic이 받은 메세지를 partition에 저장
- Kafka는 OS에 FileSystem 자체를 저장소로 지정함
- topic을 설정할 때 replication factor의 수를 설정해야함
- 1 : 원본 이외의 replication factor를 생성하지 않는다
- 3 : 원본 이외의 replication factor를 2개 생성
- 최소 3이상으로 설정이 바람직함
- 파티션은 리더 파티션과 팔로워 파티션이 존재
- 리더 파티션
- 리더 파티션은 producer와 consumer가 연결되어 있음
- 리더 파티션은 쓰기와 읽기가 실행
- 팔로워 파티션
- 팔로워 파티션은 replication factor 설정에 의해 만들어진 복제본
- 팔로워 파티션은 producer와 consumer가 연결되어 있지 않음
- 팔로워 파티션은 쓰기와 읽기가 불가능
- 리더 파티션이 장애가 났을 때 리더 파티션과 교체
- 리더 파티션의 데이터를 지속적으로 싱크함
- 교체 상황
- 리더가 교체될 때 일시적으로 쓰기 읽기에 timeout이 발생
- 프로듀서는 새로운 리더 파티션이 확정 될 때까지 계속 호출을 보냄
- 리더 파티션
장단점
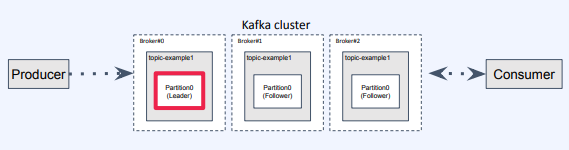
장점
- 클러스터 구조에서 카프카는 브로커를 분산하고 리플리카를 통해 장애 상황을 대비가 가능
단점
- 카프카는 리더 파티션에서만 읽기 쓰기 처리가 가능하기에 하나의 파티션으로는 처리량이 제한적
- 많은 브로커가 존재해도 처리량에 대해 제한적
해결
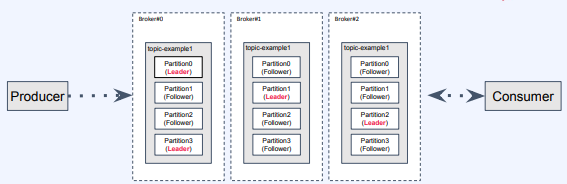
- Kafka는 하나의 토픽에 init되는 메세지를 분할하여 개별 파티션에 나누어 처리
- 위 topic에는 브로커마다 리더 파티션이 고르게 분포해있다.
- topic에 하나의 파티션만 존재할 때보다 분산 환경에 장점을 살림
- 위 topic에는 브로커마다 리더 파티션이 고르게 분포해있다.
하나의 파티션만 사용할 때
큐와 같은 구조

- 일반적인 메세지 큐는 producer가 메세지를 init하고 consumer가 메세지를 가져가면 메세지 큐에 있는 데이터가 삭제
- Kafka는 partition내에서 메세지의 고유 순서를 지정
- consumer가 메세지를 가져가도 데이터가 삭제되지 않음
- topic이 지정해준 시간이 지나면 그 때 자동으로 오래된 데이터가 삭제
- Kafka는 Offset을 통해 각각의 consumer group이 각각의 파티션 별로 읽어간 레코드의 위치를 기록
- Offset은 각각의 consumer group이 마지막에 읽어간 레코드의 포인터
- consumer group은 동일한 그룹명을 사용하는 consumer들의 집합
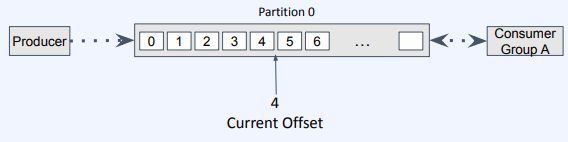
- Producer가 4번 메세지를 발행
- consumer가 메세지를 읽고 정상적으로 데이터 처리가 일어나면 consumer는 commit 메세지를 Kafka에 전달하고 Current Offset을 이동시킴
- consumer는 Current Offset 이후부터 데이터를 읽기 시작
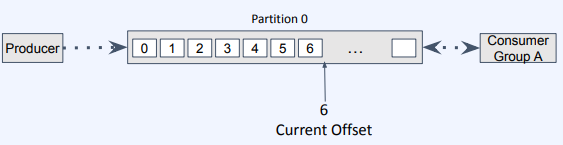
- Producer가 5번, 6번 메세지를 발행
- consumer는 Current Offset 이후인 5번부터 데이터를 읽기 시작
- 데이터를 6번까지 모두 읽은 후 Current Offset을 6으로 설정
- consumer는 Current Offset 이후인 5번부터 데이터를 읽기 시작
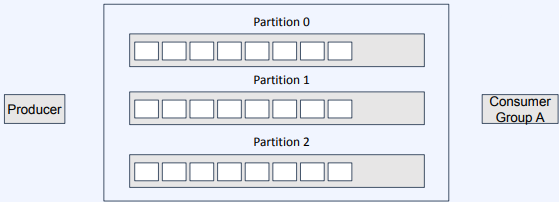
- 파티션을 여러개 만들게 되면 consumer group 내에 컨슈머 수를 증가시켜 병렬 처리 능력을 향상
- 특별한 경우가 아니면 파티션을 다수로 설정하여 처리량을 증가시켜줌
- 토픽이 여러개의 파티션으로 나뉘게 되면 프로듀서 외에 메세지 발행시 어떤 파티션에 기록할지 결정할 방법이 필요
- 발행 메세지 내에 key 값이 비어 있다면 메세지들은 모든 파티션에 라운드 로빈 방식으로 기록
- 하나의 파티션을 사용하면 init된 순서 그대로 순서가 보장
- 여러 파티션에 라운드 로빈 방식으로 메세지를 기록하면 순서가 보장되기 어려움
- 파티션의 순서를 보장하려면 파티션을 하나만 사용, 메세지 키 설정을 통해 동일한 파티션에 할당
- 단점 : 분산 병렬 처리의 이점이 줄어듬, 메세지 처리 코드의 복잡도가 증가, 메세지 재처리가 어려움
- 파티션의 순서를 보장하려면 파티션을 하나만 사용, 메세지 키 설정을 통해 동일한 파티션에 할당
- 발행 메세지 내에 key 값이 비어 있다면 메세지들은 모든 파티션에 라운드 로빈 방식으로 기록
출처 : fastcampus

코드를 거의 아트의 경지로 끌어올려서 내가 코드고 코드가 나인 물아일체의 경지