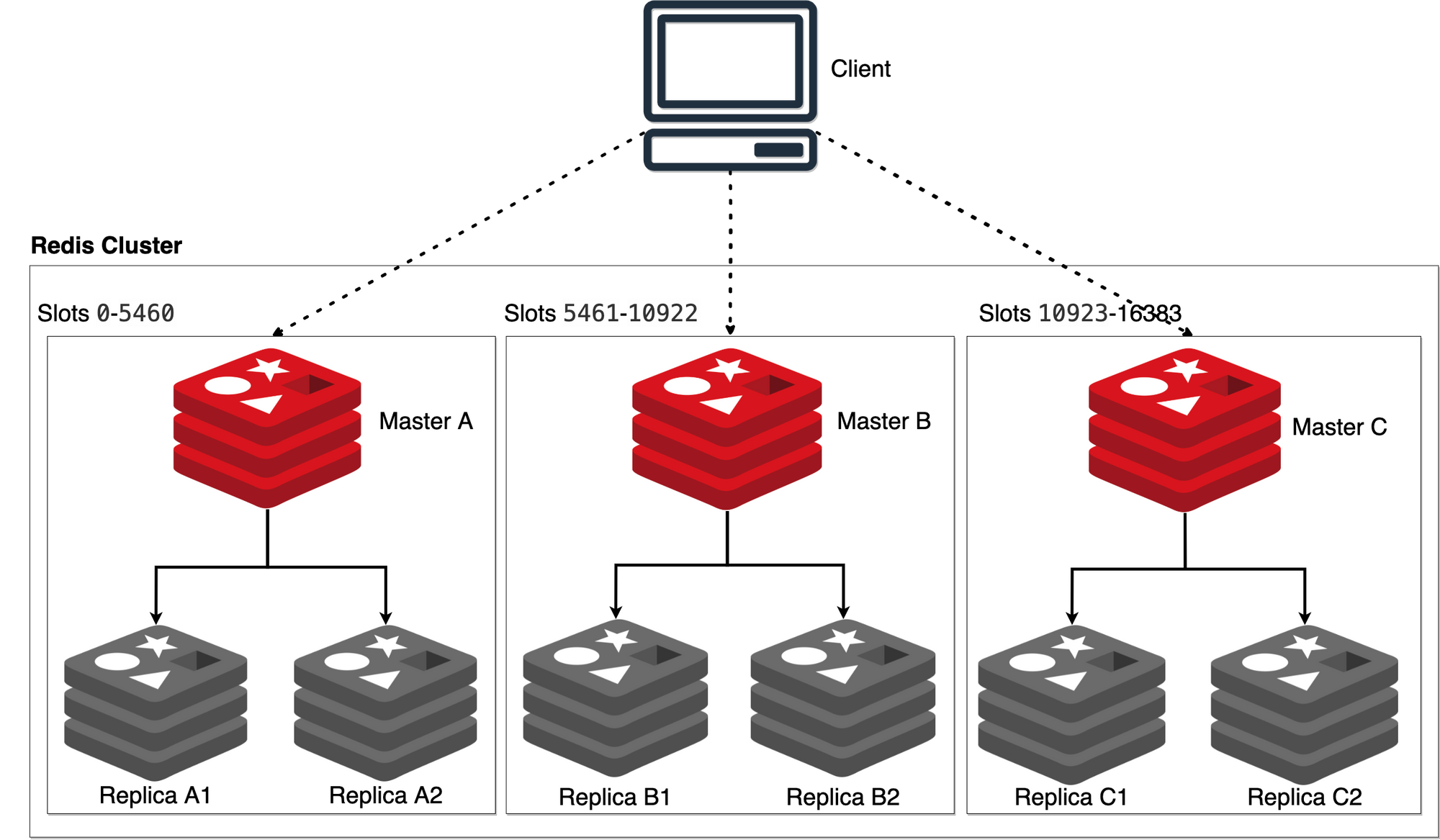
Redis Cluster란
- 여러 노드에 자동적인 데이터 분산
- 일부 노드의 실패나 통신 단절에도 계속 작동하는 가용성
- 고성능을 보장하면서 선형 확장성을 제공
- 분산과 확장성이 좋고 성능에 대한 보장을 해준다
Redis Cluster 특징
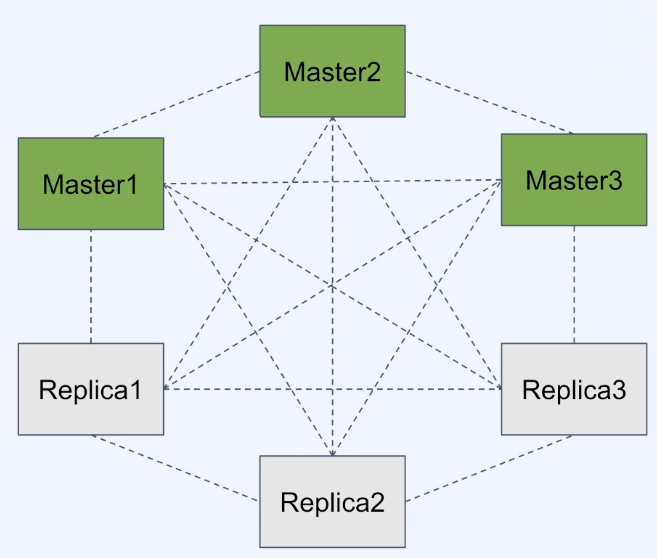
- full-mesh 구조로 통신
- cluster bus라는 추가 채널(port) 사용
- gossip protocol 사용
- 근처 노드만 통신
-> 전체 다 통신을 하게 되면 같은 통신, 같은 데이터를 중복으로 받기 때문
- 근처 노드만 통신
- hash slot을 사용한 키 관리
- DB0만 사용 가능
- multi key 명령어가 제한됨
- 클라이언트는 모든 노드에 접속
Sentinel과의 차이점
- 클러스터는 데이터 분산(샤딩)을 제공함
- 클러스터는 자동 장애조치를 위한 모니터링 노드(Sentinel)를 추가 배치할 필요가 없음
- 클러스터에서는 multi key 오퍼레이션이제한됨
- Sentinel은 비교적 단순하고 소규모의 시스템에서 HA(고가용성)가 필요할 때 채택
데이터 분산과 Key 관리
데이터를 분산하는 기준
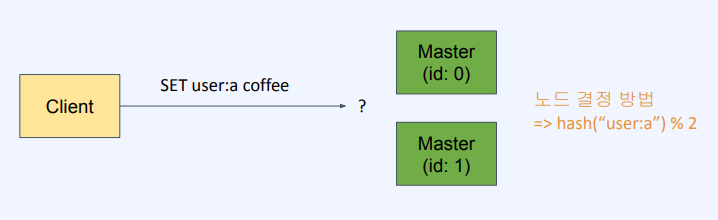
단순 해싱 예시
client 호출 -> set user a coffee -> 어떤 노드로 들어가야 하는지 'hash함수 % 2'를 통해 했음 ->
노드 하나 더 추가되면 'hash함수 % 3'으로 변경함과 동시에 기존에 데이터를 모아뒀던 노드의 값들도 재분배 해줘야함
- 특정 key의 데이터가 어느 노드(shard)에 속할 것인지 결정하는 메커니즘이 있어야 함
- 보통 분산 시스템에서 해싱이 사용됨
- 단순 해싱으로는 노드의 개수가 변할 때 모든 매핑이 새로 계산되어야 하는 문제가 있음
Hash Slot을 이용한 데이터 분산

- Redis는 16384개의 hash slot으로 key 공간을 나누어 관리
- 각 키는 CRC16 해싱 후 16384로 modulo 연산을 해 각 hash slot에 매핑
- hash slot은 각 노드들에게 나누어 분배됨
클라이언트의 데이터 접근
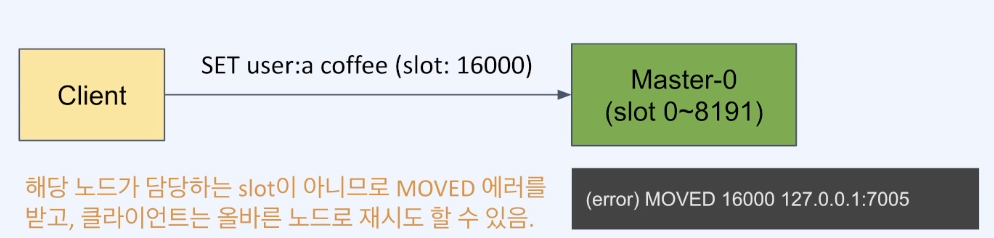
- 클러스터 노드는 요청이 온 key에 해당하는 노드로 자동 redirect를 해주지 않음
- 클라이언트는 MOVED 에러를 받으면 해당 노드로 다시 요청해야 함
성능과 가용성
클러스터를 사용할 때의 성능
- 클라이언트가 MOVED 에러에 대해 재요청을 해야 하는 문제
- 클라이언트(라이브러리)는 key-node 맵을 캐싱하므로 대부분의 경우 발생하지 않음
- 클라이언트는단일 인스턴스의 Redis를 이용할 때와 같은 성능으로 이용 가능
- 분산 시스템에서 성능은 데이터 일관성(consistency)과 trade-off가 있음
- Redis Cluster는 고성능의 확장성을 제공하면서 적절한 수준의 데이터 안정성과 가용성을 유지하는 것을 목표로 설계됨
클러스터의 데이터 일관성
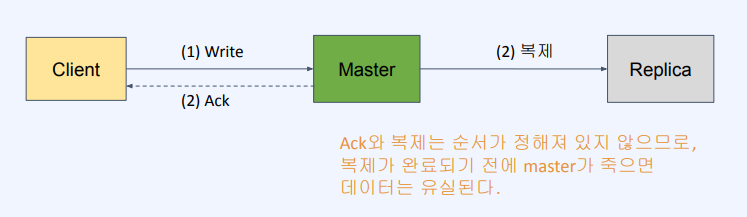
- Redis Cluster는 strong consistency를 제공하지 않음
- strong consistency : 한번 입력된 데이터가 100% 존재하는것, 다른 복제된 노드에서도 동일한 데이터를 볼 수 있는 것, 복제로 인한 단점이 하나도 없는 상태
- 일반적인 복제 시스템, 다중화 시스템에서는 strong consistency 보장하지 않음
-> strong consistency는 성능 저하가 심함
- 높은 성능을 위해 비동기 복제를 하기 때문
- (1)Write가 끝나면 (2)Ack 성공 신호를 보내면서 (2)복제를 함
- strong consistency 보장 -> (1)Write가 끝나고 (2)복제를 함 복제가 끝나고 (3)Ack를 보냄
클러스터의 가용성 - auto failover
ex) master1과 replica2가 죽더라도, 2/3의master가 남아있고, master1이 커버하던 hash slot은 replica1이 master로 승격되어 커버할 수 있다
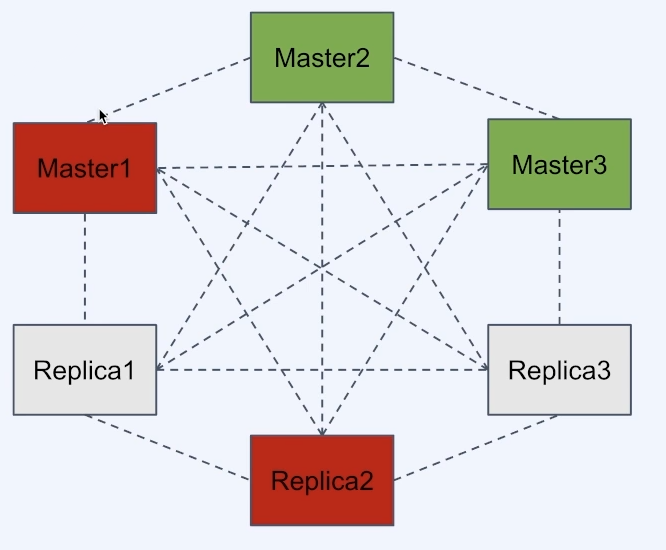
- 일부 노드(master)가 실패(또는 네트워크 단절)하더라도 과반수 이상의 master가 남아있고, 사라진 master의 replica들이 있다면 클러스터는 failover되어 가용한 상태가 된다
- node timeout동안 과반수의 master와 통신하지 못한 master는 스스로 error state로 빠지고 write 요청을 받지 않음
클러스터의 가용성 - replica migration
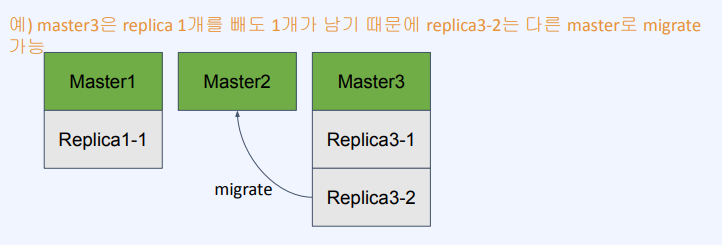
- replica가 다른 master로 migrate 해서 가용성을 높인다.
클러스터의 제약 사항
클러스터에서는 DB0만 사용 가능
- Redis는 한 인스턴스에 여러 데이터베이스를가질 수 있으며 디폴트는 16
- 설정) databases 16
- Multi DB는 용도별로 분리해서 관리를 용이하게 하기 위한 목적
- 클러스터에서는해당 기능을 사용할 수 없고 DB0으로 고정된다
Multi key operation 사용의 제약
- key들이 각각 다른 노드에 저장되므로 MSET과 같은 multi-key operation은 기본적으로 사용할 수 없다
- 여러 키값이 들어왔고 그 키들이 다른 노드에 속할 경우가 존재
-> 한 노드에서 커맨드를 완료 시킬 수 없음
- 여러 키값이 들어왔고 그 키들이 다른 노드에 속할 경우가 존재
- 같은 노드 안에 속한 key들에 대해서는 multi-key operation이 가능
- hash tags 기능을 사용하면 여러 key들을 같은 hash slot에 속하게 할 수 있음
- key 값 중 {} 안에 들어간 문자열에 대해서만 해싱을 수행하는 원리
ex)
Mset{user:a}:age 20 {user:a}:city seoul
클라이언트 구현의 강제
- 클라이언트는클러스터의 모든 노드에 접속해야 함
- 노드별 처리를 직접 해줘야함
- 클라이언트는 redirect 기능을 구현해야 함(MOVED 에러의 대응)
- 클라이언트 구현이 잘 된 라이브러리가없는 환경도 있을 수 있음
클러스터 설정 파일
- cluster-enabled {yes/no}
- 클러스터 모드로 실행할지 여부를 결정
- cluster-config-file {filename}
- 해당 노드의 클러스터를 유지하기 위한 설정을 저장하는 파일로, 사용자가 수정하지 않음
- cluster-node-timeout {milliseconds}
- 특정 노드가 정상이 아닌 것으로 판단하는 기준 시간
- 이 시간동안 감지되지 않는 master는 replica에 의해 failover가 이루어짐
-> write 요청을 받지않음
- cluster-replica-validity-factor {factor}
- master와 통신한지 오래된 replica가 failover를 수행하지 않게 하기 위한 설정
- (cluster-node-timeout factor)만큼 master와 통신이 없었던 replica는 failover 대상에서 제외
-> 계산식 ex) cluster-node-timeout (5초) factor (10초)
-> 50초 동안 마스터 노드와 통신이 없던 레플리카 노드는 마스터 노드로 승격할 수 없다
- cluster-migration-barrier {count}
- 한 master가 유지해야 하는 최소 replica의 개수
- 이 개수를 충족하는 선에서 일부 replica는 replica를 가지지 않은 master의 replica로 migrate될 수 있다
- cluster-require-full-coverage : {yes/no}
- 일부 hash slot이 커버되지 않을 때 write 요청을 받지 않을지 여부
- no로 설정하게 되면 일부 노드에 장애가 생겨 해당 hash slot이 정상 작동하지 않더라도 나머지 hash slot에 대해서는 작동하도록 할 수 있다
- cluster-allow-reads-when-down : {yes/no}
- 클러스터가 정상 상태가 아닐 때도 read 요청은 받도록 할지 여부
- 어플리케이션에서 read 동작의 consistency가 중요치 않은 경우에 yes로 설정할 수 있다
출처 : fastcampus

코드를 거의 아트의 경지로 끌어올려서 내가 코드고 코드가 나인 물아일체의 경지