
Intro
현재 회사에서는 MSA를 활용해 플랫폼을 만들고 있다. 그중 internal communication을 redis의 publish subscribe 기능을 활용하기로 하였다. 또한 서비스마다 각각 DB가 만들어지기 때문에 data sharing에도 함께 활용하기로 하였다. Redis를 활용하면 장점은 다음과 같다.
- 하나의 서비스에서 이벤트가 발생했고 여러 서비스에서 그 이벤트에 대한 반응이 이루어져야 할 때 각각의 서비스에서 비동기로 처리할 수 있다.
- data의 syncronize를 관리하기 용이하다.
- inmemory의 장점을 활용해 빠른 속도로 각각의 서비스에서 data sharing이 쉽다.
- Log data 관리가 쉽다
Redis를 처음 보는사람은 이게 무슨 말인지 하나도 이해가 가지 않을 것 이다. 나 또한 Redis에 익숙하지 않은 사람으로써 함께 익숙해지길 바라며 포스팅을 진행한다.
what is redis?
Redis는 data를 memory에 저장하는(inmemory base) key value 구조의 캐시 시스템이라고 보면 된다. 이걸 왜 사용하냐면 DB(디스크)에 접근하는건 매우 cost가 크다는 사실은 운영체제시간에 열심히 졸은 나도 아는 상식이다. 하지만 메모리에 접근하는건 굉장히 빠르다. redis는 메모리에 상주하는 아주 작은 데이터베이스라고 생각하면 된다. 하지만 field와 value의 형식을 선언해야하는 저장해야하는 RDS와는 반대로 테이블 선언 없이 사용할 수 있으므로 NoSQL이라고도 불리는 저장소이다.
아까 key value 구조라고 했는데 value의 생김새에 따라 활용과 시간복잡도가 천차만별로 차이가 난다. redis를 도입 할 예정이라면 redis 홈페이지의 data structure 설명을 꼭 정독해보길 추천한다.
redis data structure
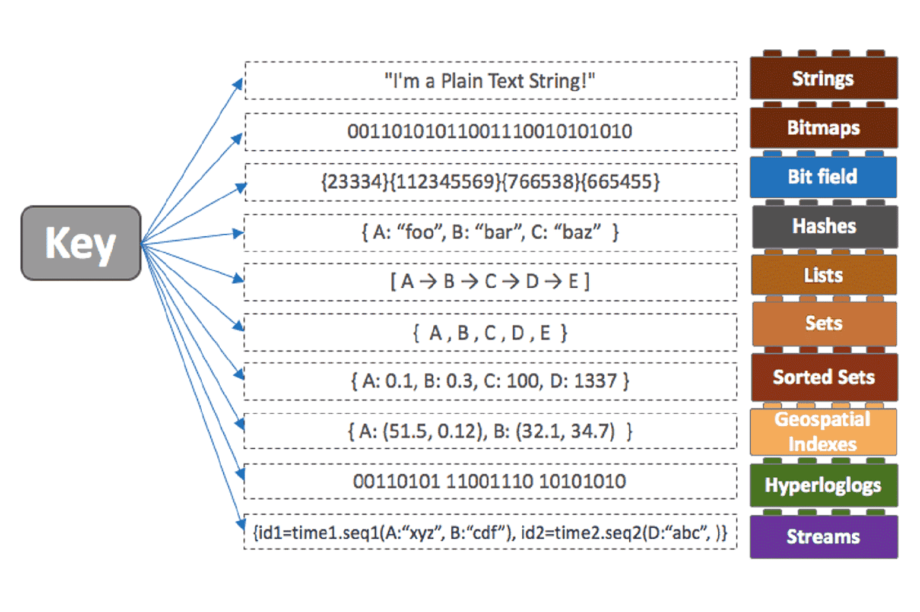
위의 사진을 보면 아주 다양한 자료구조가 있다는걸 알 수 있다. 우리는 data sharing에는 Hashes를 사용할거고 Publish 기능을 활용할때는 Streams를 사용 할 것이다. (원래 redis의 pub/sub은 Streams와 크게 상관이 없지만 Streams를 사용해 message queue 형태의 publish subscribe 구조를 구현할 수 있다. 지금은 몰라도 됨..)
Stream
stream이란 Bit stream, data stream 등등, 시간이 지남에 따라 데이터가 계속 이어져 들어오는 현상을 생각해 볼 수 있다. 무한 수열과 급수를 컴퓨터로 표현한것과 비슷하다. 우리에게는 로그데이터를 생각하면 Stream이 어떤 느낌인지 알 수 있다.
Redis streams는 Redis 5.0부터 로그 파일을 모델링 하는 새로운 데이터 구조로 도입되었다.
Do it!
$ brew install redis # 설치
$ brew services start redis # redis 실행
$ redis-cli # CLI 실행데이터 추가: XADD
XADD key ID field value [field2 value2 ... ]
XADD customer * id 1234
여기서 ID 부분이 중요한데 ID는 다음과 같다
< milliseconds time > - < sequence number >
현재 시간의 timestamp 숫자와 같은 시간내에 여러개의 데이터가 올 수 있기 때문에 numbering이 되어있다.
*(astrict)는 자동으로 아이디를 부여하겠다는 뜻이고 ID를 직접 선언할 수도 있다.
>>> 127.0.0.1:6379> XADD customer * id "asdfdasf"
>>> "1647231099585-0"
>>> 127.0.0.1:6379> XADD customer * id "asdfdasf"
>>> "1647231112587-0"
>>> 127.0.0.1:6379> xlen customer
>>> (integer) 2데이터 읽기: XREAD
XREAD [COUNT count][BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]
XREAD block 5000 STREAMS customer $
$는 다양한 뜻이 있다. jsonpath 구문을 사용한다는 뜻으로도 쓰이고 $123 은 123bytes를 사용했다는 뜻으로 쓰이기도 하고 여기서는 새로 생긴 streams data만 받겠다는 뜻이다.
원래는 XREAD block 5000 STREAMS customer 1526999644174-3 이런식으로 ID를 적도록 되어있지만 굉장히 보기 안좋다. 그래서 $를 쓰면 이후로부터 생기는 데이터라는 뜻으로 약속했다.
[현재 터미널]
>>> 127.0.0.1:6379> xread block 5000 streams customer $
[다른 터미널]
>>> 127.0.0.1:6379> xadd customer * id 124
>>> "1647231396280-0"
[다시 현재 터미널]
>>> 1) 1) "customer"
>>> 2) 1) 1) "1647231396280-0"
>>> 2) 1) "id"
>>> 2) "124"데이터 삭제: XDEL
XDEL key ID
XDEL customer 1647231396280-0
>>> 127.0.0.1:6379> xdel customer 1647231396280-0
>>> (integer) 1데이터 여러개 삭제 : XTRIM
XTRIM key MAXLEN [~] count
XTRIM customer MAXLEN 10
데이터를 지우는동안 ADD나 READ를 할 수 없다. 그러므로 삭제는 최대한 신속하게 해야하므로 짧은 시간내에 삭제할 수 있는 명령어다. 위는 10개를 남기고 다 지우라는 뜻이다.
시간복잡도
-
XADD : O(log(N))
-
XREAD: O(log(N))
-
XDEL: O(log(N))
-
XTRIM: O(log(N))
Outro
어차피 redis를 terminal에서 활용할게 아니고 나는 fastapi 프레임워크 안에서 사용할거라 python의 redis library를 더 잘 활용하면 장땡이다. 그러나 SQL을 모르고 ORM을 활용할 수 없듯이 원래 어떻게 설계된 구조인지를 아는건 중요하다. 이번 포스트에서는 Redis와 Stream에 대해 알아보았고 다음 포스트에서는 Python에서 Redis를 다뤄보고 시간이 된다면 Publish Subscribe도 다뤄보도록 하겠다!!
