
14.1 sed 명령어: 스트림 에디터
-
Steram Editor : sed. 비대화형 에디터이다.
-
대화형 에디터인 notepad나 vim과는 다르다.
- 대화형 에디터 : 파일을 열러 메모리 상에서 편집하고 적절한 시점에 저장
- 비대화형 에디터 :
- 셸에서 편집 내용을 인자로 지정하여 sed 명령어 실행
- sed가 편집을 수행
- 편집이 완료된 내용을 표준 출력으로 출력
- 필터 명령어이다.
- 정규 표현식 사용이 가능하다.
- 문자열 치환 등 편집 명령어를 사용할 수 있다.
- sed는 편집 내용을 출력만 하고 원래 파일의 내용을 바꾸지 않는다.
-
사용법 :
sed [옵션] <스크립트> <대상 파일>-
스크립트 : 주소와 명령어를 조합한 문자열.
-
주소를 지정하지 않으면 입력으로 들어오는 모든 행에 대해 명령어가 실행된다.
-
삭제
-
sed 1,5d sample.txt: 1번부터 5행까지 삭제한다.1,5: 주소
-
sed '3,$d' sample.txt: 3행부터 마지막 행까지 삭제.$를 셸이 해석하지 않도록 따옴표로 감싼다. -
sed d sample.txt: 주소를 지정하지 않으면, 명령어가 모든 행에 적용된다. 모든 행이 지워진다. -
주소에는 행 뿐 아니라 정규 표현식을 사용할 수 있다.
-
sed /^B/d test.txt: B로 시작하는 행을 삭제./^B/: 주소d: 명령어
행 출력
-
sed 1p test.txt: 1행을 출력하라고 지정했지만 모든 행이 출력된다.-
첫 번째 행이 두번 출력되고 파일 모든 내용이 출력됨.
-
sed는 한 행을 읽어 패턴 스페이스라는 장소에 복사하고 편집 명령어를 실행한 뒤 패턴 스페이스의 내용을 출력한다.
-
첫 번째 행은 스크립트로 출력된 것이고, 두 번째부터 마지막은 패턴 스페이스의 내용이 출력된 것이다.
-
한 행을 읽어 패턴 스페이스에 복사하고,
1p명령어를 실행한다. -> Ber
패턴 스페이스를 출력한다. -> Ber (두번 출력)
그리고 다음 행을 읽고 패턴 스페이스에 복사한다.
패턴 스페이스를 출력한다. -> Beer
그리고 다음 행을 읽고 패턴 스페이스에 복사한다.
-
-
sed -n 1p test.txt: 첫 번째 행만 출력한다. 패턴 스페이스 출력하지 않음. -
-n: 패턴 스페이스의 내용을 출력하지 않는다.
치환
-
사용법 :
's/치환 전 문자열/치환 후 문자열/옵션'- 작은 따옴표로 감싸는 것이 좋다.
-
sed 's/Beer/Whisky/' test.txt: Beer을 Whisky로 치환한다. 주소를 생략했으므로 모든 행에 적용된다. -
각 행에서 처음 발견한 문자열만 치환한다.
-
sed 's/Beer/Whisky/g' test.txt: Beer을 whisky로 모든 행 전체에 적용한다.g: 모든 문자열 치환하는 옵션
-
치환 전 문자에 정규 표현식 적용
-
sed 's/B.*r/Whisky/g' test.txt: B.로 시작하고 r로 끝나는 문자열을 Whisky로 치환한다. 모든 행 전체에 적용된다. 정규 표현식 사용 시 따옴표를 사용한다. -
sed 's/B.*r//g' test.txt: 치환 후 문자열을 비우면 해당 문자열을 지울 수 있다. -
sed -n 's/!/?/gp:-n옵션을 붙이면 치환한 행만 출력할 수 있다. p로 행 출력을 할 수 있다. -
sed -r: 확장 정규 표현식 적용 -
sed -r 's/Be+r/Whisky/' test.txt: Beer, Beeer...을 whisky로 치환한다. -
GNU sed에서는
-r옵션을 사용하지 않고\+,\?로 사용할 수 있다. -
후방 참조 : 정규 표현식에서 ()를 사용하여 그룹화한 뒤 \1 같이 참조하는 것
-
검색된 문자열의 일부를 치환하는 경우 후방 참조를 사용한다.
-
기본 정규 표현식에서 : \로 그룹화하여 \1로 참조
-
확장 정규 표현식에서 : ()로 그룹화하여 \1로 참조
-
sed 's/My \(.*\) / --\1-- / ' test.txt:My \(.*\)을--\1--로 치환한다.- ()는 확장이므로
\를 붙여야 한다. 기본에서()를 사용하려면\를 붙여야 한다! My \(.*\): My 뒤에 오는 어떠한 문자열 모두()를--\1--로 바꾼다.
-
-
sed '1,3s/Beer/Whisky/g' test.txt: 1행 ~ 3행 사이에 적용한다. 모든 Beer을 Whisky로 변경한다. 주소를 지정하여 치환한다. -
s 다음에 오는 문자가 구분자이다.
-
sed 's!Beer!/Beer/!g': 구분자를 !로 지정하여Beer을/Beer/로 치환한다. g 옵션으로 전체 행에서 치환한다.
14.2 awk 명령어: 패턴 검색 및 처리 언어
-
awk : 패턴 검색 및 처리 언어
-
텍스트 검색, 추출, 가공과 같은 편집 작업을 위한 명령어.
-
sed는 비대화형 에디터인 반면 awk는 고도의 기능을 제공한다.
-
-
사용법 :
awk <스크립트> <대상파일> -
대상 파일을 지정하지 않으면 표준 입력을 읽고, 입력 텍스트를 한 행씩 읽어서 처리한다.
-
패턴 {액션}으로 구성된다. -
awk ‘{print $2, $3}’ score.txt: 2번째 필드와 3번째 필드만 출력해라.-
패턴 : 액션을 실행할 지 여부를 결정하는 조건을 기술한다.
-
awk는 대상 텍스트의 행마다 이 조건에 부합하는지를 확인한다.
-
한 행을 레코드라고 부른다.
-
패턴이 일치할 때만 액션이 실행된다.
-
패턴이 생략되면 모든 레코드에 대해 액션이 실행된다.
-
한 줄씩 읽어서
{}를 실행해라. -
$2 $3 으로 하면 필드값 사이에 공백이 없는데, $2, $3 으로 하면 공백 있게 출력된다.
-
-
awk '$1 ~/^s/ {print NR, $0}' score.txt-
패턴 : 1번 필드가 /^s/에 부합하면 액션:행 번호, 필드를 출력 해라.
-
^: 필드1이 s로 시작되면 출력하라는 의미이다. 정규 표현식이므로 /로 감싼다. -
NR: 행 번호를 의미한다. number of record이다. -
$0: 행 전체. 레코드를 의미한다.2 straw 23
3 strawberry 72
이렇게 출력된다.
-
v ~p: 필드v가 패턴p에 부합되면 참 -
v !~p: 필드v가 패턴 p에 부합되지 않으면 참
-
-
awk '$2 !~ /^m/ {print NR, $0}' test.txt: 2번필드가 m으로 시작하는것이 아니면 출력한다.
-
ls -l /usr/bin | awk '{print $5, $9}':ls -l /usr/bin의 결과를 파이프로 넘긴다.awk 패턴 {액션}패턴이 없으므로 모든 레코드에 대해 액션을 취한다.
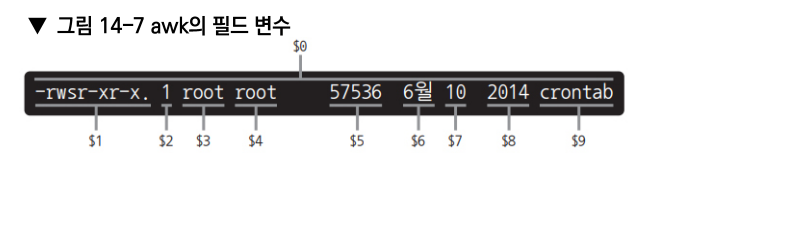
모든 레코드에 대해 5번 필드와 9번 필드를 출력하라.$5, $9: 필드 변수
-
공백이나 탭을 구분자로 필드를 분할한다. 공백이 이어지면 하나로 간주하므로 공백이 불규칙해도 문제없다.
-
NF: 레코드의 필드 개수를 담고 있는 변수이다. number of field-
drwxr-xr-x 1 eldeo eldeo 197612 9월 25 2023 bin/ -
NF에 9가 담겨 있다.
-
$9 와 $NF가 같다.
-
$(NF-1): 8번째 필드2023 -
$(NF-2): 7번째 필드25
-
-
ls -l /usr/bin | awk ‘{print $(NF-1), $NF}’: 8번째 필드 9번째 필드 출력한다. $(NF-1) 로 8번째 필드에 접근한다. -
$NF-1 하면 안된다.
-
정규 표현식을
/로 감싸야 한다. -
awk ‘$9 ~ /^cp/ {print $5, $9}’:패턴 {액션}9번째 필드가 cp로 시작하면, 5번 필드와 9번 필드를 출력하라. -
ls -l /usr/bin | awk '/^l/ {print $5, $9}': l로 시작하는 행만 5번필드, 9번필드를 출력한다. -
$9 ~/^cp/: 액션 생략 -
$9 ~/^cp/ {print} -
$9 ~/^cp/ {print $0}
모두 동일하다. -
awk - F: 필드 구분자 지정 옵션-
awk -F, ‘{print $1,$2,$3}’ score.csv: 필드 구분자를 ,로 지정한다. -
awk -F, ‘{sum += $NF} END{print sum}’ score.csv: 필드 구분자를 , 로 지정하고, sum 변수에 $NF:마지막 필드 값을 모두 더하고 출력한다. -
sum 변수에 $NF 마지막 필드 값을 모두 더하고 출력한다.
-
END안에 있는 액션은 모든 입력 파일에 대한 처리가 끝난 뒤 마지막에 한 번 실행한다. -
NR: Number of Record 변수. 지금까지 읽은 레코드의 수가 담겨 있어 end블록이 실행될 때는 파일의 총 행수가 된다.
-
평균 출력하기
-
awk -F, ‘{sum += $NF} END{print “Average : ”,sum}’ score.csv
구분자를,로 지정하고,
sum 변수에 마지막 필드 변수를 모두 더하고
마지막에 print 실행한다. -
Average : 31.1667
-
이렇게 만든 awk스크립트를 파일로 저장하면 나중에 불러 쓸 수 있다.
-
average.awk파일에{sum += $NF} END{print “Average : ”,sum}
를 입력하고 -
cat average.awk
{sum += $NF} END{print "Average: ", sum/NR}
NR : 지금까지 읽은 총 행수가 저장되어있음. -
awk -F, -f average.awk score.csv
를 통해-f옵션으로 average.awk를 지정하여 실행한다. -
Average : 31.1667
을 똑같이 출력할 수 있다.
-
