
문제 설명
파일명 정렬
세 차례의 코딩 테스트와 두 차례의 면접이라는 기나긴 블라인드 공채를 무사히 통과해 카카오에 입사한 무지는 파일 저장소 서버 관리를 맡게 되었다.
저장소 서버에는 프로그램의 과거 버전을 모두 담고 있어, 이름 순으로 정렬된 파일 목록은 보기가 불편했다. 파일을 이름 순으로 정렬하면 나중에 만들어진 ver-10.zip이 ver-9.zip보다 먼저 표시되기 때문이다.
버전 번호 외에도 숫자가 포함된 파일 목록은 여러 면에서 관리하기 불편했다. 예컨대 파일 목록이 ["img12.png", "img10.png", "img2.png", "img1.png"]일 경우, 일반적인 정렬은 ["img1.png", "img10.png", "img12.png", "img2.png"] 순이 되지만, 숫자 순으로 정렬된 ["img1.png", "img2.png", "img10.png", img12.png"] 순이 훨씬 자연스럽다.
무지는 단순한 문자 코드 순이 아닌, 파일명에 포함된 숫자를 반영한 정렬 기능을 저장소 관리 프로그램에 구현하기로 했다.
소스 파일 저장소에 저장된 파일명은 100 글자 이내로, 영문 대소문자, 숫자, 공백(" "), 마침표("."), 빼기 부호("-")만으로 이루어져 있다. 파일명은 영문자로 시작하며, 숫자를 하나 이상 포함하고 있다.
파일명은 크게 HEAD, NUMBER, TAIL의 세 부분으로 구성된다.
HEAD는 숫자가 아닌 문자로 이루어져 있으며, 최소한 한 글자 이상이다.
NUMBER는 한 글자에서 최대 다섯 글자 사이의 연속된 숫자로 이루어져 있으며, 앞쪽에 0이 올 수 있다. 0부터 99999 사이의 숫자로, 00000이나 0101 등도 가능하다.
TAIL은 그 나머지 부분으로, 여기에는 숫자가 다시 나타날 수도 있으며, 아무 글자도 없을 수 있다.
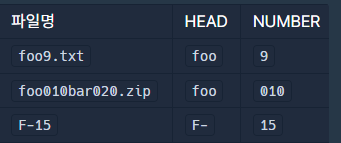
파일명을 세 부분으로 나눈 후, 다음 기준에 따라 파일명을 정렬한다.
파일명은 우선 HEAD 부분을 기준으로 사전 순으로 정렬한다. 이때, 문자열 비교 시 대소문자 구분을 하지 않는다. MUZI와 muzi, MuZi는 정렬 시에 같은 순서로 취급된다.
파일명의 HEAD 부분이 대소문자 차이 외에는 같을 경우, NUMBER의 숫자 순으로 정렬한다. 9 < 10 < 0011 < 012 < 13 < 014 순으로 정렬된다. 숫자 앞의 0은 무시되며, 012와 12는 정렬 시에 같은 같은 값으로 처리된다.
두 파일의 HEAD 부분과, NUMBER의 숫자도 같을 경우, 원래 입력에 주어진 순서를 유지한다. MUZI01.zip과 muzi1.png가 입력으로 들어오면, 정렬 후에도 입력 시 주어진 두 파일의 순서가 바뀌어서는 안 된다.
무지를 도와 파일명 정렬 프로그램을 구현하라.
입력 형식
입력으로 배열 files가 주어진다.
files는 1000 개 이하의 파일명을 포함하는 문자열 배열이다.
각 파일명은 100 글자 이하 길이로, 영문 대소문자, 숫자, 공백(" "), 마침표("."), 빼기 부호("-")만으로 이루어져 있다. 파일명은 영문자로 시작하며, 숫자를 하나 이상 포함하고 있다.
중복된 파일명은 없으나, 대소문자나 숫자 앞부분의 0 차이가 있는 경우는 함께 주어질 수 있다. (muzi1.txt, MUZI1.txt, muzi001.txt, muzi1.TXT는 함께 입력으로 주어질 수 있다.)
출력 형식
위 기준에 따라 정렬된 배열을 출력한다.
입출력 예제
입력: ["img12.png", "img10.png", "img02.png", "img1.png", "IMG01.GIF", "img2.JPG"]
출력: ["img1.png", "IMG01.GIF", "img02.png", "img2.JPG", "img10.png", "img12.png"]
입력: ["F-5 Freedom Fighter", "B-50 Superfortress", "A-10 Thunderbolt II", "F-14 Tomcat"]
출력: ["A-10 Thunderbolt II", "B-50 Superfortress", "F-5 Freedom Fighter", "F-14 Tomcat"]
function solution(files) {
return files.sort((a, b) => {
const regExp = /(\D+)(\d{1,5})(.*)/;
const [aHead, aNumber, aTail] = a.match(regExp).slice(1);
const [bHead, bNumber, bTail] = b.match(regExp).slice(1);
const compareHead = aHead.toLowerCase().localeCompare(bHead.toLowerCase());
const compareNumber = parseInt(aNumber, 10) - parseInt(bNumber, 10);
return compareHead === 0 ? compareNumber : compareHead;
});
}
너무 어려워서 지피티랑 같이 풀었고요 쉬운 문제만 골라 풀었더니 Lv2라도 어려운 문제만 남아서 요즘 고생을 하고있습니다. 골고루 풀어야겠네요.
regExp는 정규 표현식(Regular Expression)의 줄임말입니다. 지피티가 정해준 변수명이 뭐의 약자인지 몰라서 다시 물어봤네요
- (\D+): 숫자가 아닌 문자 1개 이상을 나타냅니다. HEAD 부분을 의미합니다.
- (\d{1,5}): 숫자 1~5개를 나타냅니다. NUMBER 부분을 의미합니다. {1,5}는 1에서 5개까지의 숫자를 나타내며, 최대 5자리의 숫자를 허용합니다.
- (.*): 숫자와 문자 이외의 모든 것을 나타냅니다. TAIL 부분을 의미합니다.
코드 5번째 줄까지를 예시를 들어 설명하면,
a.match(regExp): 문자열 "img12.png"을 정규 표현식 regExp와 매칭시킵니다. 이 정규 표현식은 HEAD, NUMBER, TAIL로 구분합니다. 따라서 매칭된 결과는 ["img12.png", "img", "12", ".png"] 형태의 배열이 됩니다.
.slice(1): match() 함수에 의해 반환된 배열에서 인덱스 1부터 끝까지의 부분을 추출합니다. 즉, ["img", "12", ".png"] 배열이 됩니다.
const [aHead, aNumber, aTail] = a.match(regExp).slice(1);: 위의 세 과정을 조합하여 실행하면, aHead 변수에는 "img", aNumber 변수에는 "12", aTail 변수에는 ".png"가 각각 할당됩니다.
몰라서 지피티랑 푼 거 치고는 이 부분은 간단했네요
사실 문제를 풀 때 아무리 어려운 문제라도 답을 보면 갑자기 쉬워 보입니다.
그리고 처음 써 본 localeCompare()함수.
..누구세요?
localeCompare() 함수는 문자열을 비교하여 정렬 순서를 결정하는 메서드입니다. 이 메서드는 주어진 문자열과 비교 대상 문자열을 비교하여 두 문자열의 상대적인 위치를 결정하고, 결과에 따라 음수, 양수, 또는 0을 반환합니다.
구체적으로 설명하면:
만약 비교 대상 문자열이 주어진 문자열보다 앞에 오는 경우, 음수(-1)를 반환합니다.
만약 비교 대상 문자열이 주어진 문자열보다 뒤에 오는 경우, 양수(1)를 반환합니다.
만약 두 문자열이 동일한 경우, 0을 반환합니다.
이 함수는 주로 문자열을 사전식으로 비교할 때 사용됩니다. 즉, 문자열을 알파벳 순서대로 정렬하거나 비교할 때 유용합니다. 이 함수는 주어진 문자열을 기준으로 대소문자를 구분하지 않고 비교할 수 있습니다. 따라서 "a"와 "A"는 동일한 것으로 간주됩니다.
const result = "apple".localeCompare("banana");
console.log(result); // -1
의 코드에서 "apple"이 "banana"보다 앞에 위치하므로, -1이 반환됩니다.
그리고 8번째 줄 코드,
파일1: "img01.jpg"
파일2: "img10.jpg"
여기서 NUMBER 부분은 "01"과 "10"입니다. 이를 정수로 변환하면 각각 1과 10이 됩니다.
그런데 우리가 숫자순으로 정렬하기 위해서는 숫자를 비교해야 합니다. 여기서 "01"은 "10"보다 작은 숫자지만, 문자열로 비교하면 "01"이 "10"보다 더 크게 됩니다. 왜냐하면 문자열을 비교할 때 첫 번째 문자부터 차례대로 비교하기 때문입니다.
따라서 우리는 숫자로 변환한 후에 비교해야 합니다. 하지만 숫자로 변환한 경우에도 "01"은 1, "10"은 10이 되기 때문에, 문자열 비교와 마찬가지로 "01"이 "10"보다 작은 값을 갖습니다. 따라서 "01"을 "10"보다 앞에 위치시키기 위해서는 1에서 10을 뺀 결과를 사용해야 합니다.
이것이 음수와 양수를 나누어 사용하는 이유입니다. 음수일 경우는 파일1이 파일2보다 작은 것으로 간주하고, 양수일 경우는 파일1이 파일2보다 큰 것으로 간주합니다. 0일 경우는 두 숫자가 같은 경우입니다. 이렇게 함으로써 숫자순으로 파일명을 정렬할 수 있습니다.
막줄 코드,
위 코드에서 compareHead는 파일명의 HEAD 부분을 비교한 결과를 담고 있고, compareNumber는 파일명의 NUMBER 부분을 비교한 결과를 담고 있습니다.
compareHead === 0 ? compareNumber : compareHead 부분은 삼항 연산자를 사용하여, 먼저 HEAD 부분을 비교하고, 만약 HEAD 부분이 같다면 NUMBER 부분을 비교하고, 그렇지 않으면 HEAD 부분의 비교 결과를 반환합니다.
