
Original paper:
Jiang, Wei. "A nonparametric test of market timing." Journal of Empirical Finance 10.4 (2003): 399-425.
동기
지금까지 나는 시점선택 관련 연구에 대해선 항상 henriksson-merton market timing model만 이용해 테스트해왔다. HM model는 옵션 프리미엄이 없는 가상의 시장 옵션의 수익률을 시장 수익률과 함께 독립변수로 사용하여 시간에 따라 시장 위험 노출도를 얼마나 능숙하게 조작했는지를 테스트하는 모형이다.
문제점은, HM model은 선형회귀모형이다. 즉, 다중공선성이 발생하는 상황에선 제대로 사용할 수가 없다. 예를 들면...아래와 같은 상황 말이다.
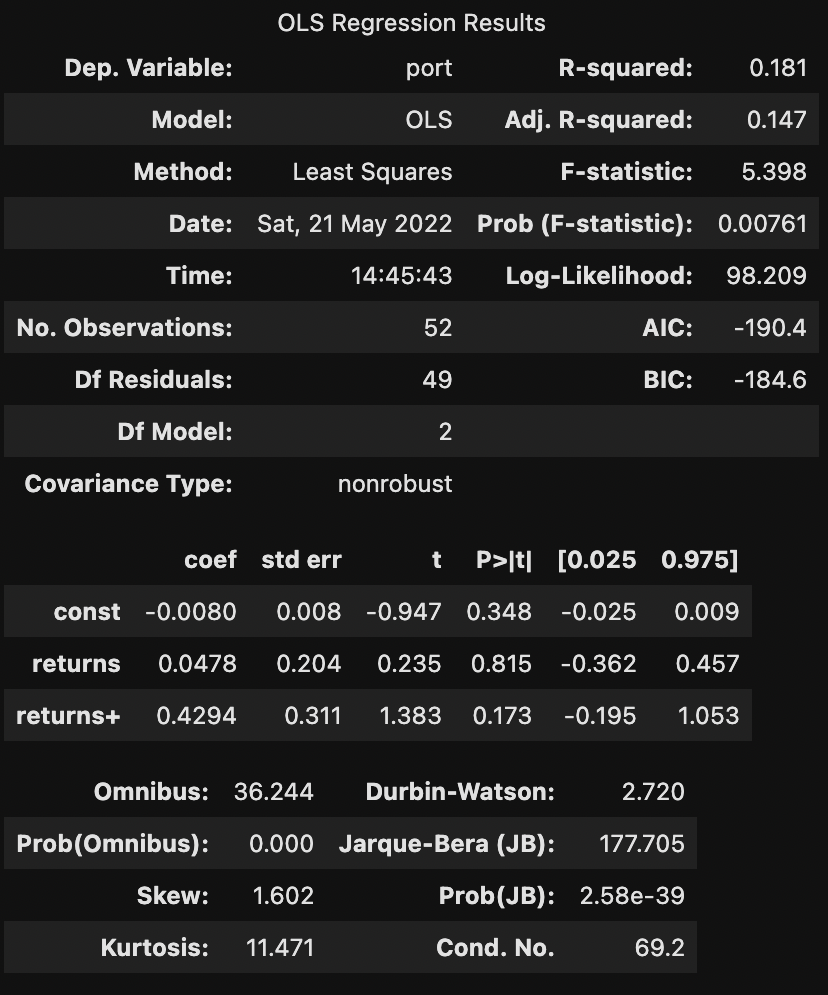
위의 표를 보면, F-statistic은 0.01의 유의수준에서 통계적으로 유의하지만 그 어떤 회귀계수도 0.01 수준에서 유의하지 않다.
데이터를 찬찬히 뜯어본 결과, 주가 노이즈가 많이 정제된 월별 수익률로 테스트를 하였고, 테스트 구간이 주가의 상승폭이 매우 높았던 2018-2021년 구간이었기 때문이라고 결론지었다.
먼저, 금융시장은 일반적으론 시간 단위가 짧아질수록 노이즈가 심해지기 때문에 상승/하락 확률이 반반으로 수렴한다. 반대로, 시간 단위가 길어질수록 모멘텀처럼 패턴을 띄기 시작하는 경우가 있다. 그리고 특히 2020년 주가 폭등 같은 사건이 끼어있다 보니, 가상의 옵션 수익률이 시장 수익률을 설명하는 수준이 과도하게 높게 된 것이다.
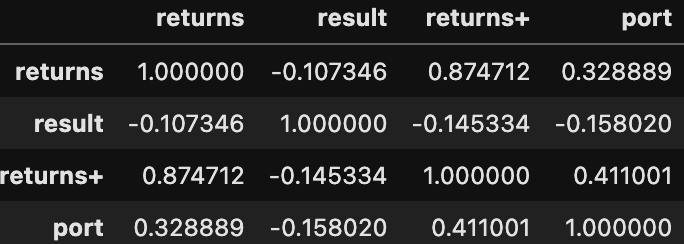
보면 returns+와 returns, 즉 가상 옵션 수익률과 시장 수익률의 상관계수가 0.87에 육박하는 걸 볼 수 있다. 이런 상태로는 회귀계수의 표준오차가 너무 커져 시점선택이 제대로 되었는지를 확인할 수가 없다.
선택 모형: Wei Jiang의 비모수 시점선택 모형
Jiang의 시점선택 검정에 쓰이는 개념이자 모수인 는 아래와 같이 계산한다.
여기서 는 벤치마크 지수를 가지는 포트폴리오의 k 시점에서의 투자 수익률, 는 벤치마크 지수의 k 시점에서의 투자 수익률이다. 여기서 반드시 를 만족해야 한다. 는 가 일어나는 빈도적 확률이다. 해당 조건들과 기호 설명을 통해 위의 식을 그대로 해석하면, 더 높은 시장 수익이 발생하는 구간 에서는 보다 CAPM에서의 시장위험 노출도인 , 즉 포트폴리오 수익률 차와 시장 수익률 차의 비율이 더 커질 때 포트폴리오 매니저가 더 시점선택을 잘한다는 해석을 하게 된다. 이는 과거 선행연구들의 모형 가정사항과 일치한다.
어찌되었건 이렇게 확률을 계산하면, null-hypothesis의 기준이 되는 값인 에서 몇 sigma가 벗어났는지를 측정하면 통계적으로 유의한 시점선택을 하였는지를 간단하게 테스트할 수 있게 된다. 이 이유는 의 통계량인 는 U-statistic이라고 부르는 통계량으로, 충분히 큰 또는 충분히 큰 수익률 데이터 관측수만 있으면 모수인 와의 차이가 일정한 표준오차의 배인 표준편차를 가지는 정규분포를 따르게 되기 때문이다. 이미 수리통계적인 모형이 있으므로 계산법 또한 직관적으로 와닿기는 하지만, 정확한 정리를 위해 의 공식도 여기 적어둔다.
여기서, 논문에선 sign이라는 함수를 함수처럼 기술해 놨는데, 아무래도 컴퓨터 과학자들이 True값을 1로 취급하고 False값을 0으로 취급하는 취지에서 이렇게 적어놓은 듯 싶다. 비전공자를 매우 혼란스럽게 만드는 표기법이긴 하다만, 직관적인 이해와 연결지어 해석하면 이해하기 쉽다(안의 명제가 참이면 1, 거짓이면 0을 내놓는 함수).
마지막으로, 테스트를 위한 표준오차(standard error, SE) 또한 정리해야겠다. 그걸 위해선 커널 함수를 하나 정의해야 한다.
논문 저자가 제대로 된 설명없이 공식만 휘갈겨놔서이 공식도 매우 혼란스럽긴 하다. 이 글을 쓰기 위해서 전체적으로 테스트를 해본 결과, 아무래도 bar의 뒷부분, 즉 전제가 옳지 않으면 전체도 옳지 않다고 판단해야 할 성 싶다.
여기서 는 단순히 동일 기간의 포트폴리오 수익률과 시장 수익률의 튜플이다.
위 식을 정의했으면, 표준오차는 아래와 같다.
적용
자, 이제 위의 내용을 정리하여 아래에 적용시켜보자.
먼저, 워크플로를 짤 필요가 있겠다.
- statistical test function 정의 및 큰 틀 짜기
- estimate 계산식 정의
- 커널 함수 정의
- standard error 계산식 정의
- test function 완성
test function 정의
from scipy.stats import norm
def nonParaMT(bench, port):
esti = estimation(bench, port)
se = stanardE(bench, port, esti)
statistic = esti * np.sqrt(len(bench)) /se
pVal = 1 - norm.cdf(statistic, loc=0, scale=1)
return esti, se , statistic, pValestimate 계산식 정의
from itertools import combinations as c
def estimation(bench, port):
n0 = 0
n = 0
for t1, t2, t3 in c(range(len(bench)), 3):
n0 += 1
rms = bench.iloc[[t1, t2, t3]].sort_values()
trueT1, trueT2, trueT3 = rms.index
betaH = (port.loc[trueT3] - port.loc[trueT2]) / (bench.loc[trueT3] - bench.loc[trueT2])
betaL = (port.loc[trueT2] - port.loc[trueT1]) / (bench.loc[trueT2] - bench.loc[trueT1])
if betaH > betaL:
n += 1
return 2*(n / n0) -1
커널 함수 정의
def kernel(rms, ris):
rm1, rm2, rm3 = rms
ri1, ri2, ri3 = ris
premise = rm1 < rm2 and rm2 < rm3
if not premise:
return 0
betaH = (ri3 - ri2) / (rm3 - rm2)
betaL = (ri2 - ri1) / (rm2 - rm1)
conclusion = betaH > betaL
if premise and not conclusion:
return 0
else:
return 1
SE 계산식 정의
def stanardE(bench, port, esti):
sum0 = 0
for t1 in bench.index:
sum1 = 0
n0 = 0
for t2, t3 in c(bench.index, 2):
n0 += 1
sum1 += kernel(bench.loc[[t1, t2, t3]], port.loc[[t1, t2, t3]])
sum1 = (sum1 / n0 - esti) ** 2
sum0 += sum1
var = 9 / len(bench.index) * sum0
return np.sqrt(var)
완성
from itertools import combinations as c
def estimation(bench, port):
n0 = 0
n = 0
for t1, t2, t3 in c(range(len(bench)), 3):
n0 += 1
rms = bench.iloc[[t1, t2, t3]].sort_values()
trueT1, trueT2, trueT3 = rms.index
betaH = (port.loc[trueT3] - port.loc[trueT2]) / (bench.loc[trueT3] - bench.loc[trueT2])
betaL = (port.loc[trueT2] - port.loc[trueT1]) / (bench.loc[trueT2] - bench.loc[trueT1])
if betaH > betaL:
n += 1
return 2*(n / n0) -1
def kernel(rms, ris):
rm1, rm2, rm3 = rms
ri1, ri2, ri3 = ris
premise = rm1 < rm2 and rm2 < rm3
if not premise:
return 0
betaH = (ri3 - ri2) / (rm3 - rm2)
betaL = (ri2 - ri1) / (rm2 - rm1)
conclusion = betaH > betaL
if premise and not conclusion:
return 0
else:
return 1
def stanardE(bench, port, esti):
sum0 = 0
for t1 in bench.index:
sum1 = 0
n0 = 0
for t2, t3 in c(bench.index, 2):
n0 += 1
sum1 += kernel(bench.loc[[t1, t2, t3]], port.loc[[t1, t2, t3]])
sum1 = (sum1 / n0 - esti) ** 2
sum0 += sum1
var = 9 / len(bench.index) * sum0
return np.sqrt(var)
from scipy.stats import norm
def nonParaMT(bench, port):
esti = estimation(bench, port)
se = stanardE(bench, port, esti)
statistic = esti * np.sqrt(len(bench)) /se
pVal = 1 - norm.cdf(statistic, loc=0, scale=1)
return esti, se , statistic, pVal테스트와 분석
일단 먼저 알고리즘의 작동 속도에 대해서 한마디 해야 할 것 같다. 가장 오래도는 루프가 만큼 도므로, 이 계산 알고리즘의 시간 복잡도는 대략 이다. 전혀 효율적이진 않다. 배가 고파서 대충 만든 건 절대 아니다. 사실, 분야를 막론하고 대부분의 nonparametric 방법론은 조합론 관련된 루프가 많이 들어가는지라, 데이터가 늘어나면 연산 속도가 엄청나게 뻥튀기되기 때문에, 나는 이 정도에 만족하고 쓰기는 하다(역행렬 구할 때 쓸 수 있는 gaussian-jordan elimination 알고리즘 복잡도도 이 정도 복잡도이니까...). 다만 이쪽 분야로 전공한 사람이라면 더 효율적인 알고리즘을 만들 수 있으리라 생각한다. 하여튼 계산 복잡도 면에서 금융 전공자로선 이 정도가 최선이다.
일단 가장 기본적인 가상 옵션 수익률에 대한 테스트를 진행해 보았다. 튜플의 순서는 추정치, 표준오차, 통계량, p-value이다.

가상옵션만 해도 수익률이 어마어마할텐데, 사실 이렇게 꽤 작고 유한한 통계량을 보이는 이유는 2가지가 있다. 먼저, 이 구간에서의 수익률이 약간 + 쪽으로 치우쳐져 있고, 가상수익 옵션은 수익 구간에선 convex하지 않다. 알고리즘 특성상 0에서 양쪽으로 아래로 휘는 형태의 산점도일 때 test statistic이 훨씬 좋게 나올 텐데, 가상 옵션 수익률은 그렇게 생기지는 않았다. 즉, 이런 식으로 나와야지 훨씬 좋은 통계량이 나온다.
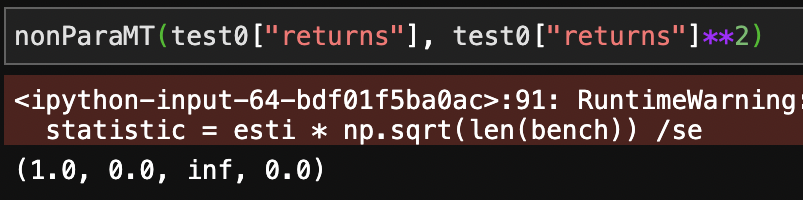
보다시피, 이계도함수가 양수이면서 이론적으로 완벽한 convex에 가까워짐에 따라 통계량은 무한히 발산한다.
이제 HM Model에서 통계적으로 유의하지 않게 나온 내 포트폴리오의 수익률의 통계검정 결과를 확인해 보자.
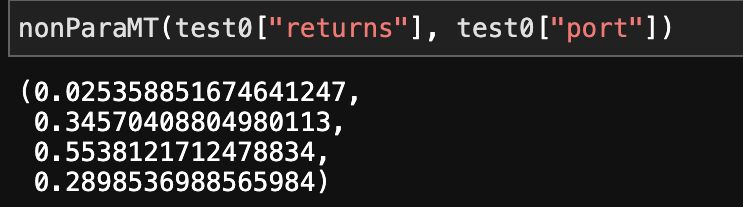
으음, 이렇게 처참하게 나올 거라고는 기대하지 않았지만 어찌되었건 결과적으론 내 포트폴리오는 마켓 타이밍을 잘 하진 않은 것 같다.
심심한 사람들은 자기 주식 거래일지에서 수익률을 따온 후, KOSPI 수익률을 가져와 테스트해보면 재밌을 듯 싶다. 금융 전공자로서 이야기하면, 설령 통계적으로 유의한 결과(p-value가 0.05보다 낮음)가 나오지 않더라도 너무 실망하지 말기를 바란다. 시점선택 능력은 대부분의 투자자가 가지지 못하고, 가지더라도 오랫동안은 가지지 못하는 능력이다. 그런 것보다 매크로(거시경제)에 대한 공부, 가치투자 및 종목 선택과 자산배분 지식을 더 단련하는 것이 좋을 것 같다.
