<머신 러닝 교과서 with 파이썬, 사이킷런, 텐서플로>에서 공부한 내용을 적습니다.
머신 러닝 Machine Learning
데이터를 이해하는 알고리즘의 과학이자 애플리케이션
1-1. 머신 러닝의 종류
지도 학습, 비지도 학습, 강화 학습이 있다.
지도 학습
- 레이블된 데이터
- 직접 피드백
- 출력 및 미래 예측
목적
레이블 된 훈련 데이터에서 모델을 학습하여 본 적 없는 미래 데이터에 대해 예측을 만드는 것
지도는 희망하는 레이블이 있는 일련의 샘플을 의미 한다.
종류
분류 (Classification)
- 과거의 관측을 기반으로 새로운 샘플의 범주형 (categorical) 클래스 레이블을 예측하는 것
- 클래스 레이블은 이산적(discrete)이고 순서가 없어 샘플이 속한 그룹으로 이해 가능
- 이진 분류 (binary classification): 두 개의 클래스 사이를 구분
결정 경계 Decision Boundary
Class green 과 Class red에 해당되는 데이터들이 있을 때 지도 학습 알고리즘을 사용하여 두 클래스를 구분할 수 있는 규칙을 학습한다. 규칙은 점선으로 나타난 결정 경계이다.
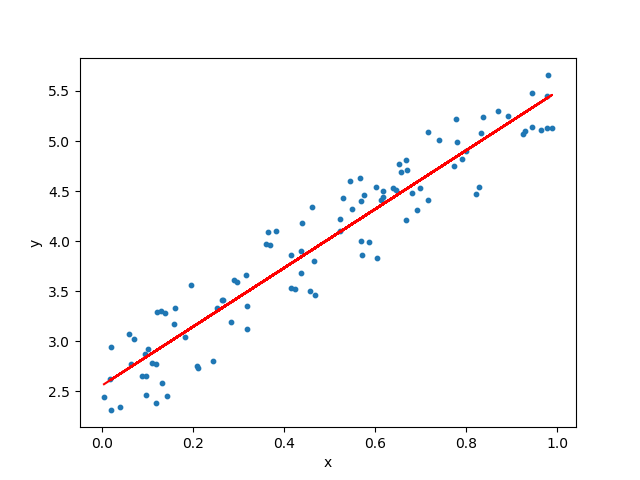
회귀 (Regression)
- 예측 변수 (predictor variable) 또는 설명 변수 (explanatory variable) 또는 입력 (input)과 연속적인 반응 변수 (response variable) 또는 출력 (outcome), 타깃 (target)이 주어졌을 때 출력 값을 예측하는 두 변수 사이의 관계를 찾는다.
선형 회귀 Linear Regression
- 입력 x와 타깃 y가 주어지면 샘플과 직선 사이가 최소가 되는 직선을 그을 수 있다.
- 일반적으로 평균 제곱 거리를 사용
- 데이터에서 학습한 직선의 기울기와 절편을 사용하여 새로운 데이터의 출력값을 예측
비지도 학습
- 레이블 및 타깃 없음
- 피드백 없음
- 데이터에서 숨겨진 구조 찾기
비지도 학습 기법을 사용하면 알려진 출력 값이나 보상 함수의 도움을 받지 않고 의미 있는 정보를 추출하기 위해 데이터 구조를 탐색할 수 있다.
종류
군집: 서브그룹 찾기
- 사전 정보 없이 쌓여 있는 그룹 정보를 의미 있는 서브그룹 또는 클러스터로 조직하는 탐색적 데이터 분석 기법
- 각 클러스터는 어느 정도 유사성을 공유 & 다른 클러스터와는 비슷하지 않은 샘플 그룹 형성
차원 축소: 데이터 압축
- 고차원의 데이터를 다루어야 하는 경우
- 관련있는 정보를 대부분 유지하면서 더 작은 차원의 부분 공간 (subspace)로 데이터를 압축한다.
강화 학습
- 결정 과정
- 보상 시스템
- 연속된 행동에서 학습
강화 학습이란?
- 환경과 상호 작용하여 시스템 (에이전트) 성능을 향상하는 것이 목적
- 환경의 현재 상태 정보는 보상 신호를 포함
- 피드백은 정답 레이블이나 값이 아닌 보상 함수로 얼마나 행동이 좋은지 측정한 값
예시) 체스 게임:
- 체스판의 상태 (환경)에 따라 기물의 이동을 결정
- 보상: 게임을 종료 했을 때 승리하거나 패배하는 것으로 정의
