문제 설명
N개의 숫자가 공백 없이 하나의 문자열로 주어진다. 이 숫자들의 합을 구하는 간단한 문제지만, 어떻게 구현하느냐에 따라 메모리와 성능에 차이가 발생한다.
두 가지 풀이 방식 비교
처음에 작성한 내 코드
import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); String str = sc.next(); String[] arr = str.split(""); int sum = 0; for(String s : arr) { sum += Integer.parseInt(s); } System.out.println(sum); } }
교재의 정답 코드
import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int N = sc.nextInt(); String sNum = sc.next(); char[] cNum = sNum.toCharArray(); int sum = 0; for(int i = 0; i < cNum.length; i++) { **sum += cNum[i] - '0';** } System.out.print(sum); } }
| 항목 | split + parseInt 방식 | toCharArray + ‘0’ 방식 |
|---|---|---|
| 객체 생성 | 문자열 길이만큼 String 객체 생성 | char[] 하나만 생성 |
| 정수 변환 | Integer.parseInt() → 내부 파싱 (CPU 연산 많음) | '문자 - '0' → 단순 산술 연산 |
| 메모리 사용 | 상대적으로 높음 | 낮음 |
| 속도 | 상대적으로 느림 | 빠름 |
아스키코드 기반 정수 변환
입력값을 String으로 받아서 char Array로
char[] cNum = sNum.toCharArray();
아스키코드에서 같은 의미의 문자와 숫자의 코드 값 차이는 48이다.
예를 들어 문자 ‘1’은 아스키코드 값이 49이므로 문자 ‘1’을 숫자 1로 변환하려면 ‘1’- 48 또는 ‘1’-’0’과 같이 연산하면 된다.
왜 split("") + parseInt()는 비효율적인가?
String[] arr = str.split("");
for (String s : arr) {
sum += Integer.parseInt(s);
}- split("")은 입력 문자열을 한 글자씩 잘라 여러 개의 String 객체를 생성한다.
- Integer.parseInt(s)는 내부적으로 문자열 → 정수로 변환하기 위해 문자 분석 + 연산 처리가 반복된다. → 이 두 가지가 메모리와 CPU 모두에 부담을 준다.
char[] cNum = sNum.toCharArray();
for (int i = 0; i < cNum.length; i++) {
sum += cNum[i] - '0';
}- toCharArray()는 문자열을 한 번만 복사해서 char[] 하나 생성.
- 각 문자에 대해 '0'만 빼서 숫자 변환 → 매우 빠름, 가벼움.
실행시간 측정해보기
실제 두 방식의 성능 차이를 보기 위해 System.nanoTime()을 사용해 실행 시간을 측정해봤다.
public class Split {
public static void main(String[] args) {
int N = 1000000;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < N; i++) sb.append('1');
String input = sb.toString();
long start = System.nanoTime();
String[] arr = input.split("");
int sum = 0;
for (String s : arr) {
sum += Integer.parseInt(s);
}
long end = System.nanoTime();
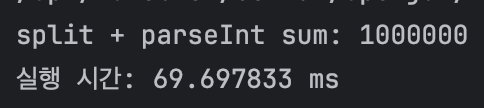
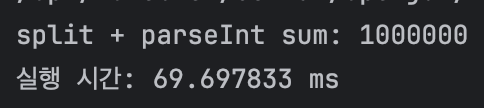
System.out.println("split + parseInt sum: " + sum);
System.out.println("실행 시간: " + (end - start) / 1000000.0 + " ms");
}
}
import java.util.*;
public class CharArrayBenchmark {
public static void main(String[] args) {
int N = 1000000;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < N; i++) sb.append('1');
String input = sb.toString();
long start = System.nanoTime();
char[] arr = input.toCharArray();
int sum = 0;
for (char c : arr) {
sum += c - '0';
}
long end = System.nanoTime();
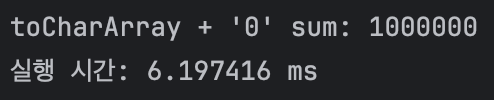
System.out.println("toCharArray + '0' sum: " + sum);
System.out.println("실행 시간: " + (end - start) / 1000000.0 + " ms");
}
}
결과
입력 : 1000000
| 방식 | 실행 시간 |
|---|---|
| split("") + parseInt() | 약 69ms |
| toCharArray() + '0' | 약 6ms |
- 문자열 길이가 커질수록 parseInt()의 반복 호출이 성능 저하를 유발함
- 단순한 산술 연산 방식(toCharArray)은 CPU 부하 없이 빠르게 처리
결론
- split("") 방식은 String 객체 + 파싱 연산으로 인해 메모리와 CPU 부담이 크다.
- toCharArray()와 '0'을 활용한 방식은 불필요한 객체 생성 없이 빠르고 가볍다.
- 입출력이 많은 문제, 반복 연산이 많은 문제에서는 작은 차이도 누적되면 큰 성능 차이로 이어진다.
