Synchronous와 Blocking은 유사하고, Asynchrononus와 Non-Blocking은 유사한 개념이라고 앞서 설명했다.
그런데 그럼 서로 반대되는 Synchronous와 Non-Blocking, Asynchrononus와 Non-Blocking 을 동시에 가지고 있는 녀석들은 대체 뭘까???
지금부터 하나씩 천천히 설명해 보자.
I/O Model
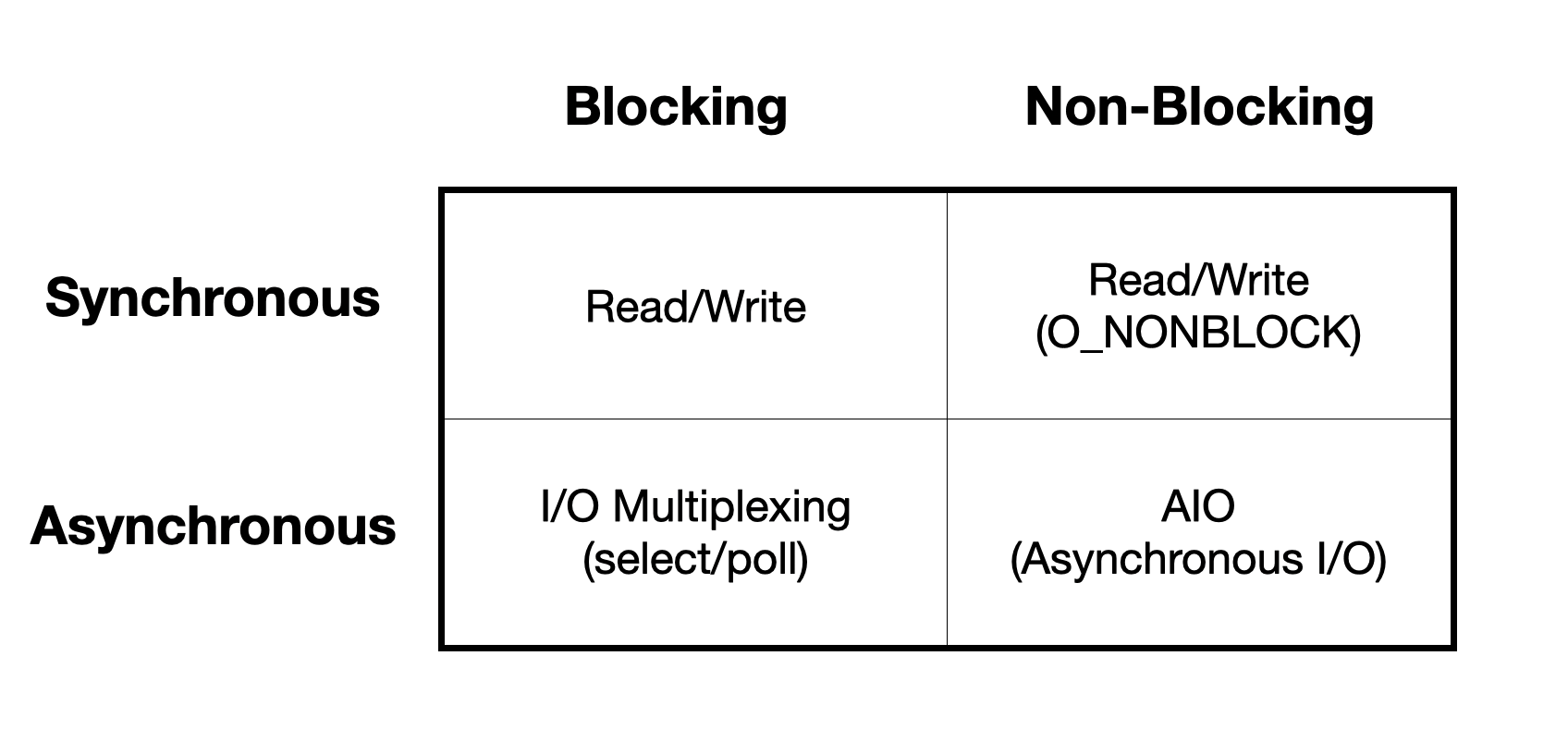
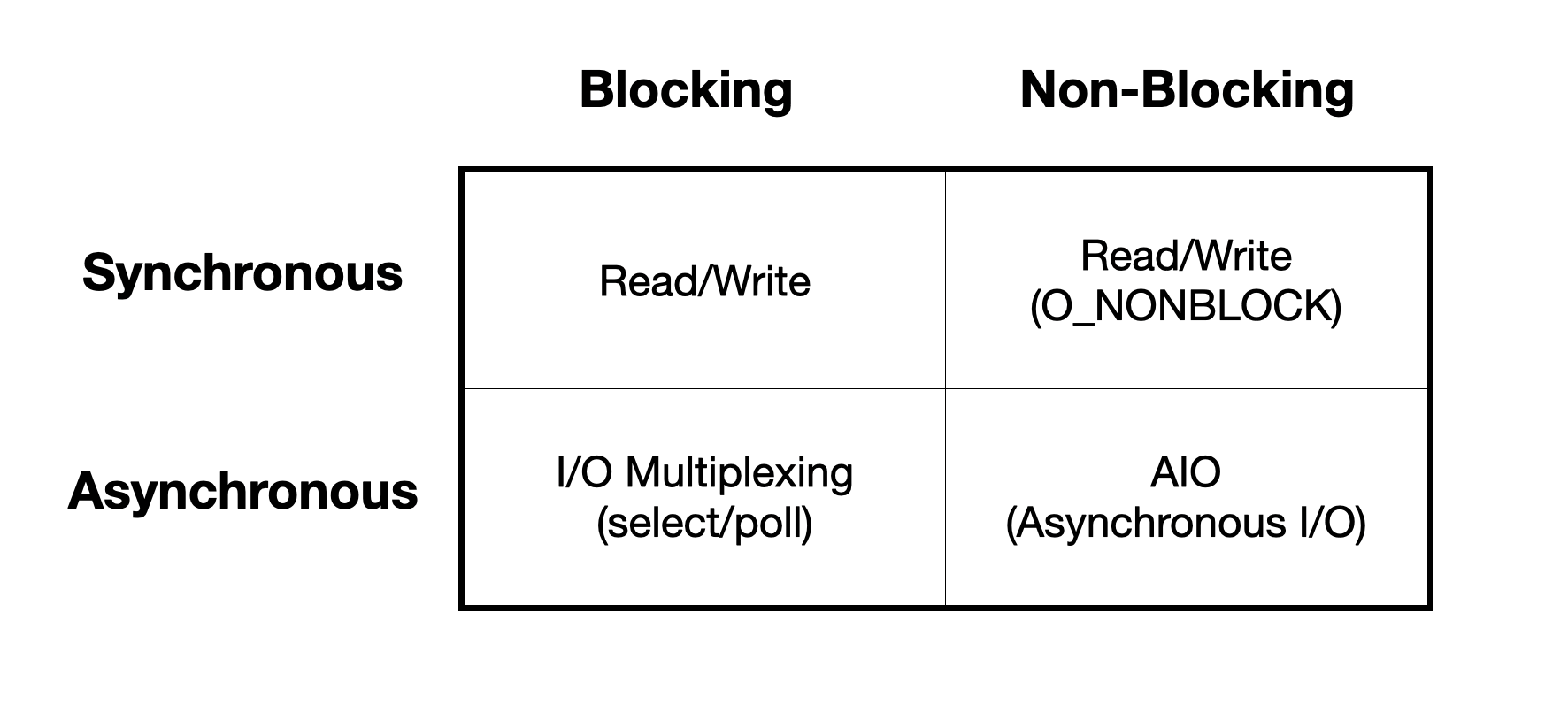
아래 테이블은 Linux에서 사용가능한 I/O 모델들을 표현한 것이다.
앞으로 설명할 Application은 앞서 말한 호출자에 해당하고 Kenel이 functionA에 해당한다는 것을 염두해 두자.
Synchronous blocking I/O
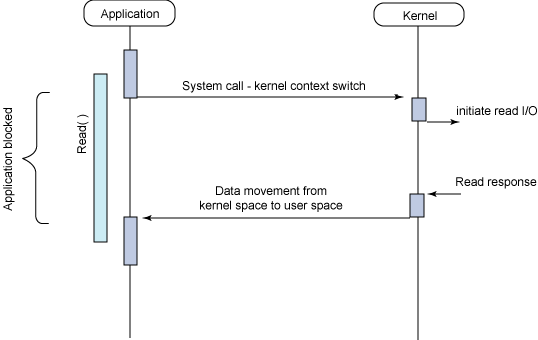
어플리케이션에서 시스템 콜을 호출하면 해당 어플리케이션은 I/O buffer에 데이터가 차기 전까지 blocking된 상태로 대기한다. 시스템 콜이 결과 값을 반환하기 전까지 어플리케이션은 아무것도 하지 않고 기다린다는 것을 의미한다.
이때 호출한 Application은 CPU를 사용하지 않고 있다가 결과값(response)을 받은 후에 작업을 시작한다. 때문에 꾀나 효율적이라고 볼 수 있다.
Synchronous non-blocking I/O
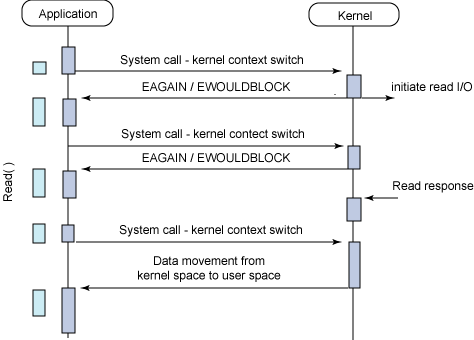
어플리케이션에서 시스템 콜을 호출한다. I/O buffer에 데이터가 차든 안차든 결과값을 바로 반환한다. 이때의 결과값은 아직 데이터가 차지 않았다는 에러 코드(EAGAIN or EWOULDBLOCK)를 반환하게 된다.
어플리케이션은 원하는 결과값을 받지 못했으므로 다시 커널에게 시스템 콜을 보낸다. 여러번 에러코드를 받은 후 원하는 결과를 얻게 된다.
이러한 방식은 굉장히 비효율적이다. 왜냐하면 어플리케이션과 커널간의 Context Switch가 매우 빈번하게 발생하기 때문이다.
Asynchronous blocking I/O
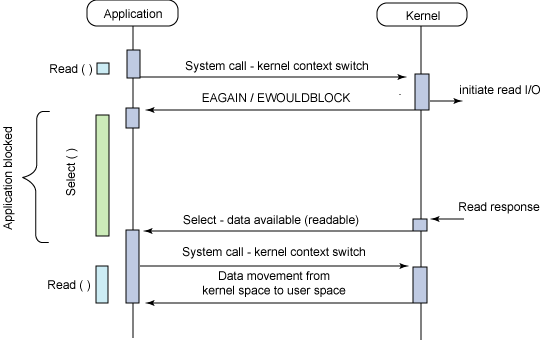
어플리케이션은 마찬가지로 커널에게 시스템 콜을 보낸다. 아직 데이터가 차지 않았으므로 에러코드를 받게 된다. 이때 select()함수가 어플리케이션을 Blocking상태로 만든다. 커널로부터 response를 받은 경우 Blocking상태에서 벗어나게 된다.
Asynchronous non-blocking I/O (AIO)
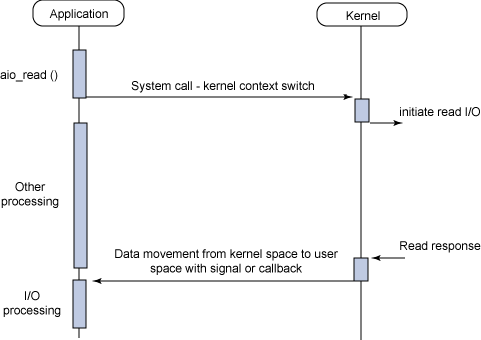
어플리케이션의 request에 즉각적으로 response하게 된다. 다른 스레드에서 I/O 작업을 하는 동안 어플리케이션은 다른 작업을 할 수 있게 된다. I/O 작업을 끝마친 스레드는 callback을 이용하여 어플리케이션에게 알리게 된다.
참고
https://developer.ibm.com/technologies/linux/articles/l-async/
