✅ AI 채팅 링크: https://gemini.google.com/share/8cd3aa8280b2
Problem definition: We discussed one possible implementation of LIS (Refer to previous slide26). The goal is to track and print the actual sequence, but you will use AI to achieve this optimality.
- Step 1: Prompt an AI to write Python code that finds the LIS for the array [10, 22, 9, 33, 21, 50, 41, 60] and prints the actual elements of that sequence (not just the length). Document your prompt and the AI’s initial output. (HINT: Need an additional variable to store the LIS)
- Step 2: AI often solves this by storing entire arrays for every state, which wastes memory. Analyze the space complexity of the AI’s initial code.
- Step 3: If the AI’s space complexity is inefficient, continue prompting the AI: “Optimize the space complexity. Do not store full arrays for each state; instead, use a 1D prev array to track the indices and reconstruct the sequence at the end.” Document this interaction.
- Step 4: Submit the final optimized code. Note that your implementation must return both the length of the LIS and the exact elements of the LIS. Briefly explain how the array successfully reconstructs the path.
Step1
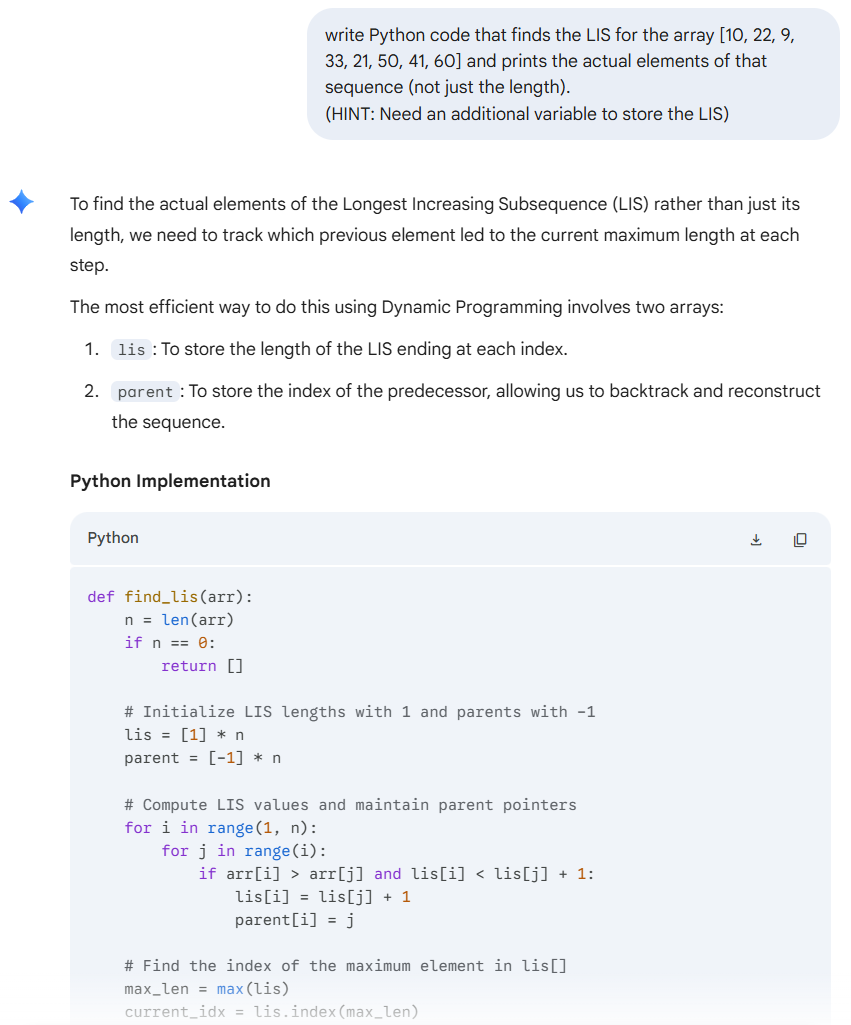
My Prompt
write Python code that finds the LIS for the array [10, 22, 9, 33, 21, 50, 41, 60] and prints the actual elements of that sequence (not just the length).
(HINT: Need an additional variable to store the LIS)
AI's output code
def find_lis(arr):
n = len(arr)
if n == 0:
return []
# Initialize LIS lengths with 1 and parents with -1
lis = [1] * n
parent = [-1] * n
# Compute LIS values and maintain parent pointers
for i in range(1, n):
for j in range(i):
if arr[i] > arr[j] and lis[i] < lis[j] + 1:
lis[i] = lis[j] + 1
parent[i] = j
# Find the index of the maximum element in lis[]
max_len = max(lis)
current_idx = lis.index(max_len)
# Reconstruct the LIS by backtracking through parent pointers
sequence = []
while current_idx != -1:
sequence.append(arr[current_idx])
current_idx = parent[current_idx]
# The sequence is built backwards, so reverse it
return sequence[::-1]
# Input array
nums = [10, 22, 9, 33, 21, 50, 41, 60]
result = find_lis(nums)
print(f"Input Array: {nums}")
print(f"Longest Increasing Subsequence: {result}")
print(f"Length of LIS: {len(result)}")Step2
만약 전체 배열을 매 단계마다 복사하여 저장하는 방식으로 코드를 짜게 되면 2차원 리스트 형태가 필요하다. 이렇게 공간을 낭비하는 방식은 공간 복잡도가 O()가 된다.
하지만 AI가 생성한 초기 코드를 분석해 보면 lis, parent 두 개의 1차원 배열만을 사용하여 이 문제를 회피했다. lis 배열은 각 인덱스까지의 LIS 길이를 저장하는 크기가 n인 1차원 배열이다. parent 배열은 수열의 경로를 역추적하기 위해 바로 이전 요소의 인덱스를 저장하는 크기가 n인 1차원 배열이다. 결과적으로 크기가 n인 1차원 배열 두 개를 할당하여 총 2n의 메모리만을 사용하므로, 위 AI 코드의 실제 공간 복잡도는 잘 최적화된 O(n)이다.
Step3
Step1의 최초 프롬프트 결과에서, AI가 이미 1차원 배열인 parent를 사용하여 공간 복잡도를 O(n)으로 최적화한 코드를 생성하였다. 따라서 메모리 낭비를 지적하고 최적화를 요구하는 추가적인 프롬프팅 과정이 필요하지 않았으므로 Step3은 생략한다.
Step4
Step1에서 공간 복잡도가 이미 최적화되어 출력되었기 때문에, LIS의 길이와 정확한 요소를 동시에 반환하는 최종 요구사항을 충족하기 위해 기존 코드의 리턴값과 변수 할당 부분만 약간 수정하여 최종 코드를 완성했다.
def find_lis(arr):
n = len(arr)
if n == 0:
return 0, []
# Initialize LIS lengths with 1 and parents with -1
lis = [1] * n
parent = [-1] * n
# Compute LIS values and maintain parent pointers
for i in range(1, n):
for j in range(i):
if arr[i] > arr[j] and lis[i] < lis[j] + 1:
lis[i] = lis[j] + 1
parent[i] = j
# Find the index of the maximum element in lis[]
max_len = max(lis)
current_idx = lis.index(max_len)
# Reconstruct the LIS by backtracking through parent pointers
sequence = []
while current_idx != -1:
sequence.append(arr[current_idx])
current_idx = parent[current_idx]
# The sequence is built backwards, so reverse it
return max_len, sequence[::-1]
# Input array
nums = [10, 22, 9, 33, 21, 50, 41, 60]
lis_length, lis_sequence = find_lis(nums)
print(f"Input Array: {nums}")
print(f"Longest Increasing Subsequence: {lis_sequence}")
print(f"Length of LIS: {lis_length}")위 코드는 parent 배열을 활용한 Backtracking 기법을 통해 실제 수열의 경로를 완성한다. 먼저 DP 테이블을 갱신하는 과정에서 어떤 요소가 현재의 수열을 연장시켰는지 기억하기 위해, 현재 인덱스 위치의 parent 배열에 이전 요소의 인덱스를 기록해 둔다. 배열 탐색이 끝나면 최대 LIS 길이를 가지는 요소의 인덱스를 찾아 역추적의 시작점으로 설정한다. 이후 parent 배열에 저장된 이전 인덱스들을 타고 연속적으로 거슬러 올라가며 실제 요소들을 기록한다. 이 역추적 과정은 초기값 -1에 도달할 때까지 반복된다. 마지막으로, 뒤에서부터 역순으로 기록된 배열을 원래 순서대로 뒤집어주면 정확한 LIS 경로가 완성된다.
