SASRec 코드리뷰
이전 추천시스템 세미나에서도 SASRec에 대한 코드리뷰가 존재하였기에, 이전 리뷰를 토대로 좀 더 보충하여 코드리뷰를 진행하겠습니다.
1. 데이터셋 준비
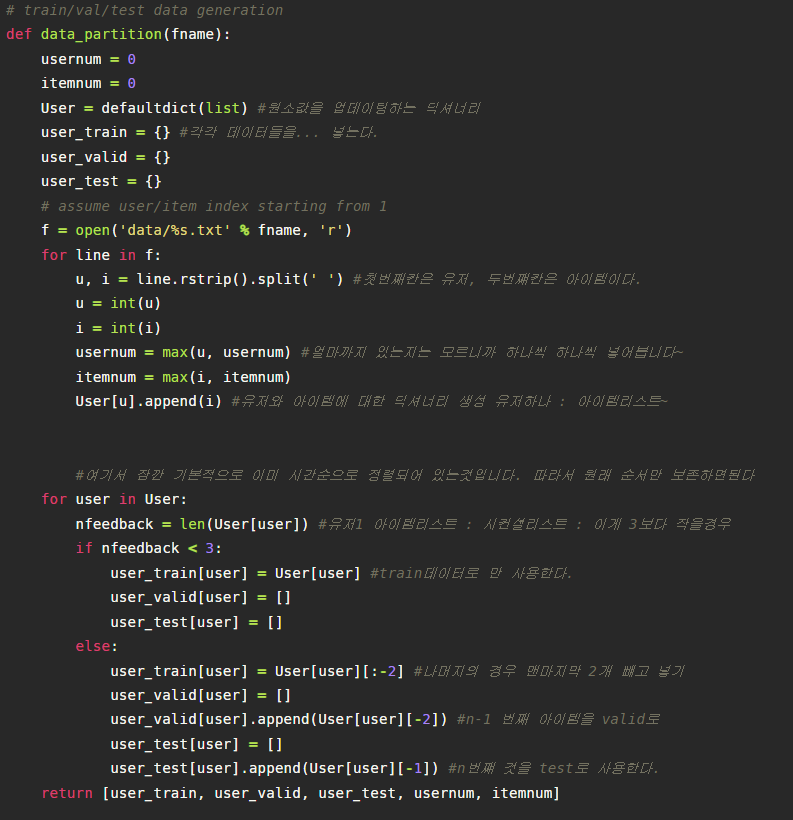
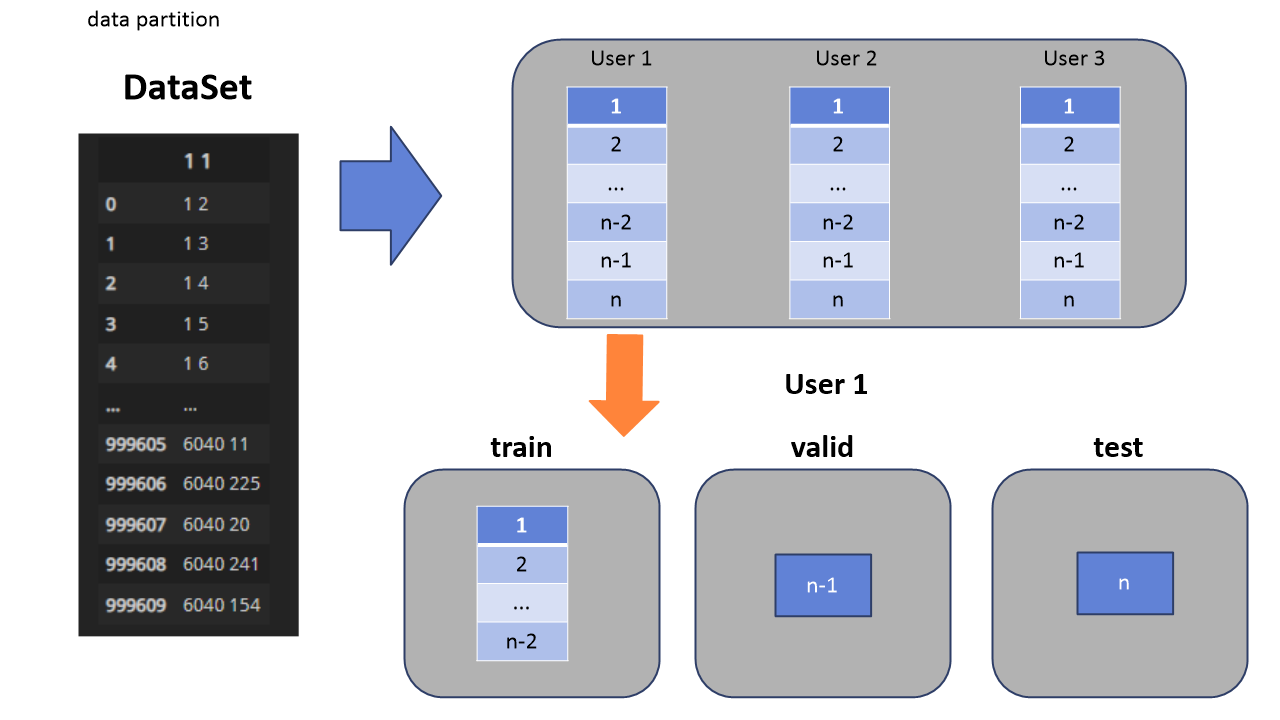
먼저 해당 모델에서는 사용자와 아이템들로 이루어진 2개의 열을 가진 데이터셋을 이용합니다. 참고로 시간적 순서에 따라 이미 아이템이 정렬된 상태입니다. 해당 data_partition 함수에 대해 설명하자면, 각 유저를 key로, 아이템리스트들을 value로 하는 딕셔너리를 만듭니다. 참고로 defaultdict의 경우 추가한 key가 존재하지 않을시 자동으로 만들어주는 dict입니다. 그렇게 만든 딕셔너리를 통해, 각 유저마다의 train/valid/test셋을 만듭니다. test셋의 경우 맨마지막, n번째 아이템을, valid는 n-1번째 아이템, train은 n-2번째 아이템을 사용합니다. 조건문을 보면 아이템리스트가 3개 미만인 경우 오직 train셋으로만 사용하도록 되어있는 걸 볼 수 있습니다.
2. Input 값 만들기
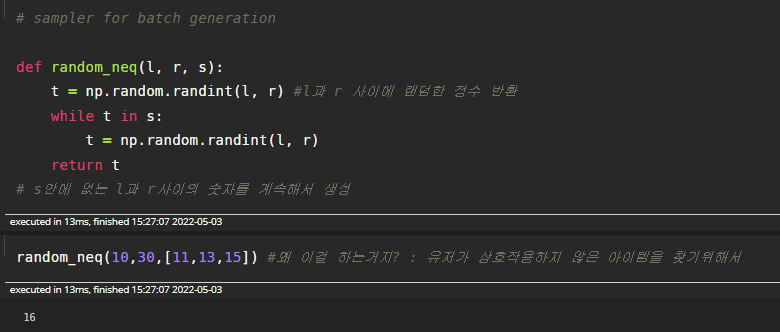
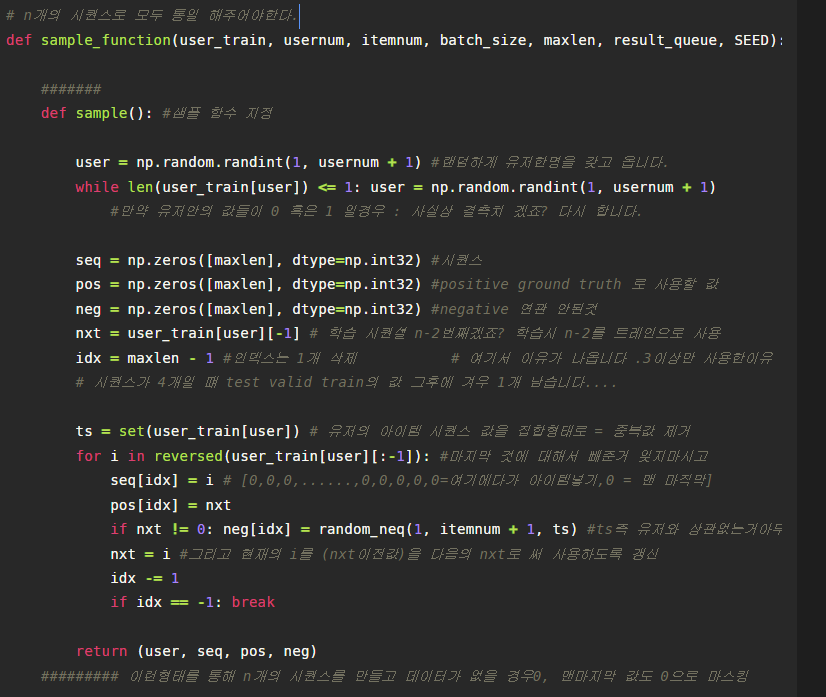
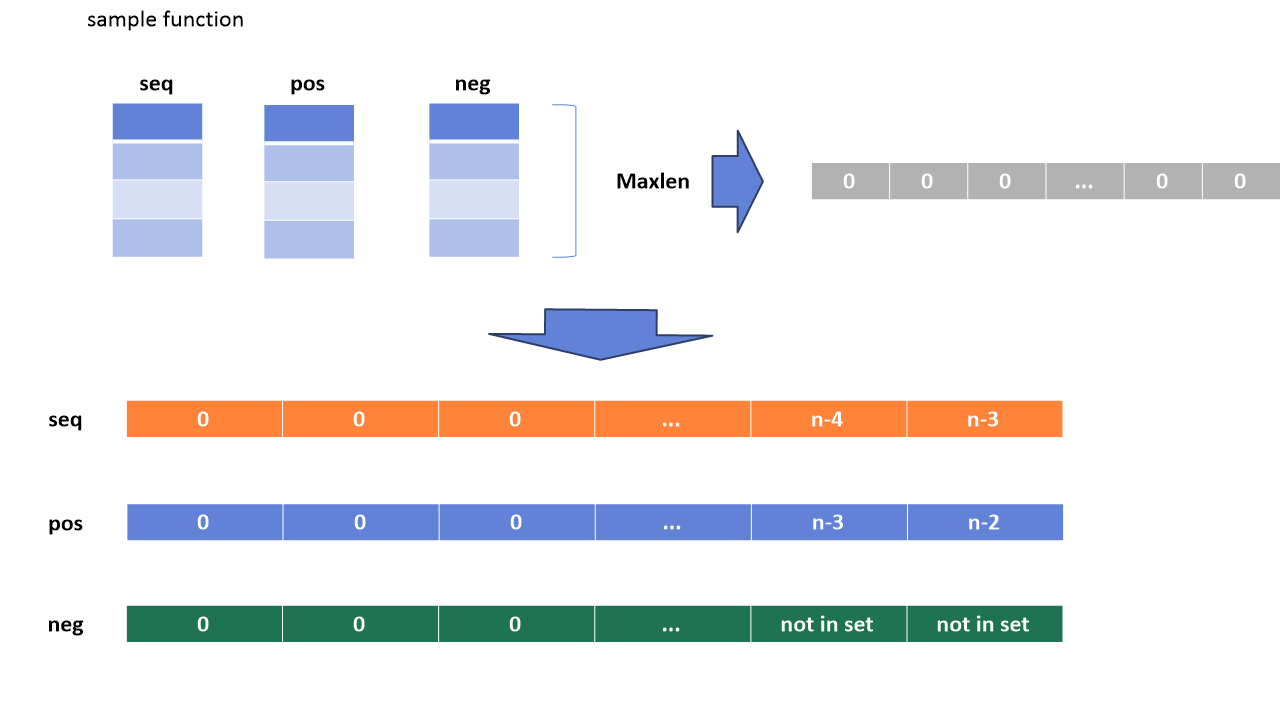
데이터셋이 만들어 졌다면 이제 인풋값들을 만드는 차례입니다. 각 유저별 train셋을 이용하여 seq, pos, neg의 총 3개의 데이터 리스트를 만듭니다. 모델은 미리지정된 maxlen, n개의 시퀀스 값을 입력값을 받으므로 해당 유저의 train셋을 적절히 변환시켜야합니다. 먼저 seq,pos,neg의 정해진n값의 길이를 가진 어레이를 만들고, 시퀀스에는 n-3부터 역순으로 seq를 채워주고, pos는 positive로 ground truth값으로 사용할 것이기에 n-2부터 역순으로 pos를 채워줍니다. neg의 경우는 유저의 아이템리스트 집합안에서 존재하지 않는 무작위 아이템을 집어넣어 neg를 구성합니다.
위에서 만든 함수를 이용하여 batch_size(각 배치안에 들어갈 user의 수) 만큼 데이터를 분할하여 훈련을 진행하게 됩니다.
3. SASRec의 구조(Block)
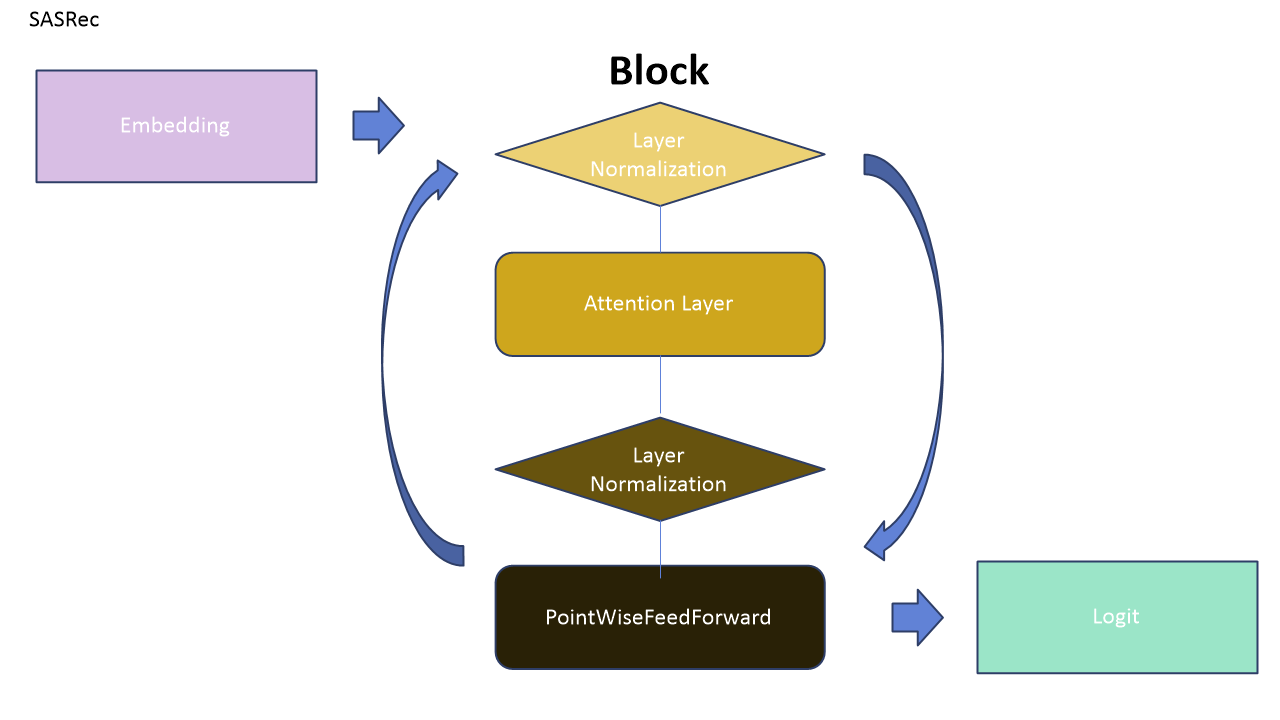
SASRec의 전반적인 구조는 임베딩레이어를 거친 인풋 데이터가 다음과 같은 블록을 반복적으로 지나간 후 마지막에 로짓 값으로 출력되는 구조입니다. 각 어텐션 레이어와 포인트와이즈 피드포워드 네트워크 레이어를 지날 때 마다 Layer Normalization이 계속해서 적용되며 마지막 블록이 끝나도 마지막 Layer Normalization을 지난 후에 출력 됩니다.
각 레이어의 자세한 설명은 뒤에 있습니다.
4. 임베딩
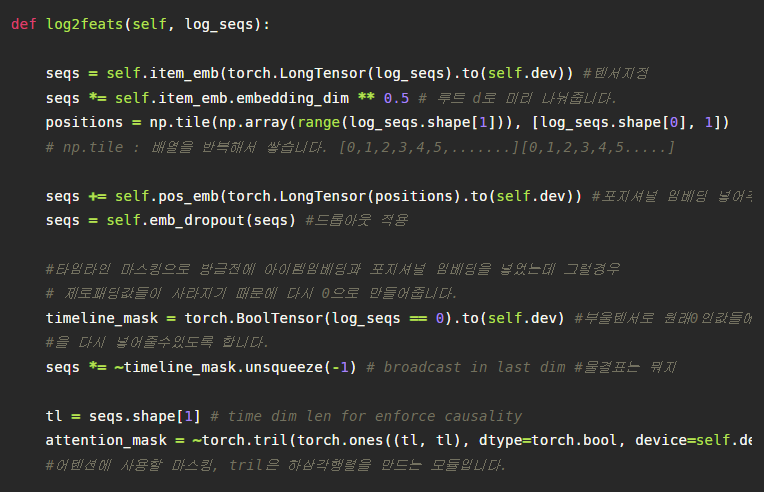
먼저 훈련에 사용될 데이터는 다음과 같이 train셋 입니다. 먼저 위를 보면, 다음 해당 아이템 시퀀스를 다음과 같이 임베딩 레이어를 통해 D개 차원을 갖는 표현으로 바꾸어 줍니다.
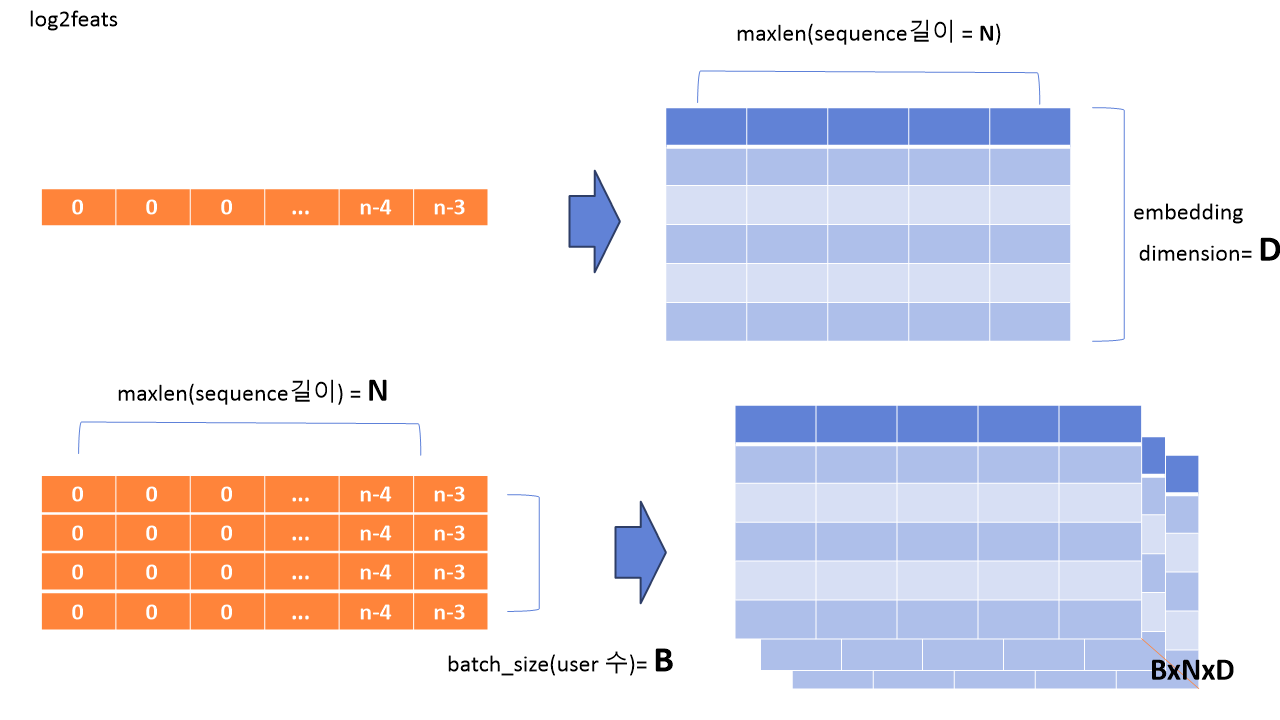
이것을 모든 배치마다 일괄적으로 적용하여 다음과 같은 BxNxD의 차원을 갖는 텐서를 얻습니다. B는 배치사이즈, N은 최대 시퀀스의 길이, D는 임베딩 차원입니다. (참고로 파이토치는 배치사이즈와 같은 높이축?을 앞에 둡니다.)
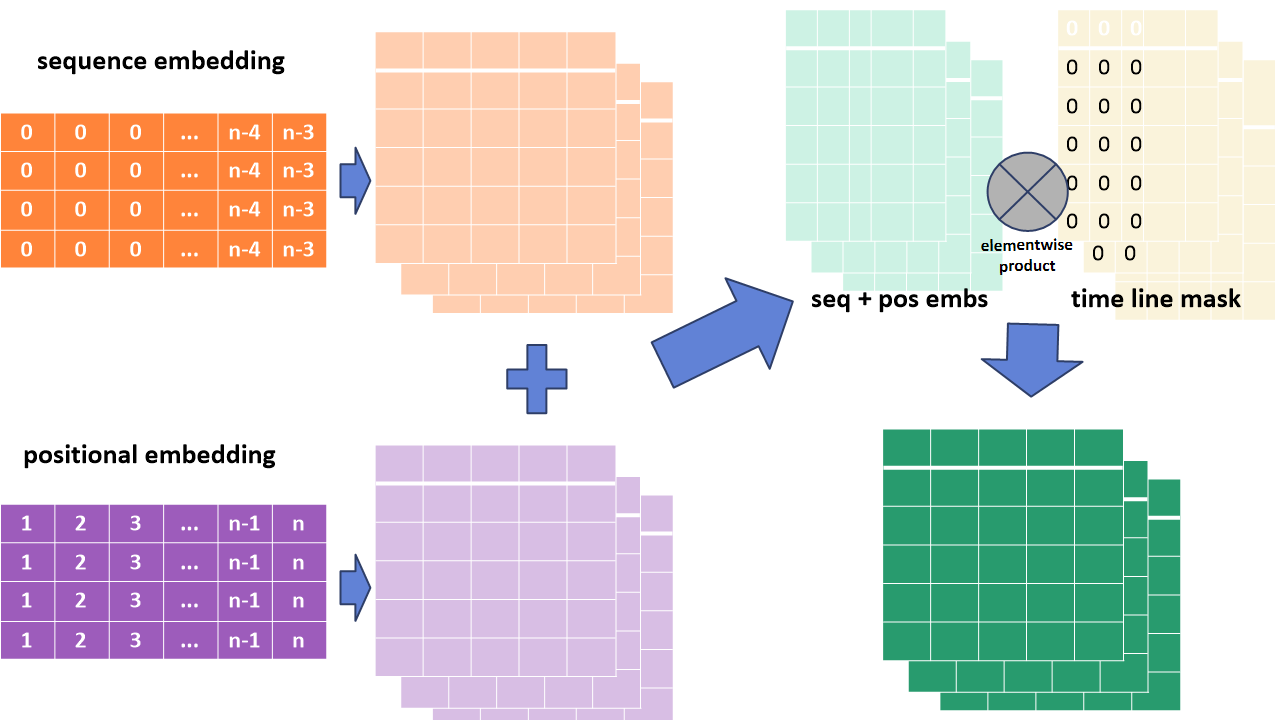
그 후에 어텐션레이어의 경우 자체적으로 순서에 대한 학습이 불가능하므로 positional embedding을 만듭니다. positional embedding의 경우 다음과 같이 1~n의 값을 순서대로 나열한 다음 데이터행렬을 임베딩레이어를 거쳐서 시퀀스 임베딩과 합할 수 있는 같은 차원의 데이터로 만듭니다. 그리고 만들어진 시퀀스 임베딩과 positional embedding을 행렬 합을 합니다. 여기서 다음 합의 과정을 거치게 될 시 비어있던, padding된 값들이 0이 아니게 되는데, 이를 다시 0으로 만들기 위해 time line mask를 만들고, elementwise 곱을 적용시킵니다. 이제 이 텐서는 어텐션 함수에 적용할 수 있게 되었습니다.
5. 어텐션 레이어
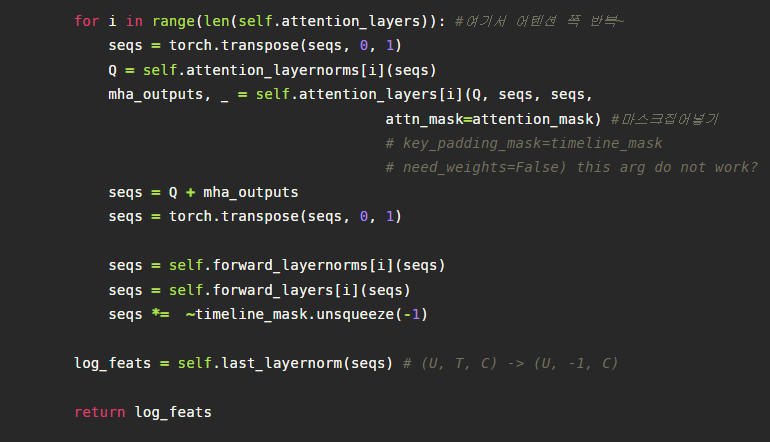
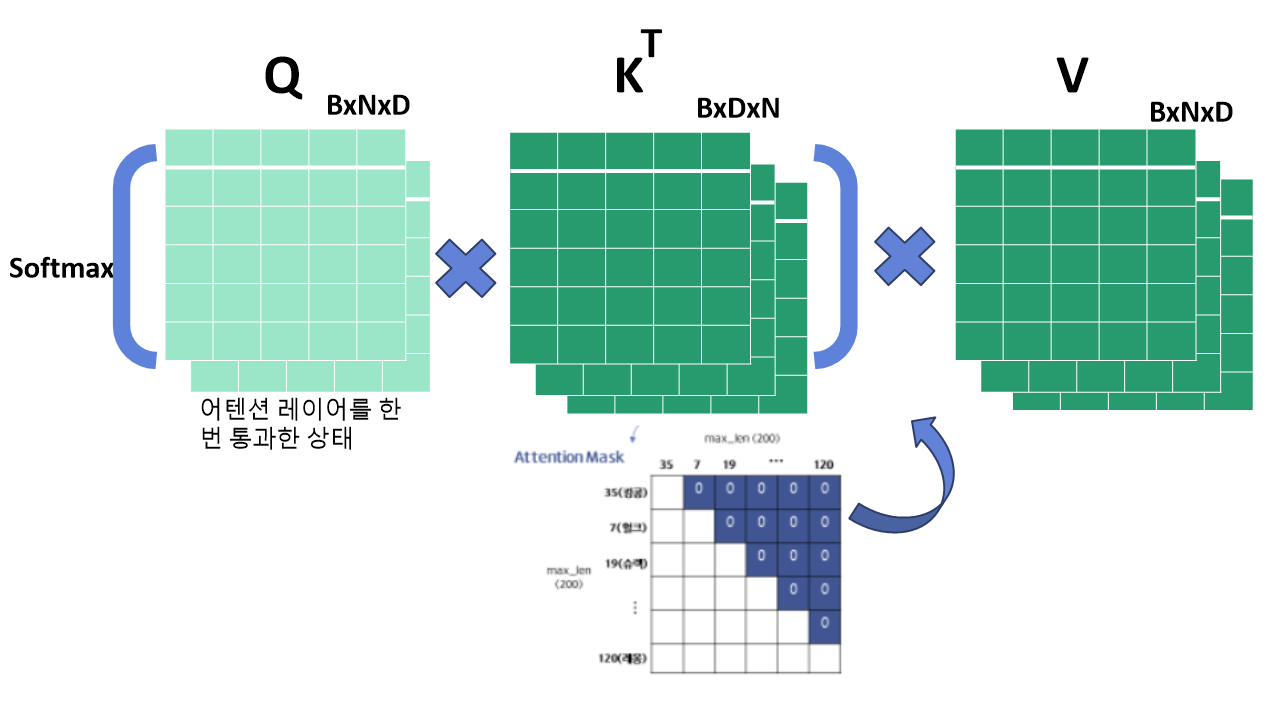
만들어진 텐서를 Query Key Value로 사용해 어텐션 함수에 넣습니다. 참고로 Q의 경우 Layer Normalization을 한번 거치고 적용합니다. 우리가 이미 알고있는 어텐션 함수를 지나면서 어텐션 마스크를 씌우게 되는데 미래 시점의 값을 참조하게 되는 데이터 누출을 막기위함입니다.
이렇게 어텐션 레이어를 통해 변환된 텐서는 레이어 노말라이제이션을 거친후 포인트와이즈 피드포워드 네트워크 레이어로 들어갑니다.
6. Point-wise FeedForward
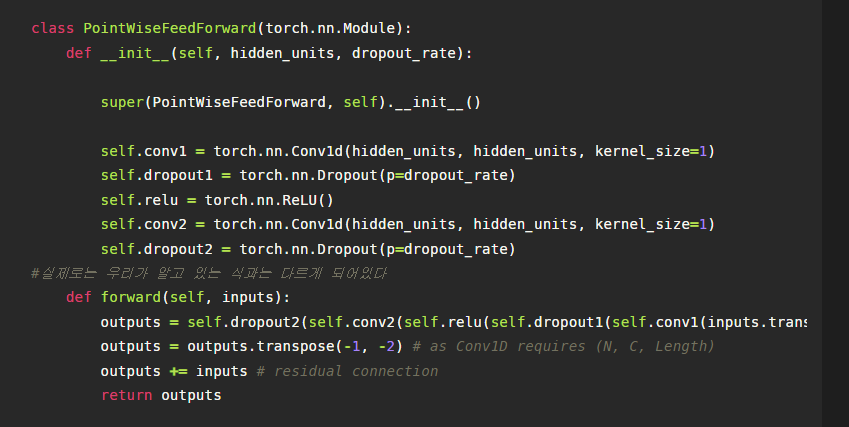
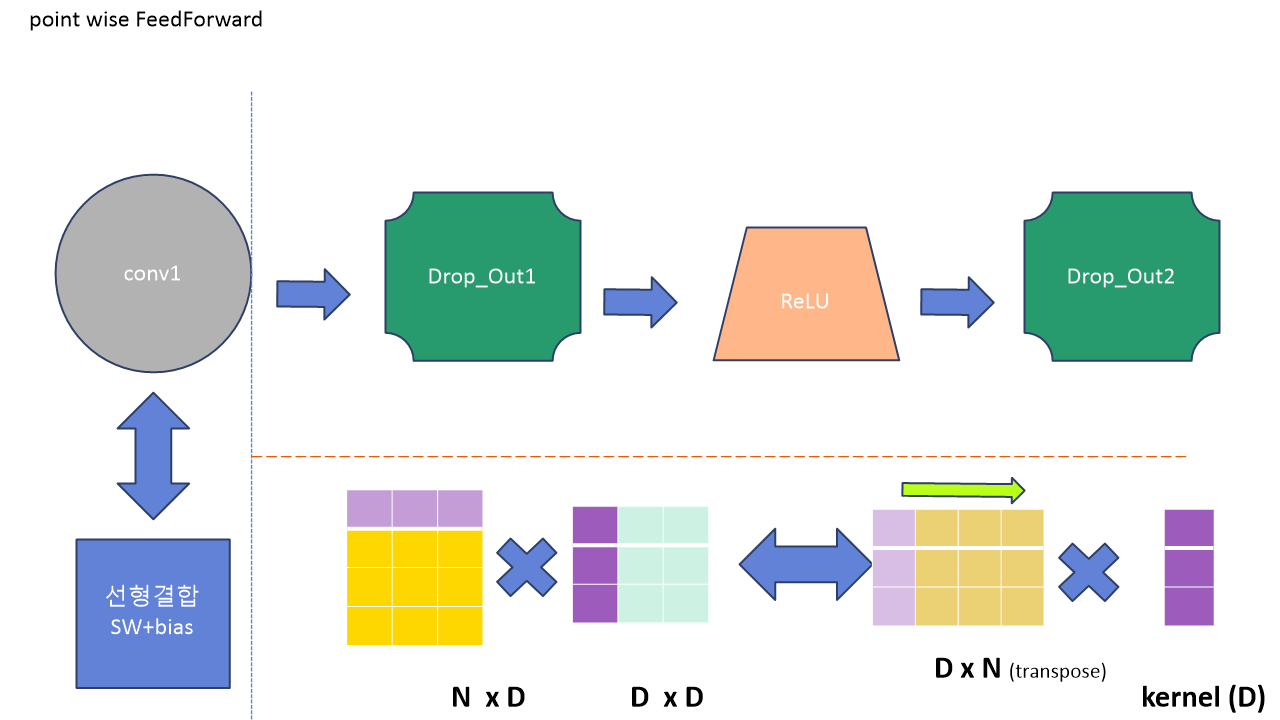
포인트와이즈 피드포워드 네트워크 레이어의 구조는 다음과 같습니다. 여기서 특기할 만한 점은 행렬 곱 + bias 형태의 선형결합을 conv1을 통해 구현한 것인데요, 원래는 아래의 왼쪽 부분과 같이 행렬 연산을 수행하지만 conv1을 실행할 경우 커널이 전치된 텐서를 지나가면서 가중치를 곱해주는 형식으로 계산이 이루어지게 됩니다. 이러한 계산을 위해서 conv1 전에 데이터를 전치시키는 과정을 거치게 됩니다. 참고로 커널의 사이즈가 1인 것이 커널 갯수가 1인 것은 아닙니다.
7. OutPut
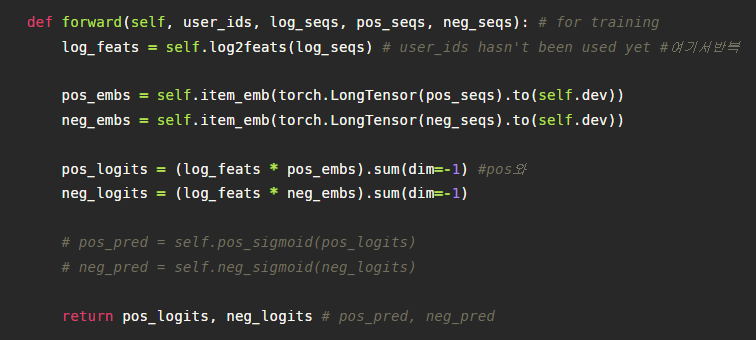
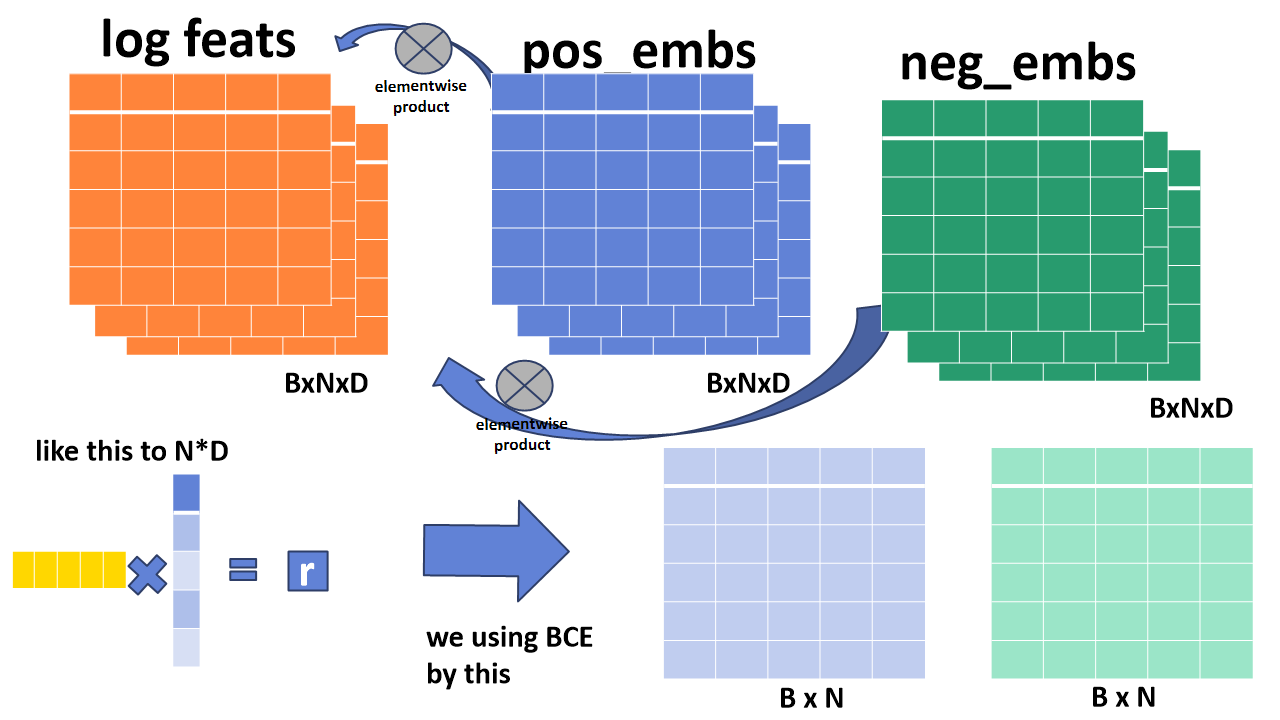
위의 과정들을 통해서 최종적으로 만들어진 텐서는 입력값으로 받았었던 pos(positional아닙니다. positive입니다.), neg 시퀀스의 임베딩 텐서와 element-wise 곱을 한 후에, D의 축으로 합하여 텐서 BxN을 만듭니다. 이는 마치 왼쪽의 행렬곱을 적용하는 것과 같으며, 이것은 해당 시퀀스별 관련도 점수 r을 나타냅니다.
만들어진 pos_logit과 neg_logit은 각각 Binary cross Entropy loss에 이용되어 모델은 pos의 값은 크게 neg의 값은 작게 되도록 학습되어집니다. 현재 이미지가 잘린 상태이지만 pos_label은 1이 neg_label은 0으로 되어 있습니다.
8. Prediction
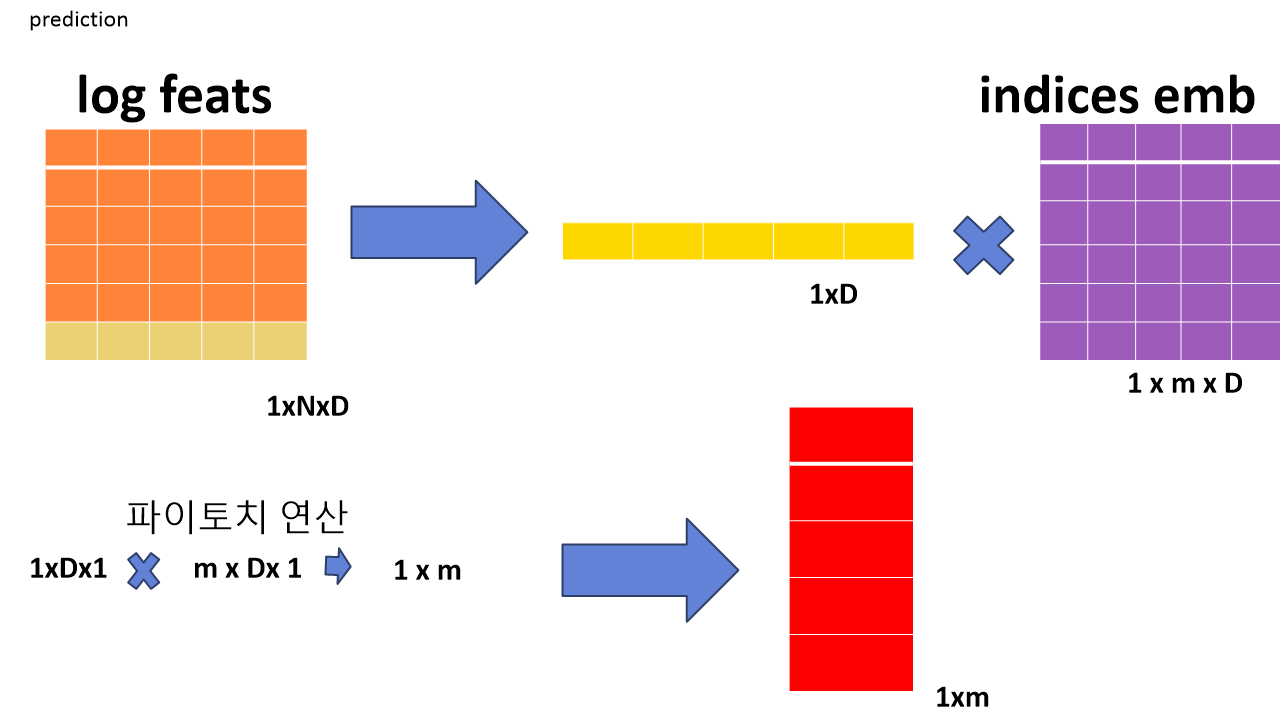
예측을 실행할 때의 인풋은 각 사용자별로 하나의 시퀀스가 들어오므로 텐서는 다음과 같은 차원을 가집니다. 그리고 만들어진 텐서에서 가장 마지막 행(n번째 시퀀스)만을 필요로 합니다. 이 마지막 행을 m개의 아이템에 대한 indices emb과 연산하여 1xm의 아웃풋 벡터를 출력합니다. 여기서 파이토치의 연산 특성상 다음과 같은 형태로 차원의 변환이 이루어지기에 그에 맞추어서 연산을 진행해야합니다.
9. Evaluate
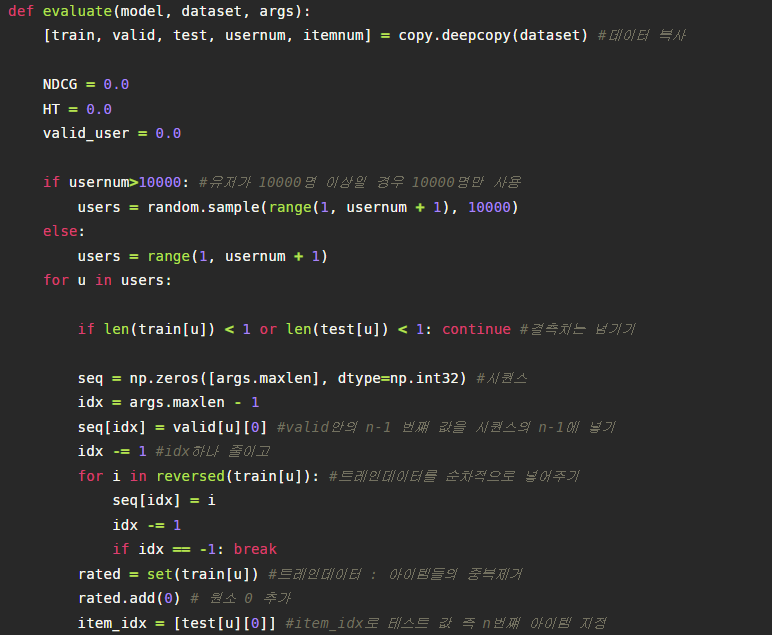
안의 값들이 없는 결측치유저는 건너뛰고 valid까지 시퀀스로 넣어서 model_prediction인풋으로 다시 만들어 넣습니다.
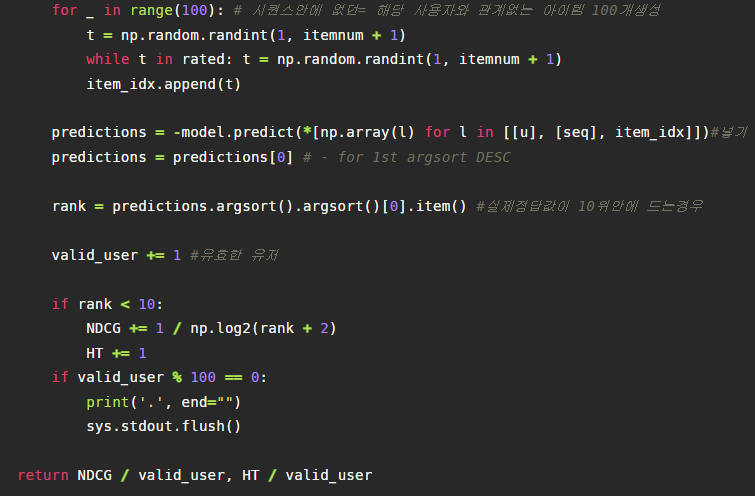
또한 보면은 item_idx를 만드는 것을 확인할 수 있는데, 맨 먼저 우리가 예측할 test셋의 n번째 유저의 아이템을 넣고서, 사용자의 아이템 시퀀스들과 중복되지않은, 상호작용되지 않은 값들을 100개 넣어 총 101개의 (방금 indices의 m이겠죠) 아이템 리스트를 만들어 인풋값으로 또 넣습니다.
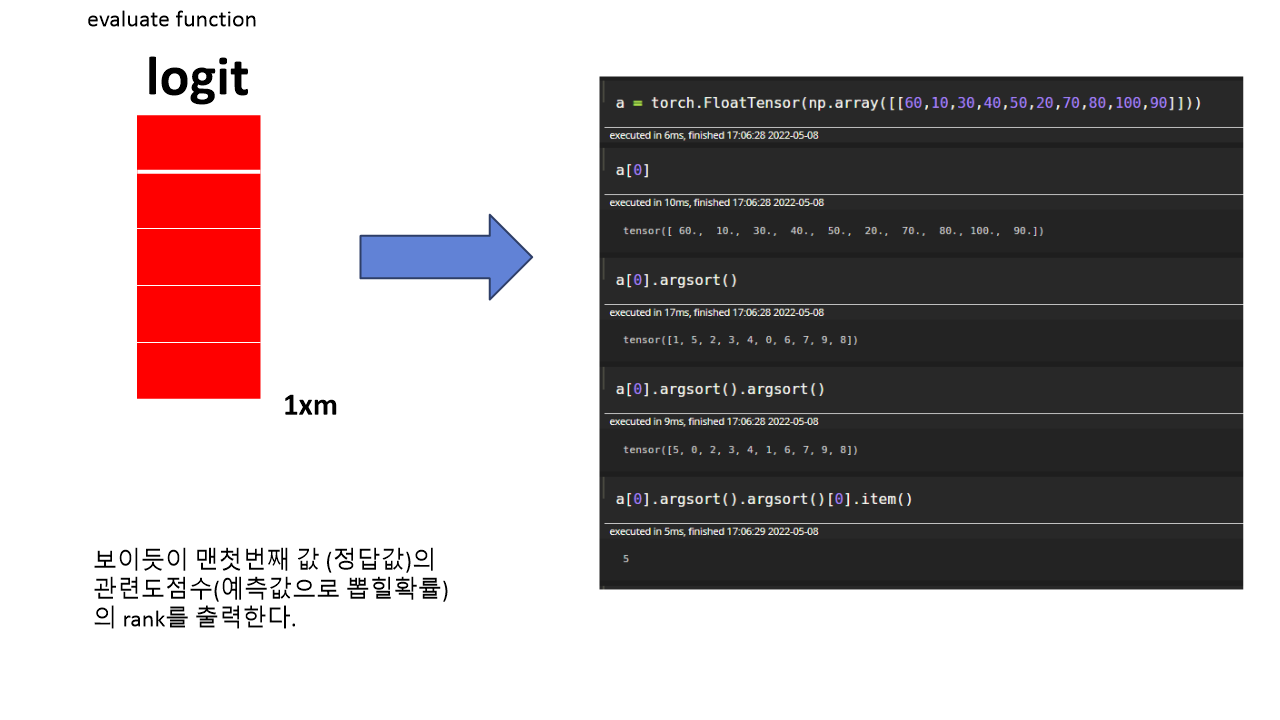
그렇다면 방금전 Prediction에서 보았듯이 model은 1xm의 관련도 점수 벡터를 내뱉게 됩니다. 그리고 우리가 예측해야할 맨 첫번째, n번째 아이템의 랭크를 이렇게 도출할 수 있게 되며, 다음을 통해 NDCG를 계산하게 됩니다.
