
Elasticsearch?
Elasticsearch는 인기있는 오픈소스 검색엔진이다. 처음에는 Full-text search engine으로 개발되었지만, 지금은 검색엔진을 넘어 보안, 로그 분석, 위치 기반 정보 데이터 분석 등 다양한 분야에서 활용되고 있다. 또한 Logstash, Kibana, Beat와 함께 ELK Stack으로 다양한 전문 분야에 활용된다.
Elasticsearch를 통해 방대한 양의 데이터를 신속하게(near real-time) 저장, 검색, 분석을 수행할 수 있다.
아래 서치엔진 인기순위를 보면 Elasticsearch가 얼마나 많이 사용되는지 짐작할 수 있을 것이다.
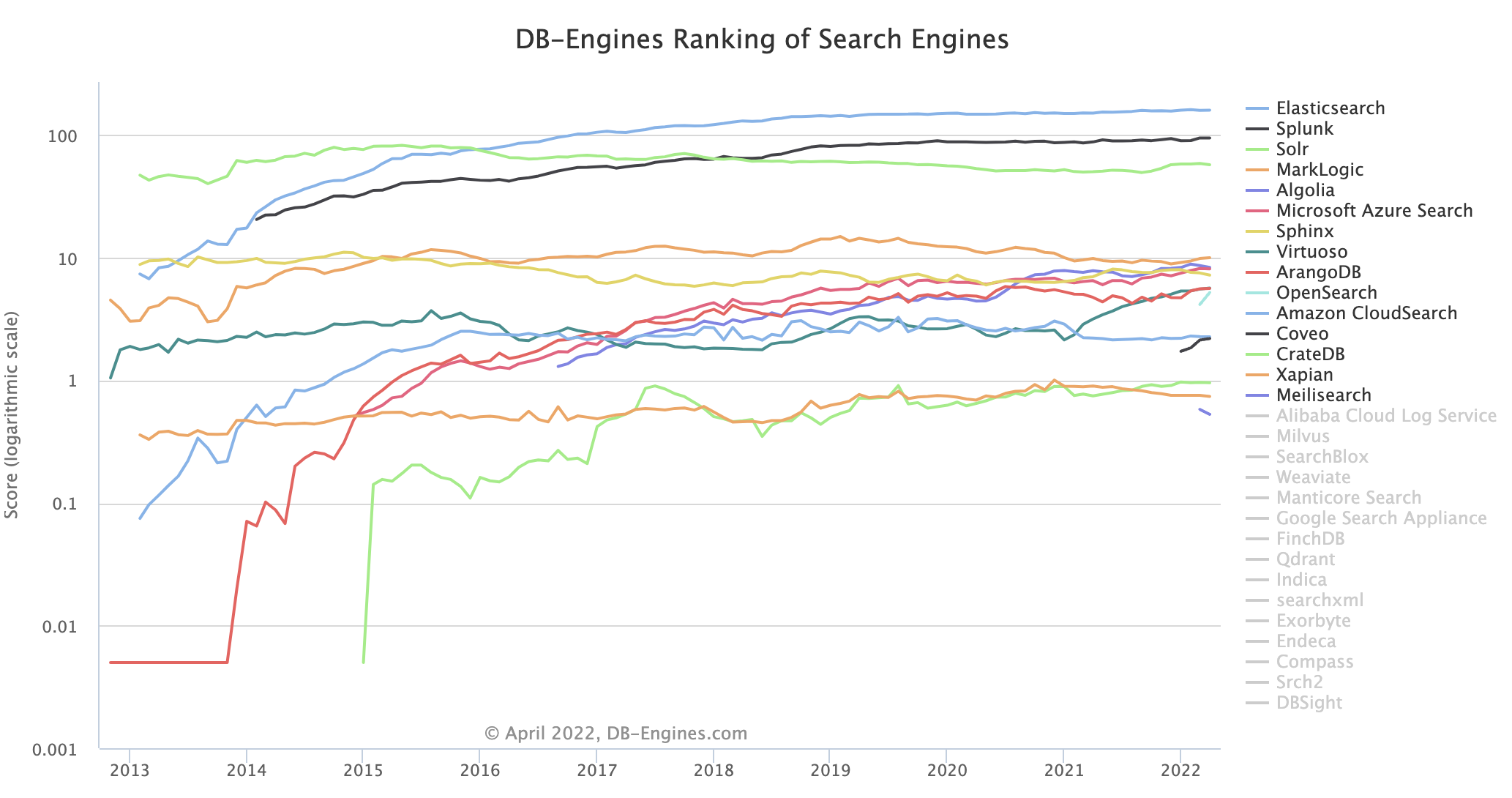 ▲ Trend of Search Engines Popularity (2022.04)
▲ Trend of Search Engines Popularity (2022.04)
Elasticsearch의 사용
Elasticsearch의 속도와 확장성, 그리고 수많은 종류의 콘텐츠를 색인할 수 있는 능력은 다음과 같은 다양한 사용 사례에 이용될 수 있다는 뜻이다.
애플리케이션, 웹사이트, 엔터프라이즈 검색부터, 로그 데이터 분석, 애플리케이션 성능 모니터링, 위치 기반 정보 데이터 분석 및 시각화 등에 사용된다.
Elasticsearch의 특징 / 장점
- 오픈소스 검색엔진
엘라스틱서치는 아파치 루씬(Lucene)을 기반으로 개발된 오픈소스 검색엔진이다. 6.3 버전부터는 x-pack은 Elastic 라이선스이지만 나머지는 Apache 라이선스이다.
- 빠르다, Near real-time
Lucene을 기반으로 구축되었기 때문에, Full-text 검색에 뛰어나다. 모든 데이터를 역색인 구조로 저장해 가공된 텍스트를 검색한다. 거의 실시간 검색으로 사용할 수 있기 때문에 보안 분석, 인프라 모니터링 같은 사용 사례에 적합하다.
-
역색인
역색인 구조로 특정 단어를 찾을 때 문서 전체가 아닌 단어를 포함한 특정 문서의 위치를 찾기 때문에 빠르다. 역색인은 특정 단어를 포함한 문서들을 저장해둬서 특정 단어를 찾을 때 저장된 문서 목록을 확인한다. -
Restful API
데이터 CRUD 작업을 HTTP Restful API를 통해 수행할 수 있다. 요청/응답에 JSON을 사용하기 때문에 다양한 플랫폼에서 활용이 가능하다.
-
Multi-tenancy
Elasticsearch는 데이터를 인덱스 단위로 분산해 저장한다. 서로 다른 저장소에 분산되어 있는 여러 인덱스에서 하나의 쿼리로 묶어서 검색하고 하나의 결과를 도출할 수 있다.
-
광범위한 기능
속도, 확장성, 복원력뿐 아니라, Elasticsearch에는 데이터 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 강력한 기본 기능이 다수 탑재되어 있다.
-
데이터 시각화
Kibana와 연동하여 사용할 수 있다. Kibana는 Elasticsearch 데이터의 실시간 시각화를 제공한다.
-
Scale out
샤드를 통해 규모가 수평적으로 늘어날 수 있다. (Vertical Scaling은 CPU 및 CPU Cores를 늘리거나, 메모리, 저장장치 등을 늘려서 한대의 서버의 성능을 올리는 것을 말하며 Horizontal Scaling은 같은 타입의 서버들을 분산하여 늘리는 방식으로 비용적인 측면과 확장적인 측면에서 일반적으로 Vertical 방식보다 효율적이고 효과적이다.)
-
고가용성
Elasticsearch는 동작 중에 죽은 노드를 감지하고 삭제하며 사용자의 데이터를 안전하게 접근 가능하도록 유지하기 때문에, 동작 중에 일부 노드에 문제가 생기더라도 문제 없이 서비스를 제공한다.
-
Schema Free
Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없다. 비정형 데이터는 비구조적이고, 스키마가 다이나믹하게 변할 수 있기 때문에 JSON 구조가 적합하다.
Elasticsearch의 단점
-
실시간이 아니다.
빠르지만 완전한 실시간은 아니다. Near real-time이다. ES는 데이터 저장 시점에 해당 데이터를 색인(Indexing)한다. -
트랜잭션과 롤백 기능이 없다.
전체적인 클러스터의 성능 향상을 위해서 시스템적으로 비용 소모가 큰 롤백과 트랜잭션을 지원하지 않는다. 즉 트랜잭션과 무결성이 중요한 데이터의 저장소로 사용하기에 적합하지 않다. Elasticsearch가 DB의 기능도 하지만 메인 데이터베이스로 단독 사용하는 것은 권장되지 않는다.
-
데이터 UPDATE를 제공하지 않는다.
결과적으로는 업데이트가 가능하지만 ES에서의 업데이트는 기존 문서를 삭제하고 다시 삽입하는 방식이다.
다음 글에서는 로그 수집, 분석, 모니터링에 널리 사용되는 ELK Stack에 대해 알아보자!
https://www.elastic.co/kr/what-is/elasticsearch
https://www.elastic.co/kr/what-is/elk-stack
https://esbook.kimjmin.net/
