
Medical-VQA 관련 연구를 진행하기 앞서, 벤치마크 데이터셋과 모델들에 대해 정리해보았다.
Benchmark Datasets
우선, 간단하게 표로 정리해본 바는 다음과 같다.
| Dataset | Images | QA pair | Open-Ended | Closed-Ended | Domain | Question Type |
|---|---|---|---|---|---|---|
| VQA-RAD | 315 | 3,515 | 43.1% | 56.9% (yes/no, multiple choice) | Radiology | Modality, Plan, Organ System, Abnormality, Presence, Position, Color, Size, Attribute Other, Counting, Other |
| PathVQA | 4,998 | 32,779 | 50.2% | 49.8% (Yes/No) | Pathology | |
| PMC-VQA | 149K | 227K | What, Which | Multiple Choice | Various (80% radiology) | |
| VQA-Med (2019) | 4200 | 15292 | WH | Yes/No, Closed-Ended | Radiology | Modality, Plane, Organ system, Abnormality |
| VQA-Med (2021) | 5,500 | 5,500 | Radiology | Abnormality | ||
| SLAKE | 642 | 14,028 (English & Chinese) | O | O | Radiology (MRI, CT, X-Ray) | Plane, Quality, Modality, Position, Organ, KG, Abnormal, Color, Shape, Size |
| MIMIC-Ext-CXR | 133,687 | 377,391 | Query | Yes/No , Choose | Chest X-Ray | Presence, Anatomy, Attribute, Abnormality, Size, Plane, Gender |
| OmniMedVQA | 118,010 | 127,995 | Majority | Minority | 12 modalities (MRI, CT, X-Ray, pathology, etc.) | Modality Recognition, Anatomy Identification, Disease Diagnosis, Lesion grading, Other Biological Attributes |
| GEMeX | 151,025 | 1.6M | WH | Yes/No, Multiple & Single Choice | Chest X-Ray (with explainability) | |
| MIMIC-Diff-VQA | 164,324 | 1.3M | WH | Yes/No | Chest X-Ray | Abnormality, Presence, View, Location, Level, Type, Difference |
평가 시에 대부분 Open-Ended에 대해서는 BLEU, Recall, ACC 등을, Closed-Ended에는 ACC를 주로 활용하는 것으로 보인다. 데이터셋별로 링크를 달아두었으니, 다운로드 및 자세한 내용은 링크에서 확인하면 된다.
Benchmark Models
아래는 대표적인 논문들의 성능을 대표적인 데이터셋 3가지, SLAKE, PathVQA, VQA-RAD에 대한 성능 비교 표 (논문에 게재된 수치)이다.
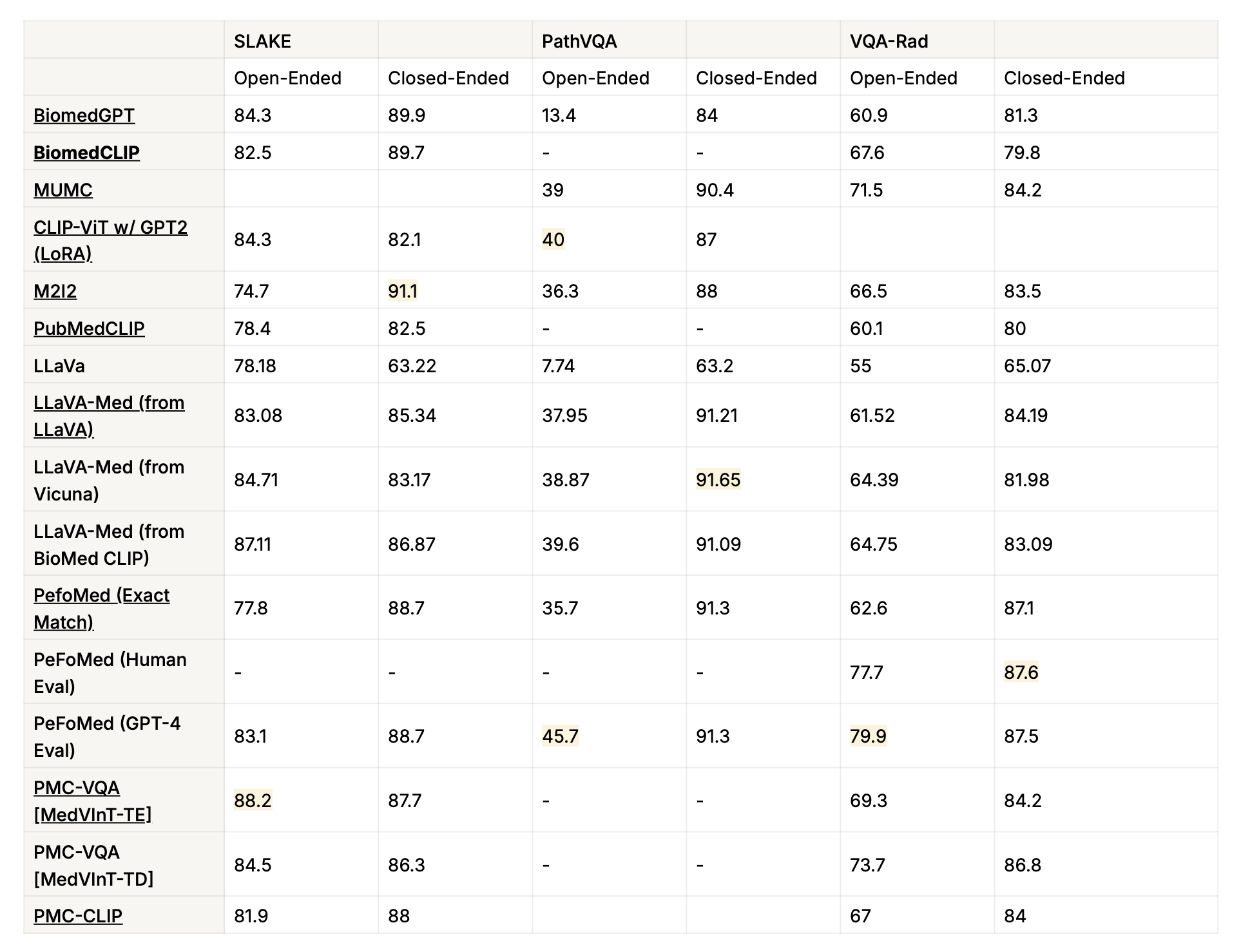
위 논문들과 이외에도 참고하기 좋을만한 논문들을 남긴다.
[BiomedGPT] A generalist vision–language foundation model for diverse biomedical tasks (Nature 2024, Zhang et al.)
[BiomedCLIP] BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs (2023, Zhang et al.)
[MUMC] Masked Vision and Language Pre-training with Unimodal and Multimodal Contrastive Losses for Medical Visual Question Answering (MICCAI 2023, Li et al.)
[CLIP-VIT w/ GPT-2] Open-Ended Medical Visual Question Answering
Through Prefix Tuning of Language Models (MICCAI 2023, Van Sonsbeek et al.)
[M2I2] Self-supervised vision-language pretraining for Medical visual question answering (ISBI 2023, Li et al.)
[PubMedCLIP] How Much Does CLIP Benefit Visual Question Answering in the Medical Domain? (EACL 2023, Eslami et al.)
[LLaVA-Med] Training a Large Language-and-Vision Assistant for Biomedicine in One Day (Neurips 2023 Datasets and Benchmarks Track Spotlight, Li et al.)
[PefoMed] Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging (arXiv 2024, Liu et al.)
[PMC-VQA] Visual Instruction Tuning for Medical Visual Question Answering (arXiv 2023, Zhange et al.)
[PMC-CLIP] Contrastive Language-Image Pre-training using Biomedical Documents (arXiv 2023, Lin et al.)
