Fine-grained Adaptive Visual Prompt for Generative Medical Visual Question Answering (AAAI 2025, Yu et al.)
1. Introduction
의료 영상 기반 질의응답(Medical Visual Question Answering, MedVQA)은 환자 질의 응답 지원이나 의사의 진단 보조에 활용될 수 있는 중요한 멀티모달 AI 응용 분야이다. 그러나 기존 방식은 언어 프롬프트만으로는 장기별 정밀한 위치 파악이 어렵고, background noise에 의해 정확도가 저하되는 문제가 있었다.
본 논문은 이러한 한계점을 극복하기 위해 이전 블로그에서 다룬 MedVP와 비슷하게 시각 프롬프트 (visual prompt) 를 도입한 논문으로 AAAI 2025에서 발표된 논문이다.
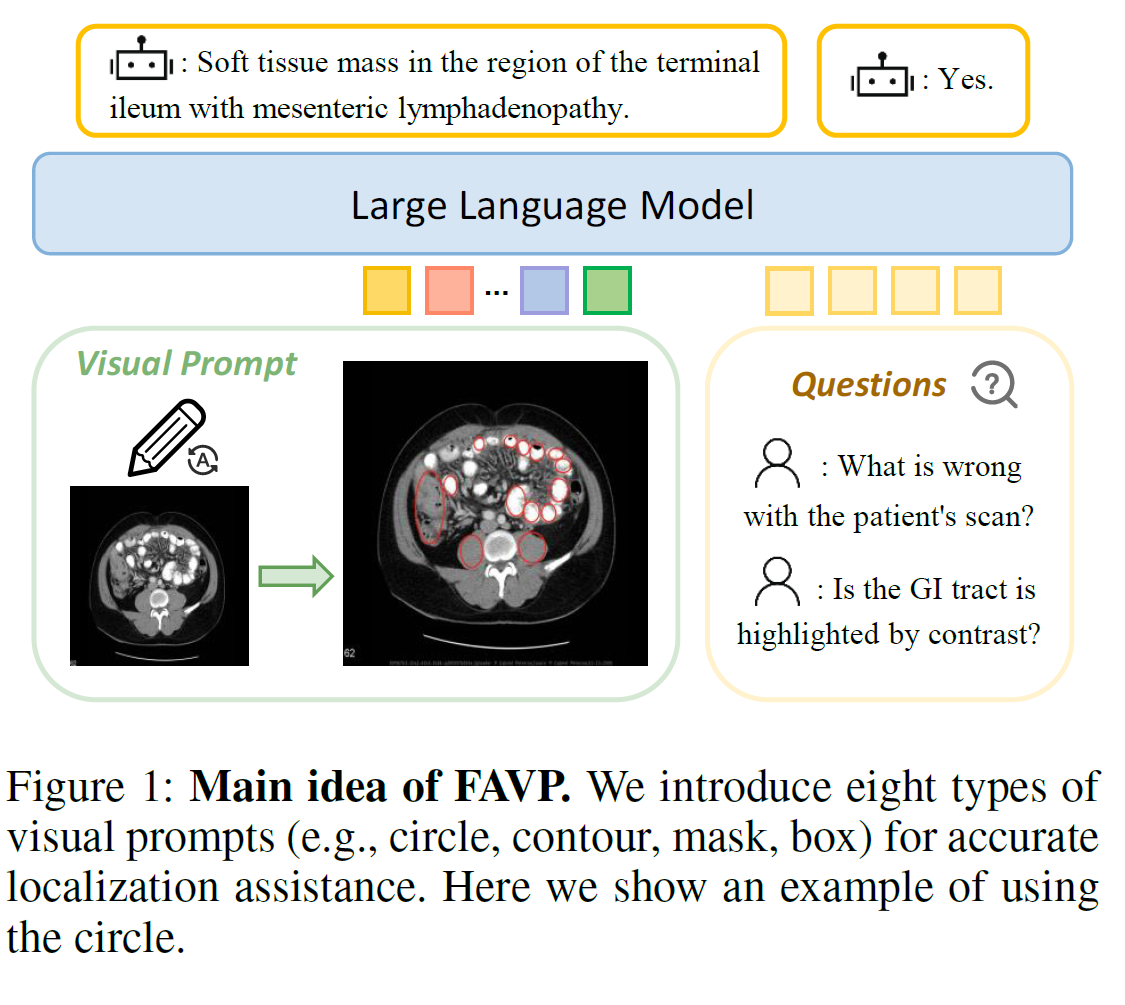
2. 연구 배경
- MedVQA Task 특성
- X-ray, CT, MRI 등 의료 영상을 기반으로 질문에 답하는 task로 크게 두 갈래, discriminative와 generative method 기반의 모델들이 개발되고 있다.
- 기존의 discriminative 모델은 closed-set 질문에서는 좋은 성능을 보이지만 open-set 질문에 대해 제한적인 성능을 보이곤 한다.
- Generative 모델은 zero-shot 상황에서도 좋은 transfer ability를 보이고 open-set 질문에 대해서도 잘 답할 수 있지만, 크게 두 가지의 한계가 존재한다.
1. 영상의 세밀한 병변 위치를 짚는 데 한계가 있다.
2. 또한, LLM 모델은 대규모 파라미터 사이즈를 요구하고 학습 시간도 매우 길어 full fine-tuning은 parameter inefficient하다.
3. Proposed Method : FAVP
FAVP는 두 가지 주요 모듈로 구성된다.
1. Adaptive Visual Prompt Creator (AVPC)
2. Hierarchical Answer Generator (HAG)
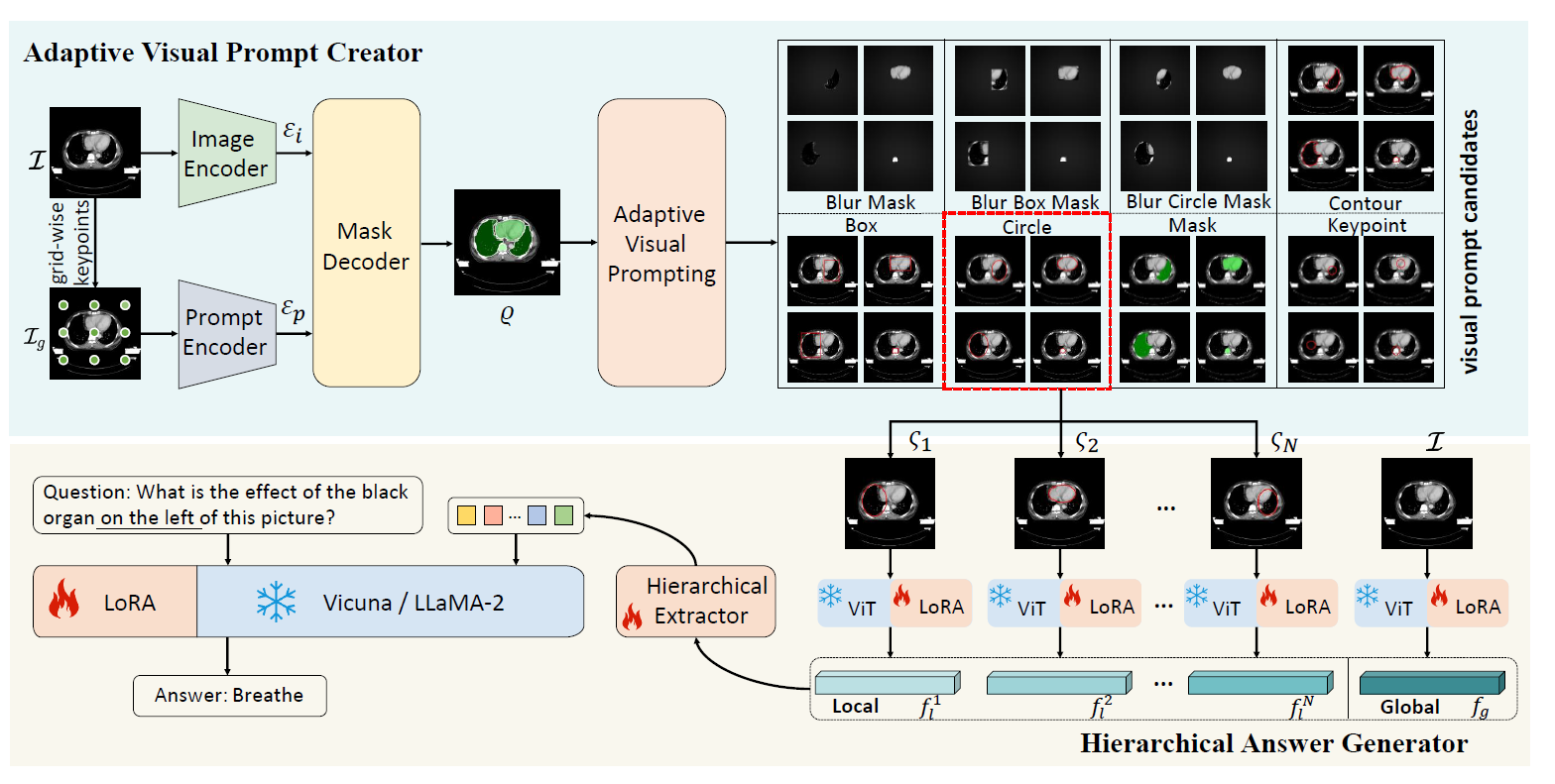
3.1. Adaptive Visual Prompt Creator (AVPC)
AVPC는 입력 의료 영상에서 장기·병변 영역을 자동으로 탐지하고 시각 프롬프트를 생성하는 모듈이다. 핵심은 언어 프롬프트만으로는 부족한 “위치 정보”를 LLM에 제공한다는 점이다.
-
입력
원본 이미지:여기서 는 각각 높이, 너비, 채널 수를 의미한다.
-
Step 1: Keypoint 기반 증강
영상 위에 균일한 격자(grid) keypoints를 생성해 증강된 이미지 를 얻는다. -
Step 2: 이중 인코딩
원본 영상과 증강 영상을 각각 (Image Encoder), (Prompt Encoder)로 encoding한다. -
Step 3: Global Mask 추출
SAM-Med2D 모델로 global mask 를 생성:: NMS(Non-Maximum Suppression) threshold → 마스크의 중복 제거 및 품질 결정
-
Step 4: Local Mask 분할 & 프롬프트 후보 생성
각 local mask는 장기/병변 단위 세분화 → 박스, 원, 마스크, 컨투어 등 다양한 프롬프트 후보로 변환
최종적으로 dataset 특성에 가장 적합한 프롬프트 유형을 선택해 HAG로 전달
해당 모듈의 경우 NIPS 2023 paper인 Fine-Grained Visual Prompting (Yang et al.)과 유사한 프로세스를 따르는 것으로 보인다. 자세한 내용은 해당 논문을 참고하면 좋을 것 같다.
3.2. Hierarchical Answer Generator (HAG)
HAG는 AVPC가 생성한 로컬 프롬프트와 글로벌 특징을 통합하여 LLM이 답변을 생성할 수 있게 한다.
-
Step 1: ViT 기반 특징 추출
: 로컬 장기/병변 단위 특징
: 전체(global) 영상 특징 -
Step 2: 특징 결합
여기서 는 concat 연산
-
Step 3: Hierarchical Extractor (Q-Former + Linear)
결과 : 언어 공간과 정렬된 시각 토큰
-
Step 4: LLM 기반 답변 생성
-
Step 5: 학습 목표 (Cross-Entropy Loss)
여기서 : 학습 가능한 파라미터
3.3 학습 과정
FAVP는 3단계 학습 전략을 따른다.
- Stage 1 (ROCO 데이터셋): 이미지 캡셔닝 기반 사전학습, cross-modal alignment 수행
- Stage 2 (PMC-VQA): 대규모 의료 QA 데이터로 학습, 표현력 확장
- Stage 3 (VQA-RAD, SLAKE, DME): 최종 파인튜닝 및 평가
4. 실험
- 데이터셋: VQA-RAD, SLAKE, DME
- 평가 지표: Recall (Open-set) / Accuracy (Closed-set)
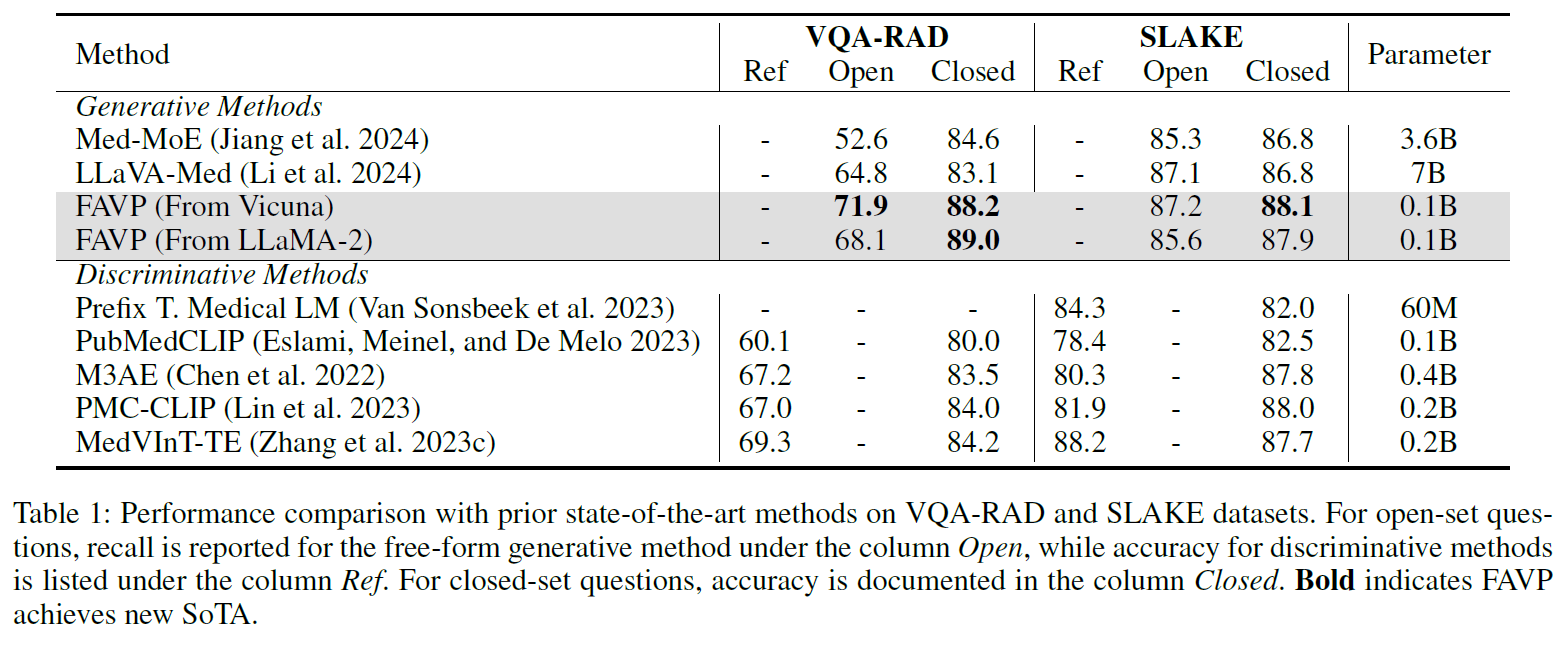
- VQA-RAD, SLAKE에서 SOTA 성능을 달성함과 동시에 특히 VQA-RAD에서 큰 성능 향상을 보임
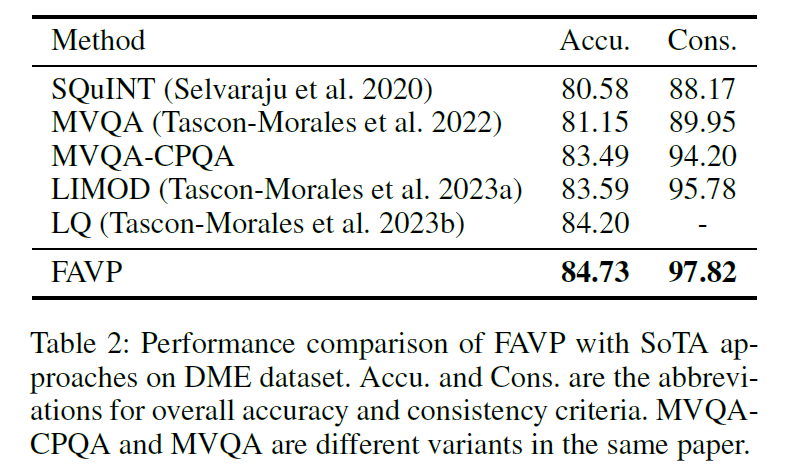
- DME 데이터셋에서는 Accuracy 84.73%, Consistency 97.82%로 SOTA 달성
- 파라미터 수는 기존 대비 1/70 수준임에도 성능 우위 확보
5. Ablation Study
(1) LoRA Rank
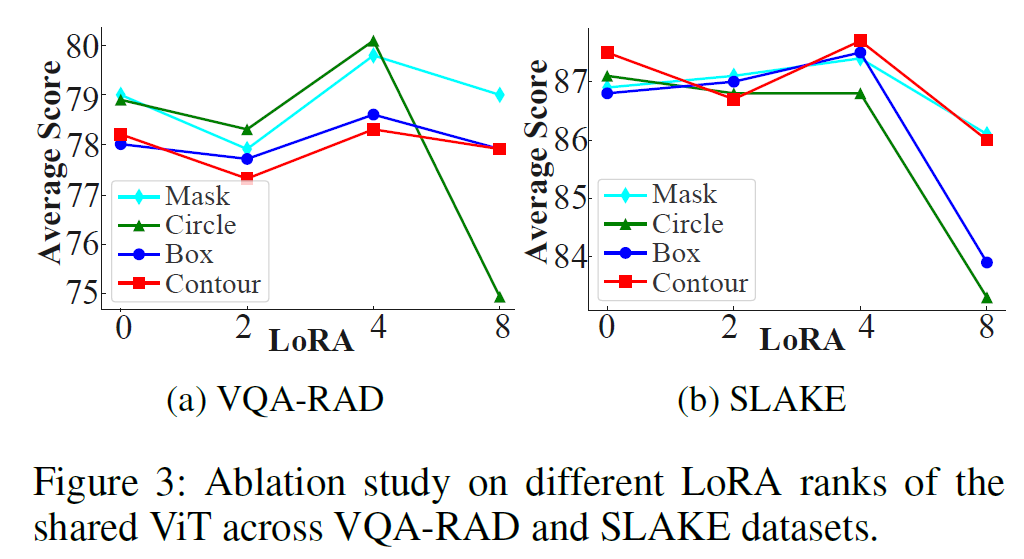
- [ViT] rank=4일 때 최적
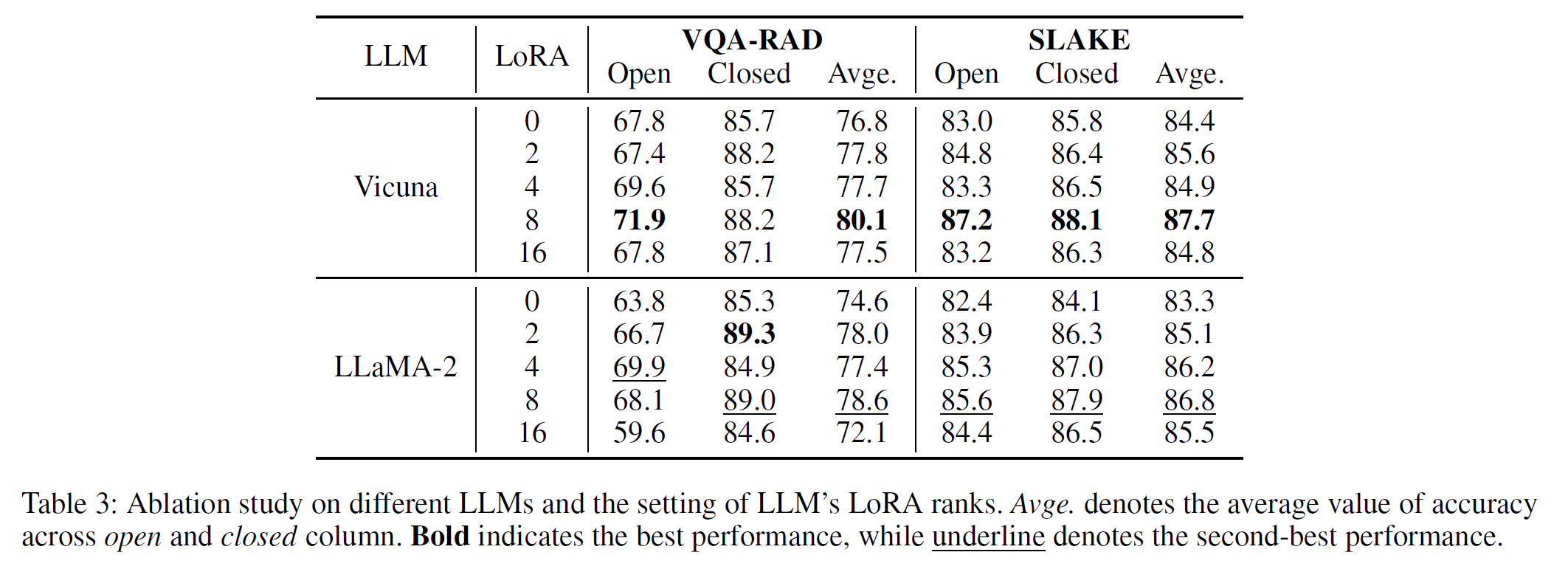
- [LLM(Vicuna/LLaMA-2)] rank=8일 때 최적
(2) Prompt 유형 비교
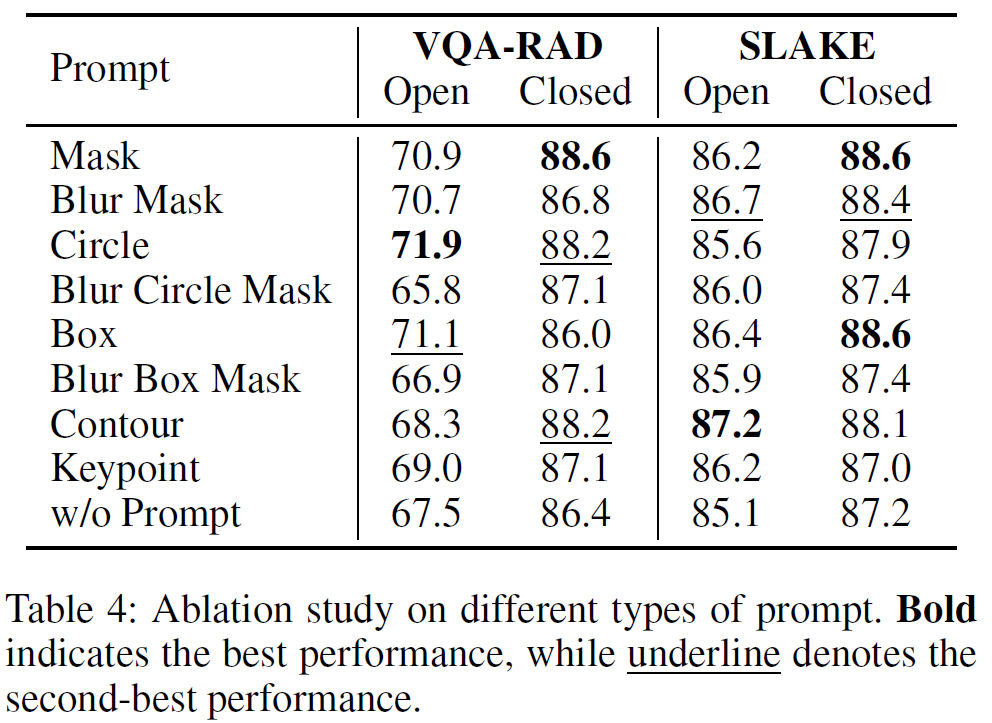
- Circle, Contour가 VQA-RAD, SLAKE 각각에서 가장 높은 성능
- 데이터셋 특성에 따라 최적 프롬프트 달라진다고 하지만 생각보다 visual prompt type에 따라 성능 차이가 많이 나는데 그런 결과에 대한 이유 관련 논의는 따로 없음.
(3) Training Stages
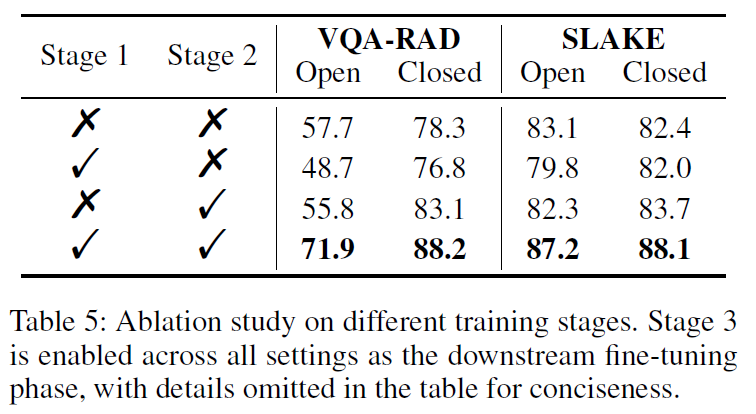
- Stage 1, Stage 2 모두 포함해야 최적 결과
- 단일 Stage만 사용 시 성능 저하 발생
6. 결론
-
FAVP
- MedVQA 최초의 시각 프롬프트 기반 프레임워크
- 정밀한 위치(localization) 인식 + 생성형 답변 결합
- 파라미터 효율적 학습(PEFT)으로 경량화와 성능을 동시에 확보
-
한계
- PET, 유방촬영, 병리 영상 등에서 검증 부족
- 현재 평가 지표(Recall)가 정밀 위치 기술을 완전히 반영하지 못함
-
향후 연구 방향
- Zero-shot 성능 강화
- 더 다양한 modality 확장 및 임상 적용 검증
