이전 B트리 포스팅에 이어서 B+트리에 대해 포스팅 해보겠습니다. 동작 방식은 B트리와 굉장히 유사하지만 다른점이라고 하면 리프노드는 연결리스트의 형태를 띄어 선형 검색이 가능하다는 점입니다. 이러한 특징점 때문에 굉장히 작은 시간복잡도에 검색을 수행할 수 있습니다. 이전 B트리 포스팅에서 삽입 & 삭제 과정을 자세히 설명했기 때문에 이번 포스팅에서는 B트리와 B+트리의 차이점 위주로 설명해 보겠습니다.
B+Tree?
실제 DB의 인덱싱은 B+트리로 이루어져있다고 합니다. 다음 그림은 인덱싱을 나타낸 것입니다. 인덱싱은 어떠한 자료를 찾는데 key값을 이용해 효과적으로 찾을 수 있는 기능입니다.
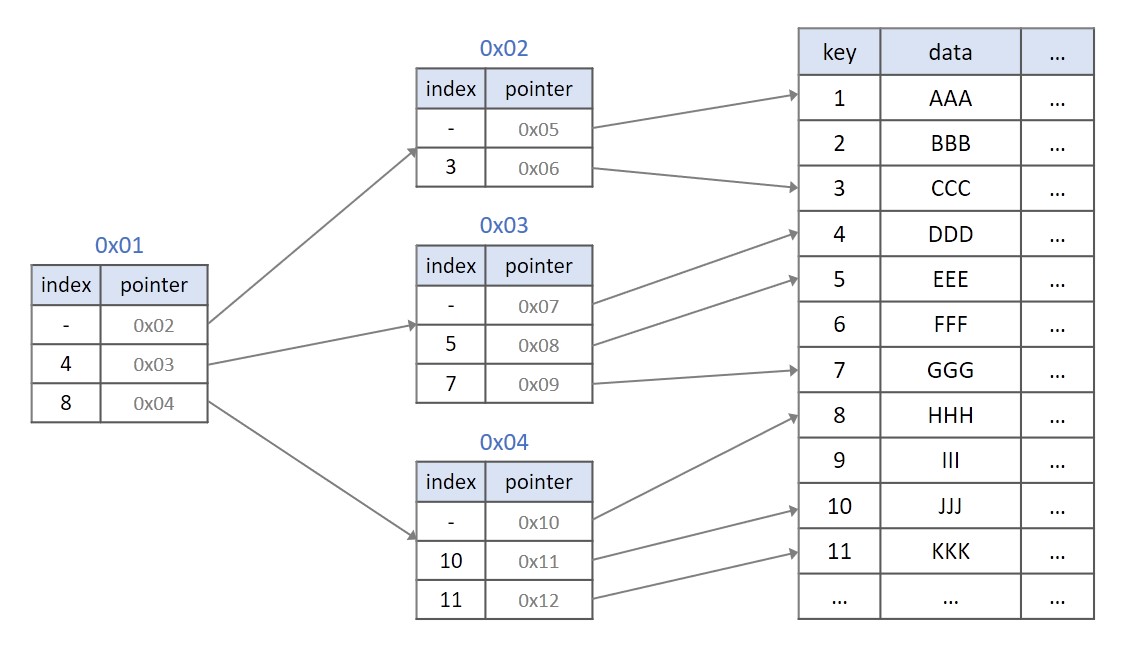
다음과 같은 인덱싱을 B+트리로 나타내면 아래 그림과 같습니다.
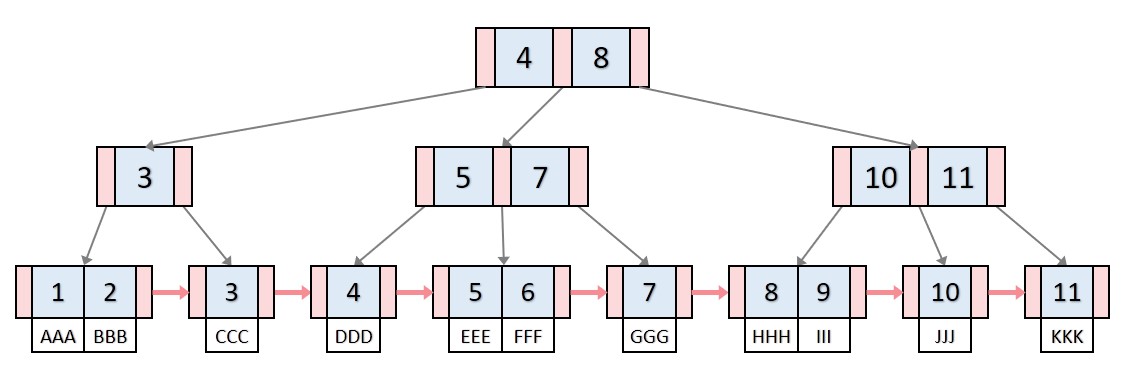
B+트리에는 리프노드에 새로운 data값들이 들어가 있습니다. B트리의 경우에는 편의상 data를 생략하여 그렸지만, 각 key값이 data를 가지고 있었다고 생각하면 되겠습니다. 그럼 B트리와 B+트리 달라진 점에 대해서 알아보겠습니다.
-
모든 key, data가 리프노드에 모여있습니다. B트리는 리프노드가 아닌 각자 key마다 data를 가진다면, B+트리는 리프 노드에 모든 data를 가집니다.
-
모든 리프노드가 연결리스트의 형태를 띄고 있습니다. B트리는 옆에있는 리프노드를 검사할 때, 다시 루트노드부터 검사해야 한다면, B+트리는 리프노드에서 선형검사를 수행할 수 있어 시간복잡도가 굉장히 줄어듭니다.
-
리프노드의 부모 key는 리프노드의 첫번째 key보다 작거나 같습니다. 그림의 B+트리는 리프노드의 key들을 트리가 가지고 있는 경우여서, data 삽입 또는 삭제가 일어날 때 트리의 key에 변경이 일어납니다. 해당 경우뿐만 아니라 data의 삽입과 삭제가 일어날 때 트리의 key에 변경이 일어나지 않게 하여 더욱 편하게 B+트리를 구현하는 방법도 존재하기 때문에 작거나 같다라는 표현을 사용하였습니다.
B트리와 같이 차 B+트리는 다음과 같은 특징을 같습니다.
- 노드는 최대 개 부터 개 까지의 자식을 가질 수 있습니다.
- 노드에는 최대 개 부터 개의 키가 포함될 수 있습니다.
- 노드의 키가 개라면 자식의 수는 개 입니다.
- 최소차수는 자식수의 하한값을 의미하며, 최소차수가 라면 을 만족합니다. (최소차수 가 2라면 3차 B트리이며, key의 하한은 1개입니다.)
key 삽입과정
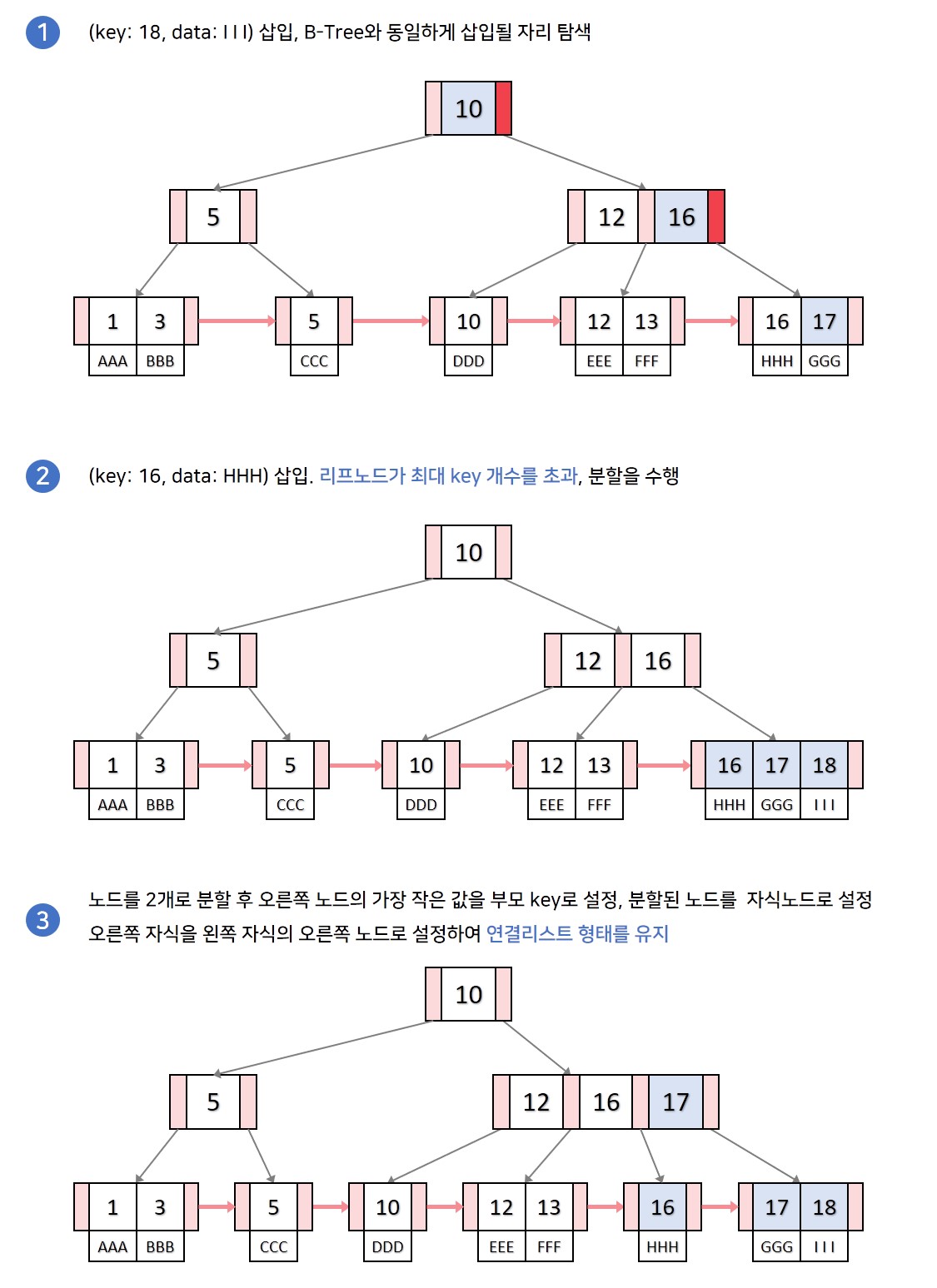
모든 설명의 과정은 리프노드가 삽입 또는 삭제 될 때 트리의 key가 변경되는 경우로 진행하겠습닏. 검색과정은 B트리와 동일하기 때문에 생략하고 삽입의 과정부터 시작하겠습니다. 삽입의 과정도 B트리와 매우 유사하지만 리프노드에서 최대 key개수를 초과할 때가 다릅니다.
💡Case 1. 분할이 일어나지 않고, 삽입 위치가 리프노드의 가장 앞 key 자리가 아닌 경우
B트리와 똑같은 삽입 과정을 수행합니다.
💡Case 2. 분할이 일어나지 않고, 삽입 위치가 리프노드의 가장 앞 key 자리인 경우
삽입 후 부모 key를 삽입된 key로 갱신하고, data를 넣어줍니다.
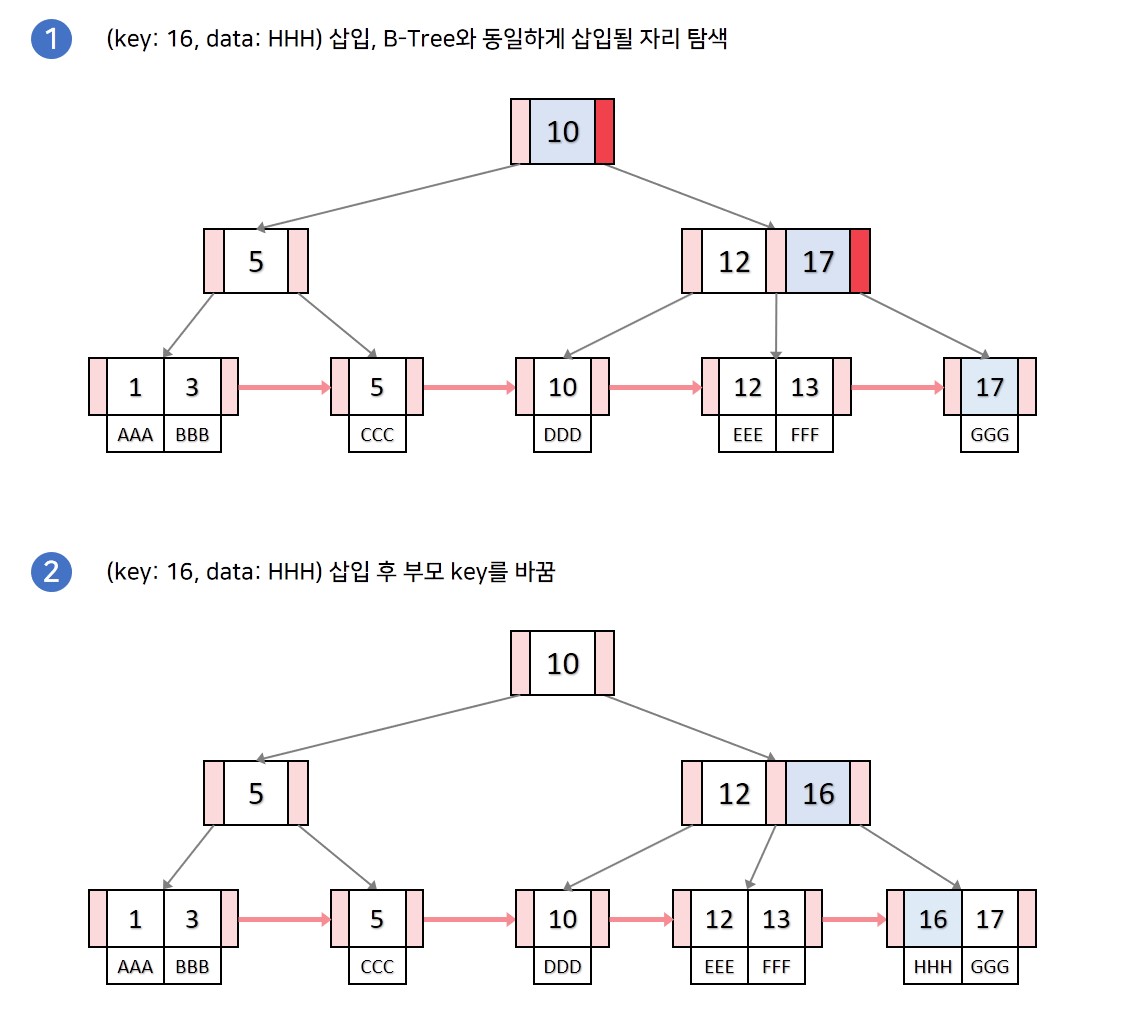
💡Case 3. 분할이 일어나는 삽입과정
-
분할이 일어나는 노드가 리프노드가 아니라면 기존 B트리와 똑같이 분할을 진행합니다. 중간 key를 부모 key로 올리고, 분할한 두개의 노드를 왼쪽, 오른쪽 자식으로 설정합니다.
-
분할이 일어나는 노드가 리프노드라면 중간 key를 부모 key로 올리지만, 오른쪽 노드에 중간 key를 포함하여 분할합니다. 또한 리프노드는 연결리스트이기 때문에 왼쪽 자식노드와 오른쪽 자식 노드를 이어줘 연결리스트 형태를 유지합니다. 해당 부분이 B트리의 분할과 다른 점입니다.
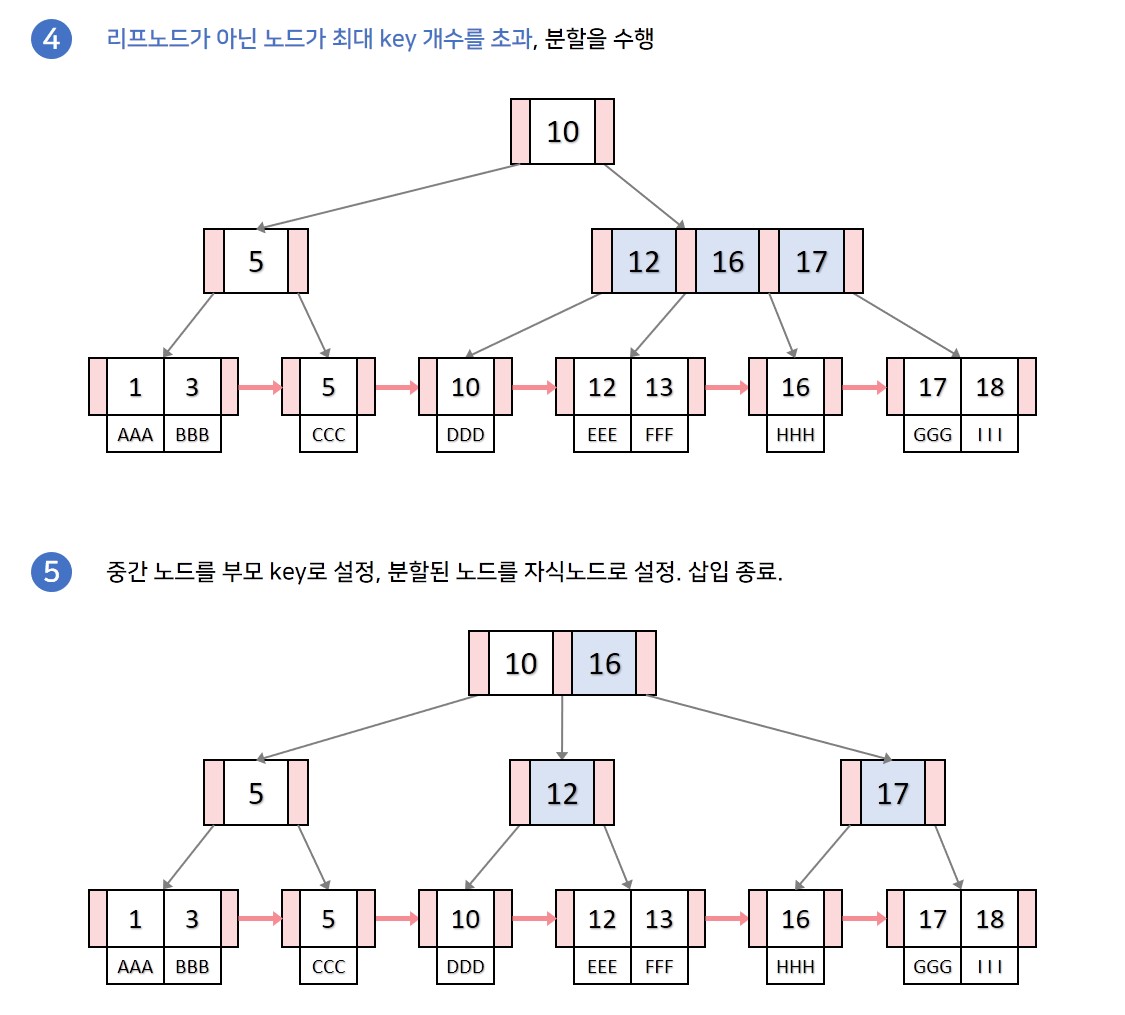
key 삭제과정
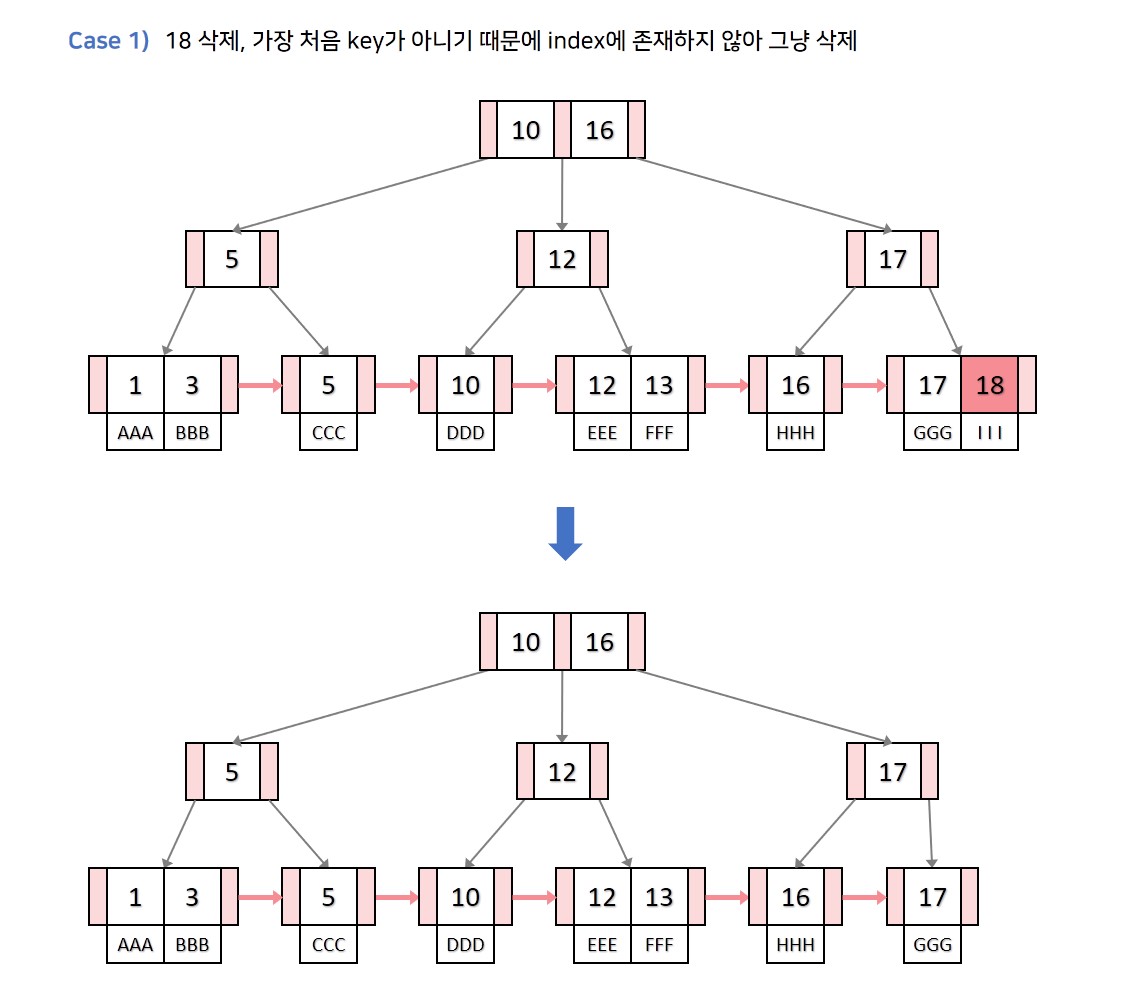
삭제과정 역시 기존 B트리와 유사합니다만 삭제할 key 는 무조건 리프노드에 존재하는 점, 를 삭제하기 위해 검색하는 과정에서 index에 존재할 수 있다는 점이 다릅니다. 해당 부분을 위주로 삭제 과정을 적어보겠습니다.
💡 Case 1. 삭제할 key k가 index에 없고, 리프노드의 가장 처음 key가 k가 아닌경우
기존의 B트리 삭제과정과 동일합니다.
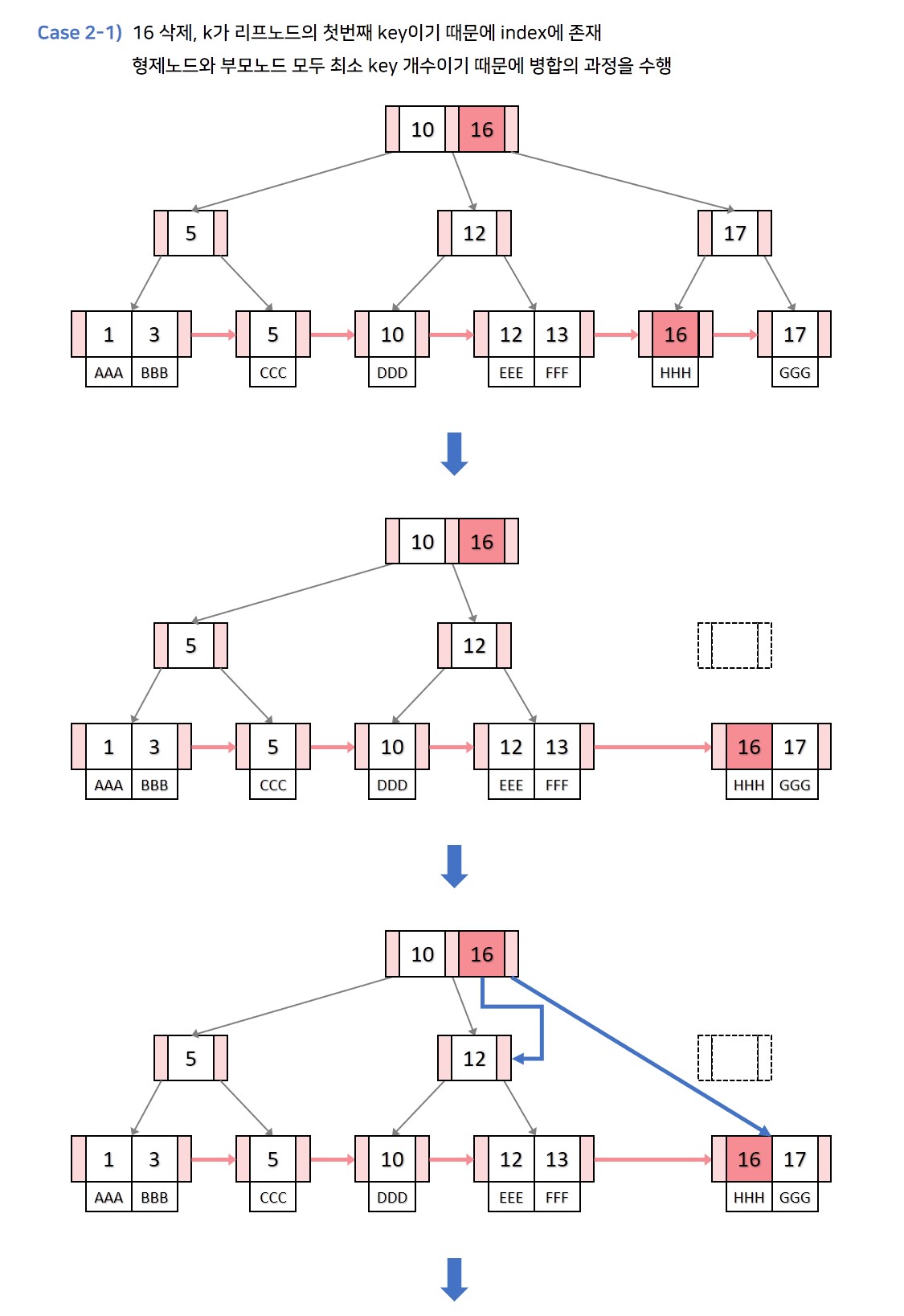
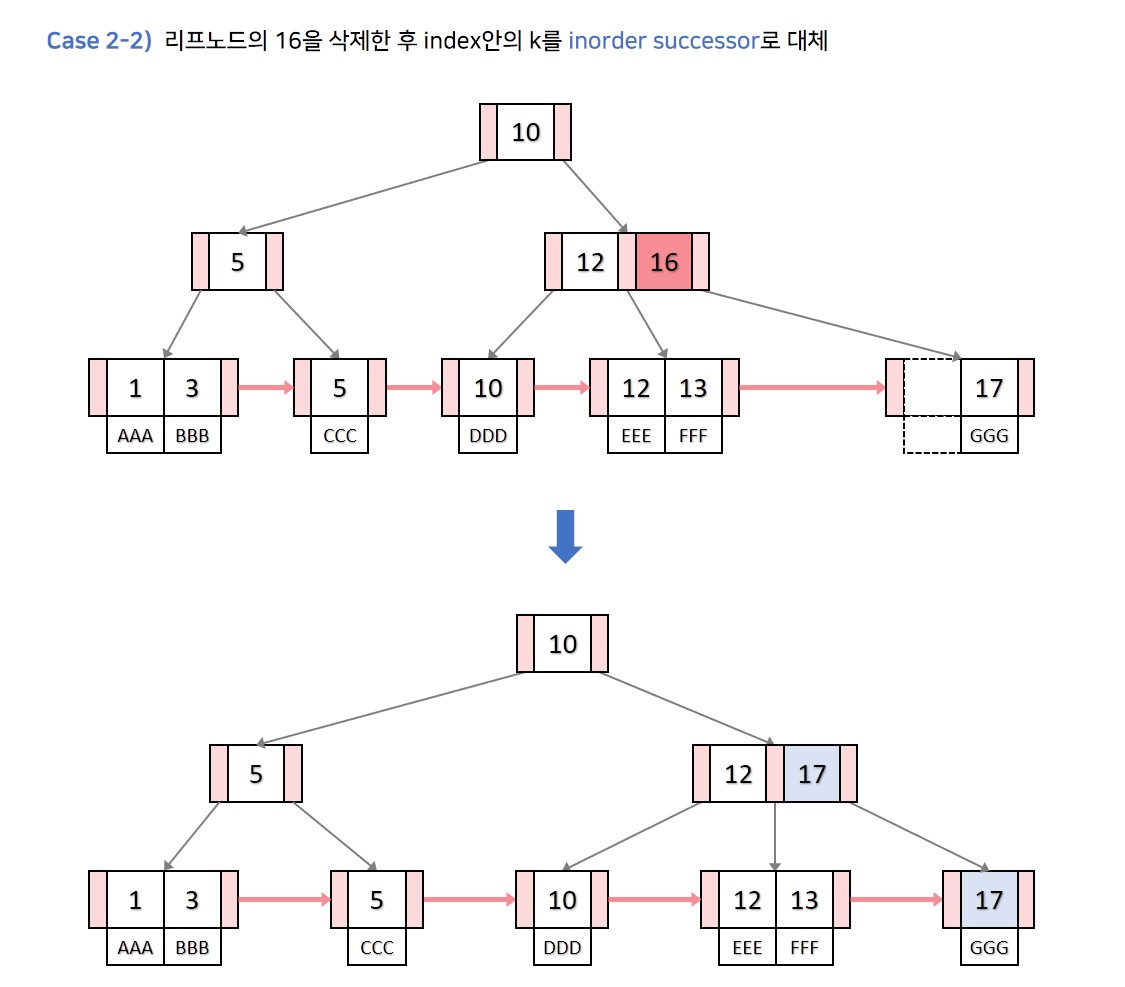
💡 Case 2. 삭제할 key k가 리프노드의 가장 처음 key인 경우
삭제할 key 가 리프노드의 가장 처음 key인 경우에는 항상 가 index 내에 존재합니다.
-
먼저 리프노드의 를 삭제하는 과정을 수행합니다. key의 개수가 최소 key의 개수라면 B트리의 삭제 과정 중 형제노드의 key를 빌려오는 경우나 부모key와 병합하는 등 과정들은 동일하게 수행합니다. 단, 리프노드가 병합할 때는 부모key와 오른쪽 자식의 처음 key가 동일하기 때문에 부모key를 가져오는 과정만 생략하고 왼쪽 자식과 오른쪽 자식을 병합만 하면 됩니다.
-
리프노드의 k를 삭제한 후, index내의 를
inorder successor로 변경합니다.
마치며
이상으로 실전에 사용하는 자료구조인 B트리와 B+트리를 포스팅을 마무리 하겠습니다. 난이도가 있는 자료구조인 만큼 설계를 꼼꼼히 진행하는것이 중요할 것 같습니다.

8개의 댓글



글 너무 잘 읽었습니다!
그런데 삽입 과정 case 2 에서 (key : 16, data : HHH) 를 넣을 때 왜 17의 오른쪽으로 넣는거죠? 12와 17 사이로 들어가야 한다고 생각했는데 왜 17 의 오른쪽으로 위치가 정해지는지 모르겠네요 ㅠㅠ
많은 도움이 되었습니다 감사합니다.