
메모리 동적할당에 대해 포스팅 해보겠습니다. C언어의 malloc을 기준이며, 동적 할당의 여러 방법에 대한 포스팅입니다. 해당 과정은 32bit 시스템을 기준으로 작성하겠습니다.
메모리 동적할당(Dynamic Memory Allocator)?
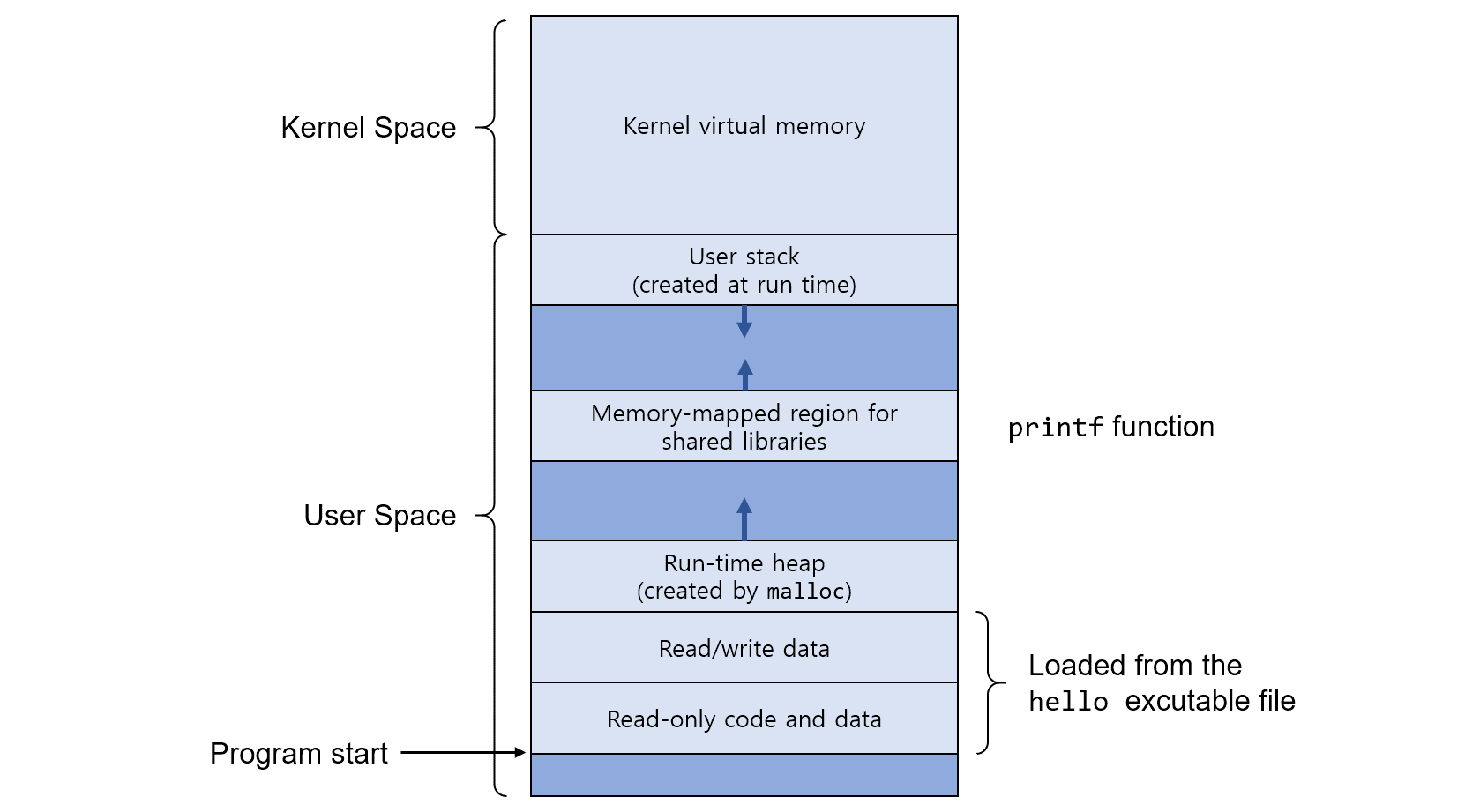
C언어에서 변수와 함수를 선언하고 사용하는 과정에서 이들을 저장하기 위한 메모리를 사용하게 됩니다. 많이 알고있듯이 작성자가 정의한 변수와 함수는 스택(Stack)영역에 저장되고, 함수가 호출되면 스택영역의 메모리를 사용하며 커지게 되고, 리턴되면 줄어드는 방식으로 작동하게 됩니다.
작성자가 예상하지 못하는, 사용자가 필요한 만큼의 메모리를 프로그램이 작동하는 도중에 할당받고자 한다면 어떻게 해야 할까요? 이럴때 사용하는 방법이 메모리 동적할당이라고 할 수 있습니다. 동적 할당된 메모리는 힙(Heap)영역에 malloc과 free를 사용하여 할당되고 해제됩니다. 힙 영역을 그림으로 표현하자면 다음과 같습니다.

각 칸을 4바이트 차이만큼 표시한 이유는 32bit 시스템의 경우에는 포인터의 사이즈가 4byte이기 때문입니다. 각 칸에 블록의 사이즈나 포인터를 저장하는 경우가 많기 때문에 다음과 같이 4byte단위로 표현하였습니다.
파란색 부분은 할당된 부분, 흰색 부분은 할당이 해제된 부분입니다. 그림은 할당된 부분과 해제된 부분이 차례로 그려졌지만, 할당된 부분들은 얼마든지 연속적으로 붙어있거나 떨어져있을 수 있습니다. 단, 할당이 해제된 부분은 단편화 문제를 해결하기 위해 연속적으로 존재할 수 없습니다.
단편화(fragmentation)?
그렇다면 단편화는 무엇일까요? 단편화는 쉽게 생각하면 사용하지 않거나 사용하지 못하는 메모리가 쌓여서 메모리 누수를 유발할 수 있는 경우들입니다.
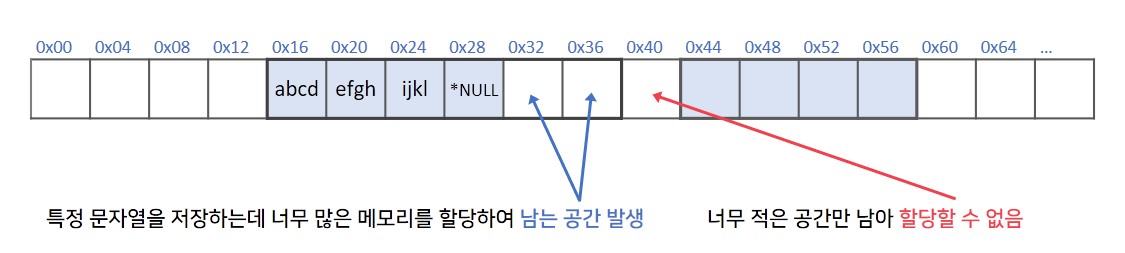
- 내부 단편화: 필요한 메모리 만큼 이상의 메모리를 할당해서 할당된 메모리 내에 비어있는 메모리가 발생하게 되는 단편화 현상입니다. 위 그림의 파란색 경우입니다.
- 외부 단편화: 어떠한 경우에도 할당하기에 너무 적은 공간만 남아 할당이 불가능한 메모리가 존재하는 경우입니다. 위 그림의 빨간색 경우입니다.
이러한 단편화 현상을 방지하는 효과적인 메모리 동적할당을 위해서는 다음과 같은 필요한 정보들과 유의점들이 있습니다.
- 할당할 메모리의 크기는 얼마만큼인가?
- 할당할 메모리의 위치는 어디인가?
- 메모리를 할당할 수 있을 만큼의 비어있는 공간은 어떻게 찾을 것인가?
- 해당 메모리 공간이 할당되어있는지, 비어있는지는 어떻게 알 것인가?
- 해제되어 비어있는 메모리들을 어떻게 관리해서 다시 할당받을 수 있게 할 것인가?
- 공간의 효율성을 높일 수 있게 단편화는 어떻게 해결할 것인가?
이런 유의점들을 효과적으로 알 수 있게 하여 메모리를 관리하고자 구조화 한 것이 블록(block)이라는 단위입니다.
블록(block)에 저장되는 정보들은 무엇인가?
블록은 다음과 같은 구조를 가지고 있습니다. 좌측과 우측의 블록은 서로 다른 블록이며, 아래 설명하는 할당 방법들에 따라 사용하는 블록의 형태는 달라집니다.
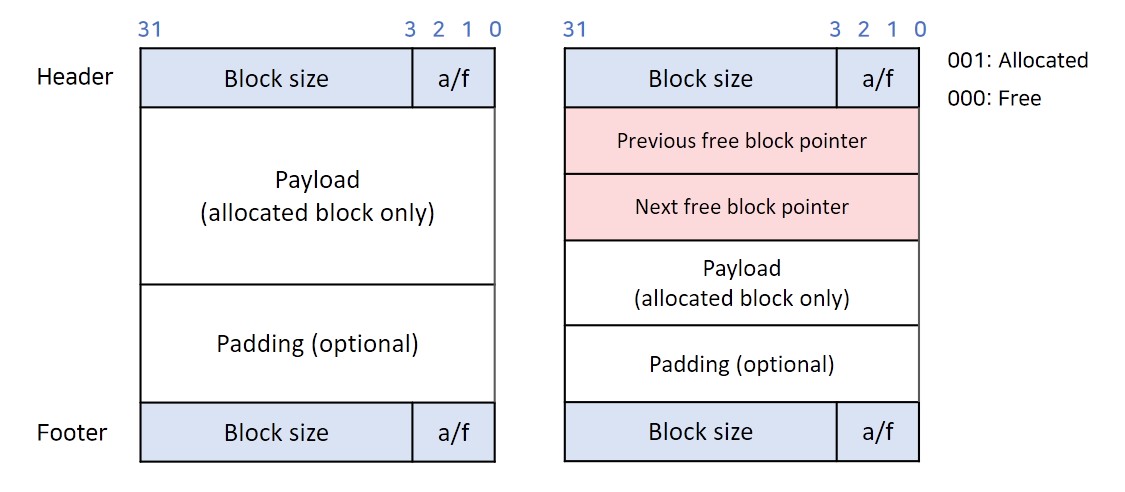
블록은 malloc함수를 이용해 할당된 정보들이 저장되는 공간입니다. malloc함수는 heap
다음과 같은 블록은 여러가지 정보들을 저장하고 있습니다. 저장하고있는 정보들을 살펴보자면
-
Header (4byte): 블록의 시작점을 나타내는 부분입니다. 해당 블록의 사이즈와 할당이 되어있는지 정보를 32bit(4byte)의
unsigned int형태로 가지고 있게 됩니다. 블록의 사이즈는 header와 footer를 포함하여 언제나 8byte 이상이기 때문에 마지막 세 비트는 무의미한 비트가 됨으로, 마지막 비트를 해당 블록의 할당 여부를 확인하는 비트로 사용합니다. 1은 할당을, 0은 할당 해제를 나타냅니다. 결과적으로 31부터 3번째 index의 bit는 사이즈 정보를, 0번째 index의 비트는 할당여부 정보를 나타냅니다. -
Payload (byte): 실제 정보들이 들어가는 부분입니다. 정보의 양에 따라 여러 크기를 가질 수 있지만, 편의상 4byte단위로 반올림하여 저장할 용량을 결정합니다.
-
Padding (선택사항, byte): 필요에 의해서 내부 단편화를 감수하고 할당해야 할 메모리보다 많은 메모리를 할당해주는 경우에 사용합니다.
-
Footer (4byte): 블록의 끝점을 나타내는 부분입니다. header의 정보와 동일한 정보를 갖습니다.
-
Previous or Next free block pointer(4byte): 할당의 방법 중 할당이 해제된 블록들의 정보만을 관리하는 경우에 이용합니다. 할당이 해제된 블록의 포인터들이 저장되어 있으며, 이중 연결리스트의 형태로 할당 해제된 블록들의 정보를 저장합니다.
본격적으로 malloc을 수행하는 다양한 방법들에 대해 알아보겠습니다.
Implicit Allocator
implicit 방법은 순차적으로 모든 블록을 검사하는 선형적인 방법입니다. 일종의 부르트포스 방식이라고 생각할 수 있겠습니다. 처음 블록부터 차례대로 검사하는 first-fit방식을 사용하면 성능이 많이 떨어집니다. 하지만 마지막 검사한 블록을 시작으로 하여 검사하는 next-fit 방식을 사용한다면 성능을 매우 향상시킬 수 있습니다. 이번에는 기본적인 방식인 first-fit 방식으로 설명하겠습니다.
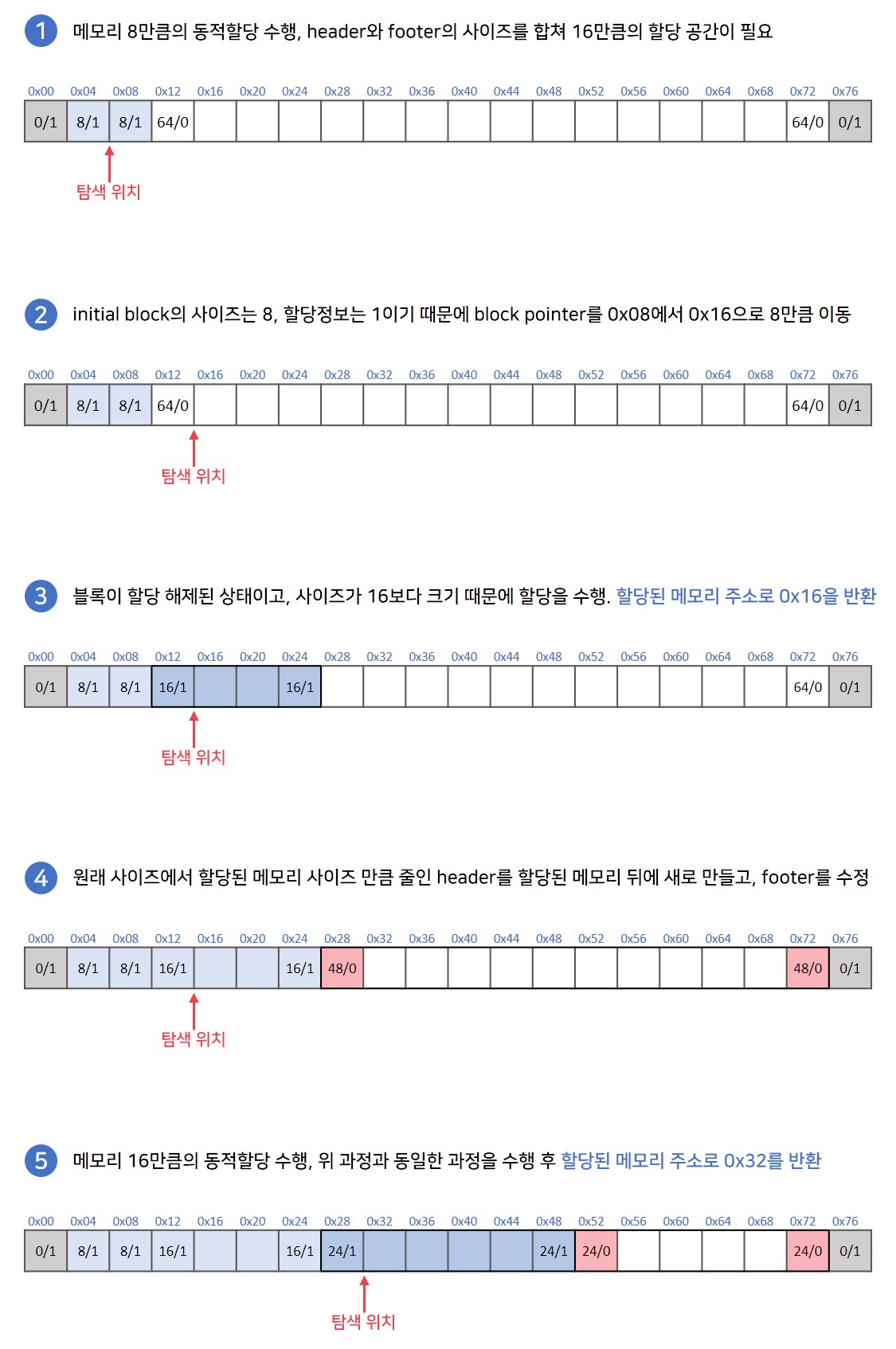
heap의 가장 처음과 끝 4byte는 힙의 처음과 끝을 알 수 있게 하는 블록입니다. 사이즈는 0, 할당여부는 1인 정보를 부여합니다. 이후, 가장 처음 블록은 header와 footer 이외에 어떠한 정보도 들어있지 않은 initial block을 설정합니다. 모든 탐색은 해당 블록으로 부터 시작할 수 있게하기 위함입니다.
이후 모든 방식에서 블록의 포인터(block pointer)를 활용하여 탐색을 수행하게 됩니다. block pointer는 header 칸의 바로 뒤 주소로 하는데, block pointer와 할당된 메모리의 주소가 같아 바로 반환하여 사용자에게 메모리가 저장된 위치를 바로 알려줄 수 있어 해당 위치로 잡습니다.

💡 메모리 할당과정
-
탐색을 진행하는 블록의 header 또는 footer를 확인하여 해당 블록의 할당 여부를 확인합니다.
-
할당이 되어있다면, 블록의 사이즈만큼 옆으로 이동하여 다음 블록을 확인합니다.
-
할당이 되어있지 않다면, 블록의 사이즈를 확인합니다.
3-1. 메모리가 할당될 수 있는 사이즈 공간과 같다면 메모리를 할당하고 해당 블록의 block pointer 주소를 반환합니다.
3-2. 메모리가 할당될 수 있는 사이즈 공간을 초과한다면 블록을 분할하여 할당하고, 나머지 부분을 해제된 블록으로 바꿔줍니다.
3-3. 메모리가 할당될 수 있는 사이즈보다 작은 공간이라면 블록의 사이즈만큼 옆으로 이동하여 다음 블록을 확인합니다. -
할당할 수 있는 공간이 없어 힙의 끝에 도달했다면 힙을 확장하여 할당합니다.
-
추가적으로 3-2 과정에서 분할된 블록의 사이즈가 일정 수준보다 작은 사이즈가 만들어지게 되는 경우라면, 해당 블록을 전부 사용하여 외부 단편화를 방지합니다.
💡 메모리 할당 해제과정
-
할당을 해제할 메모리 주소를 받습니다. 해제할 메모리 주소의 앞뒤에 블록들을 확인합니다.
-
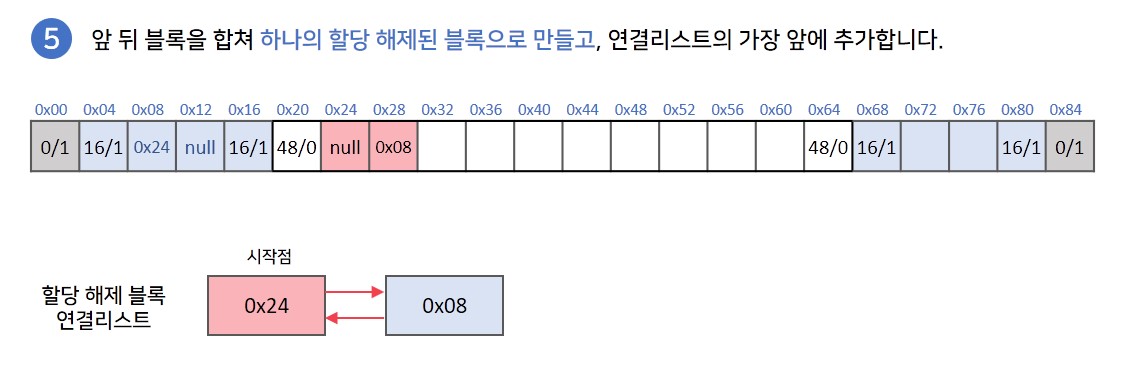
할당을 해제할 블록의 앞 또는 뒤에 이미 할당이 해제된 블록이 존재한다면 해당 블록과 합쳐 하나의 할당 해제상태 블록으로 만들어 외부 단편화를 방지합니다.

Explicit Allocator
explicit 방법은 할당이 해제되어있는 블록들을 연결리스트 형태로 관리하여 모든 블록을 검사하지 않고, 할당이 해제된 블록들만 검사하는 implicit에서 개선된 방법입니다. 하지만 impicit에 next-fit 방식의 성능과는 유사합니다.
연결리스트에 블록을 추가하는 방식에 따라 블록의 물리적인 순서대로 연결리스트가 구성되는 ordered-list방식과 최신에 해제된 블록을 연결리스트의 가장 앞에 추가하는 LIFO 방식으로 나뉩니다. 성능적인 측면에서는 LIFO 방식이, 단편화를 방지하기 위해서는 ordered-list 방식이 좋다고 합니다. 아래 과정은 LIFO 방식으로 설명하겠습니다. LIFO 방식은 물리적 순서와 연결리스트의 순서가 같음을 보장하지 않음에 주의해야 합니다.
implicit 방식에서 달라진 점은 가장 처음 블록에 header와 footer 이외에 prev & next block pointer가 들어간다는 점입니다. 해당 정보들을 이용하여 해제된 블록들을 연결리스트의 형태로 관리합니다. 가장 앞 블록은 할당이 되어있는 블록으로 연결리스트에 들어가 있어 연결리스트의 끝점을 나타내는 역할을 수행합니다.
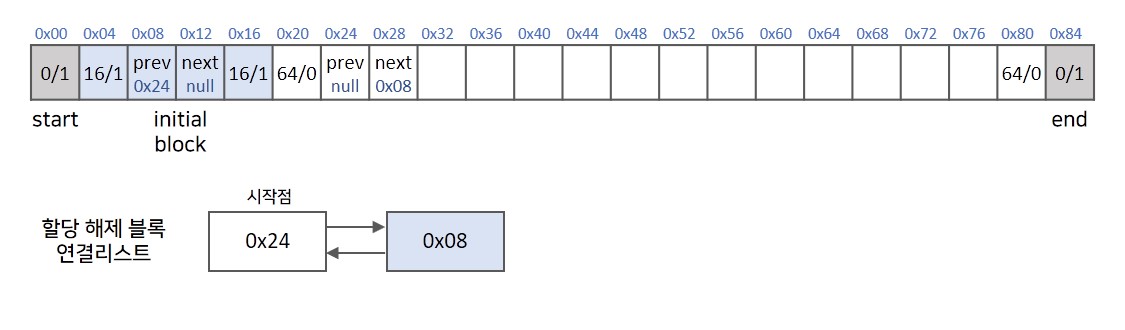
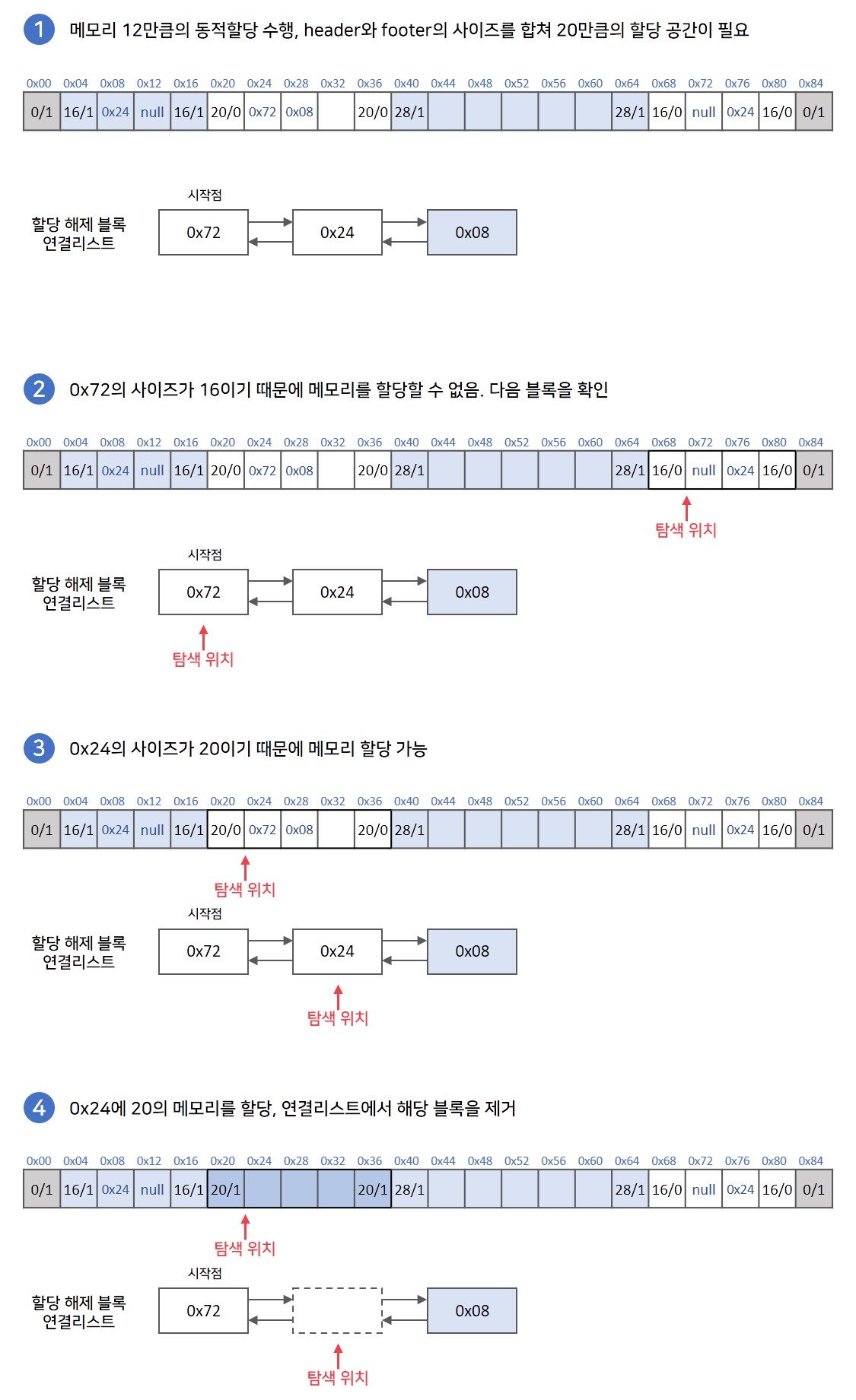
💡 메모리 할당과정
할당 되어있는 블록의 경우에는 연결리스트에서 관리하지 않기 때문에 prev, next 정보는 필요하지 않습니다.
-
연결리스트의 처음부터 순회하면서 블록의 사이즈를 확인합니다. 연결리스트 내의 블록들은 마지막 블록을 제외하고는 이미 모두 할당이 해제된 블록입니다.
-
블록의 사이즈가 본인보다 작다면 할당할 수 없는 공간입니다. 해당 블록의 next 포인터로 이동하여 다음 블록을 검사합니다.
-
블록의 사이즈가 본인보다 크거나 같다면 할당할 수 있는 공간입니다.
3-1. 해당 블록을 연결리스트에서 제거합니다.
3-2. 메모리가 할당될 수 있는 사이즈 공간을 초과한다면 블록을 분할하여 할당하고, 나머지 부분을 해제된 블록으로 바꿔준 후 연결리스트에 추가합니다.
3-2. 메모리를 할당하고 해당 블록의 block pointer 주소를 반환합니다. -
할당할 수 있는 공간이 없어 연결리스트의 끝에 도달했다면 힙을 확장하여 할당합니다.
-
추가적으로 3-2 과정에서 분할된 블록의 사이즈가 일정 수준보다 작은 사이즈가 만들어지게 되는 경우라면, 해당 블록을 전부 사용하여 외부 단편화를 방지합니다.
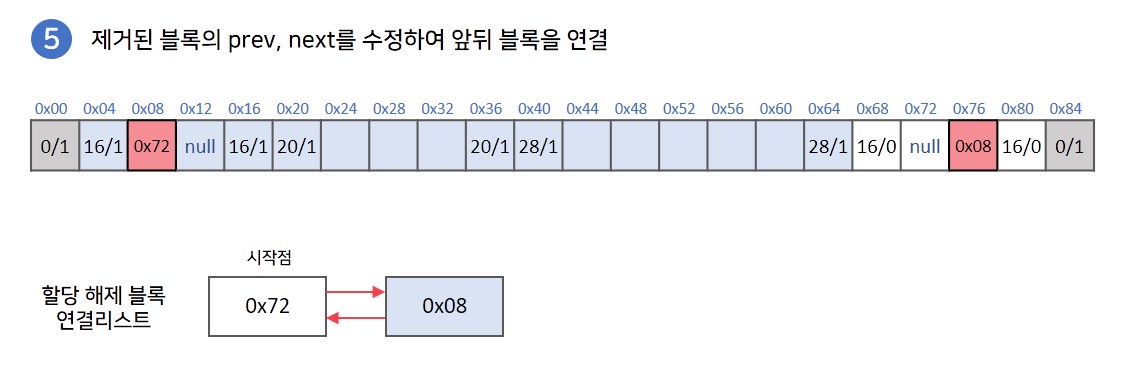
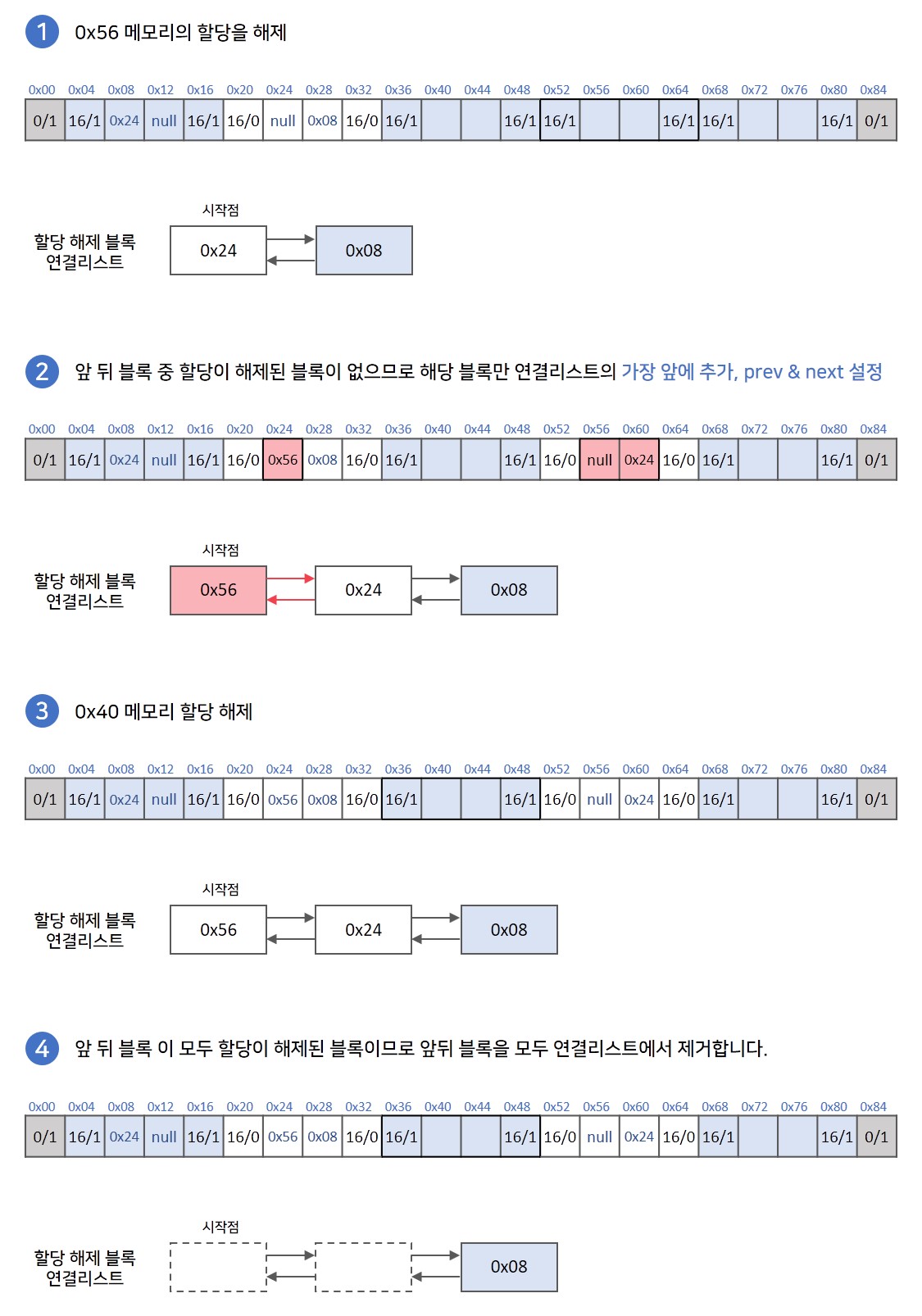
💡 메모리 할당 해제과정
-
할당을 해제할 메모리 주소를 받습니다. 해제할 메모리 주소의 앞뒤에 블록들을 확인합니다.
-
할당을 해제할 블록의 앞 또는 뒤에 이미 할당이 해제된 블록이 존재한다면 해당 블록들을 연결리스트에서 제거합니다.
-
이후 제거한 블록들과 합쳐 하나의 할당 해제상태 블록으로 만들고, 연결리스트의 가장 앞에 추가합니다.
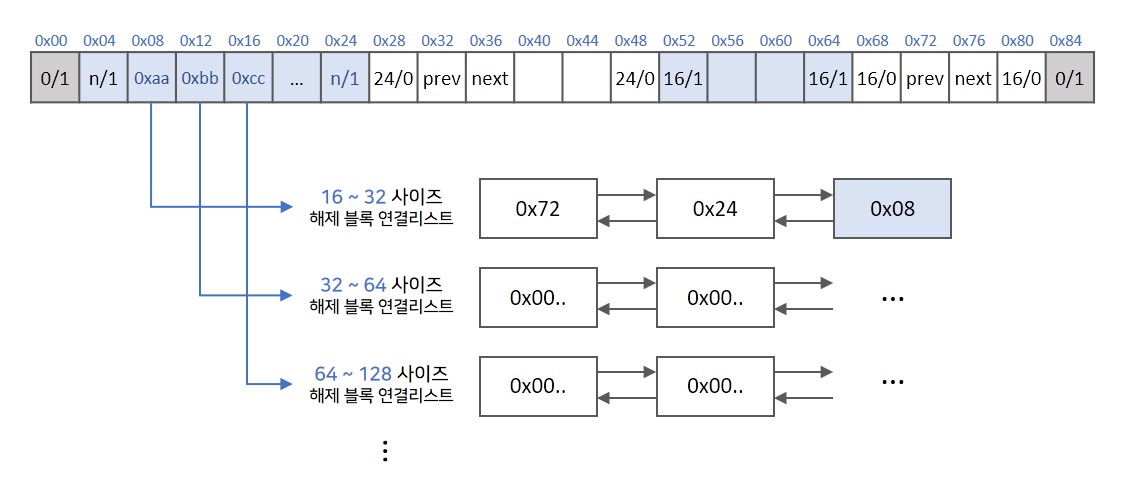
Segregated list Allocator
seg-list 방법은 할당이 해제되어있는 블록들을 사이즈별로 모아 다른 연결리스트에 관리하는 방법으로 explicit에서 개선된 방법입니다. 탐색, 할당, 삭제의 과정은 모두 explicit과 동일하기 때문에 seg-list의 초기 구조에 대해서만 설명하겠습니다.
explicit 방식과 동일하게 연결리스트를 만들지만 사이즈별로 만들어야 하기 때문에 여러개의 연결리스트가 필요합니다. 여러개의 연결리스트 포인터를 힙에 저장하여 특정한 사이즈의 메모리를 할당하고자 하면 해당 사이즈에 맞는 연결리스트로 이동하여 할당할 블록의 위치를 찾습니다. 할당하는 메모리의 사이즈를 나누는 단위는 정해지지 않았지만 대부분 단위로 나누게 됩니다.
할당이 해제된 블록을 유사한 사이즈의 블록들이 모여있는 리스트에서 찾기 때문에 빠른 속도로 찾을 수 있어 가장 성능이 좋습니다. 해당 리스트에서 사이즈에 맞는 블록을 찾지 못하면 다음 크기의 리스트로 넘어가서 할당할 블록을 찾게 됩니다. 해당 부분만 제외하면 explicit과의 로직은 동일합니다.
마치며
C언어의 동적할당 방법들과 이를 구현하는 과정에 대해 알아보았습니다. heap영역과 동적할당을 이해하는데 조금이나마 도움이 되었으면 좋겠습니다.

안녕하세요. 글 너무 많이 도움됐습니다.
혹시 글 포스팅하시면서 참고하신 자료나 책이 있다면 알 수 있을까요??