해당 포스팅은 컴퓨터 시스템의 요약정리 입니다.
1.5 캐시의 중요성
이전 포스팅에서 hello 프로그램이 실행될 때 하드웨어에서 어떠한 과정을 거쳐 작동되는지 적어보았습니다. 다시한번 간략하게 정리하면
hello프로그램의 기계어 인스트럭션들이 하드웨어에 저장- 프로그램이 로딩되면 디스크의
hello프로그램이 메인메모리로 복사 - 프로세서가 프로그램을 실행하면 인스트럭션들이 메인 메모리에서 프로세서로 복사
- 연산과정이 끝난 정보는 프로세서에서 디스플레이 장치로 복사
이 과정을 보면 시스템이 정보를 한곳에서 다른 곳으로 이동시키는 일에 많은 과정과 시간이 소비됩니다. 이러한 정보 복사의 과정들이 실제 작업을 느리게 하는 오버헤드가 되며, 이런 문제들을 해결해주는 캐시가 중요합니다.
캐시
캐시 메모리는 프로세서가 단기간에 필요로 할 가능성이 높은 정보를 임시로 저장할 목적으로 사용하는 메모리입니다.
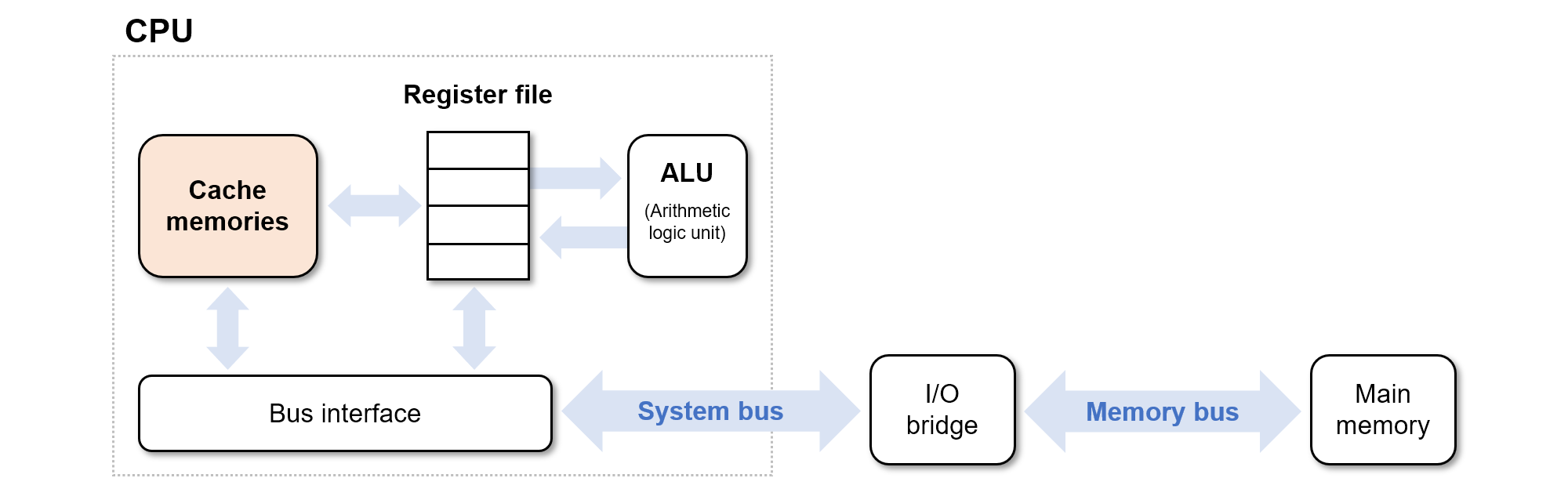
일반적으로 용량이 더 큰 저장장치들은 용량이 작은 저장장치들보다 속도가 느립니다. 프로세서와 메모리 간의 격차를 줄이기 위한 저장장치가 캐시입니다.
레지스터 파일은 수백바이트의 정보를 저장하는 반면, 메인 메모리는 몇십억개의 바이트를 저장합니다. 하지만 프로세서는 메모리보다 레지스터 파일의 데이터를 100배 빨리 읽을 수 있습니다.
캐시 시스템은 프로그램이 지엽적인 영역의 코드와 데이터를 엑세스하는 경향인 지역성(locality)을 활용하여 시스템이 매우 크고 빠른 메모리 효과을 얻을 수 있습니다. 자주 엑세스할 가능성이 높은 데이터를 캐시가 보관하도록 설정하게 되면 빠른 캐시를 이용해서 대부분의 메모리 작업을 수행할 수 있게 됩니다.
캐시의 지역성: 데이터의 접근이 시간적 혹은 공간적으로 가깝게 일어나는 것을 의미합니다. 시간지역성과 공간지역성이 있습니다.
시간 지역성: 특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터에 접근할 가능성이 높은 것을 말합니다. 캐시를 사용하기에 적합합니다.
공간 지역성: 특정 데이터와 가까운 주소가 순서대로 접근되었을 경우를 말합니다. 한 메모리 주소에 접근할 때 그 주소뿐 아니라 해당 블록을 전부 캐시로 가져와 메모리를 오름차순이나 내림차순으로 접근하게 되면 캐시의 효율성이 크게 올라갑니다.
1.6 메모리 계층구조
컴퓨터의 메모리 계층은 다음 그림과 같은 구조로 구성되어 있습니다. 계층의 꼭대기부터 맨 밑바닥까지 이동할수록 저장장치들은 느리고, 용량이 크고, 가격이 낮아집니다. (해당 그림은 L1 ~ L3 캐시를 사용하는 계층구조 입니다.)
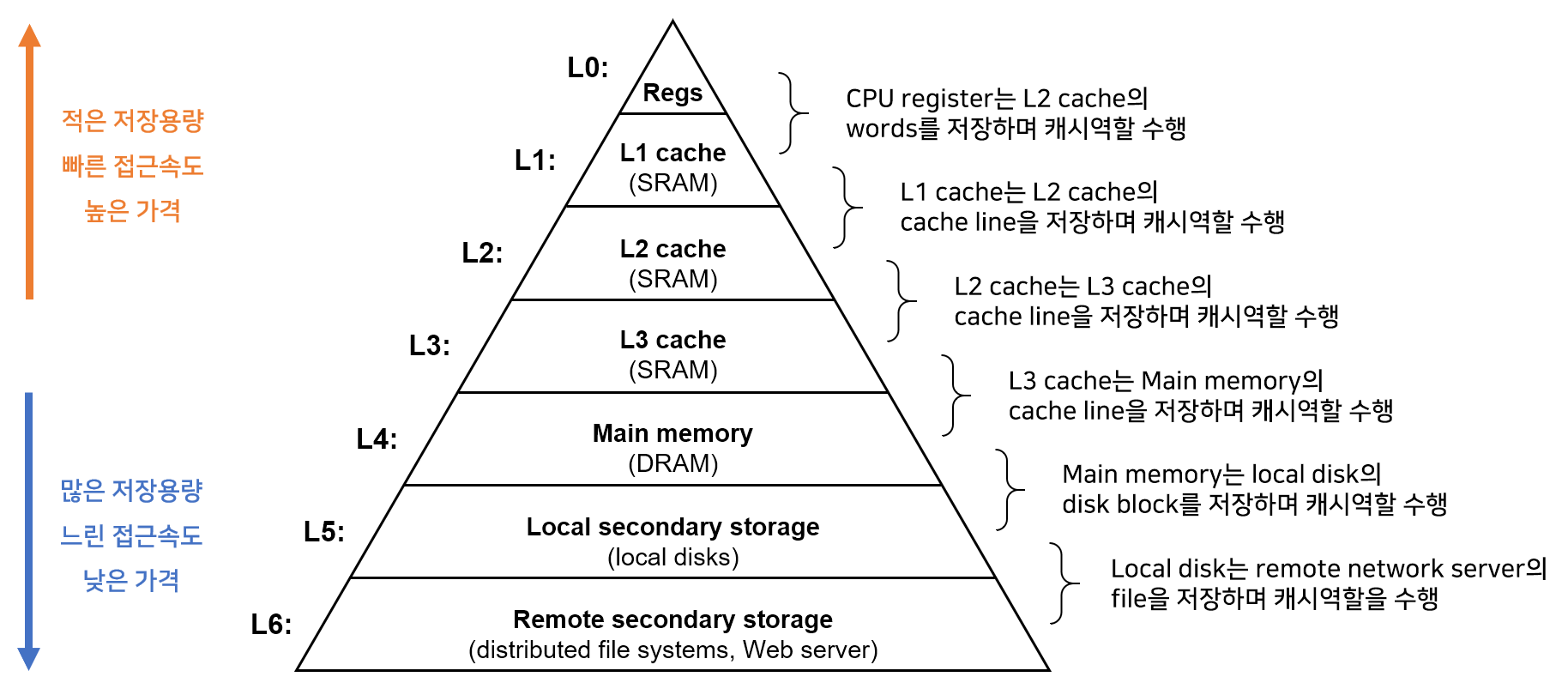
해당 메모리 계층구조를 사용하는 이유는 한 레벨의 저장장치가 다음 하위레벨 저장장치의 캐시 역할을 한다는 것입니다. L1은 L2의 캐시 역할, L2는 L3의 캐시 역할, L3는 메인 메모리와 디스크의 캐시 역할을 수행하는 식입니다. 여러개의 캐시를 활용한 계층구조를 사용하여 임시 정보를 저장해 성능을 개선시킬 수 있기 때문에 캐시를 사용합니다.
프로세서 칩 내부에 들어있는 L1 캐시는 대략 수천 바이트의 데이터를 저장할 수 있으며, 거의 레지스터 파일만큼 빠른 속도로 엑세스할 수 있습니다. 이보다 좀 더 큰 L2 캐시는 수백 킬로바이트에서 수 메가바이트의 용량을 가지며 전용 버스를 통해 연결됩니다. 프로세서가 L2 캐시를 엑세스할 때 L1 캐시보다 5배정도 느리지만, 메인 메모리에 엑세스할 때 보다는 10배 빠릅니다.
1.7 운영체제와 하드웨어
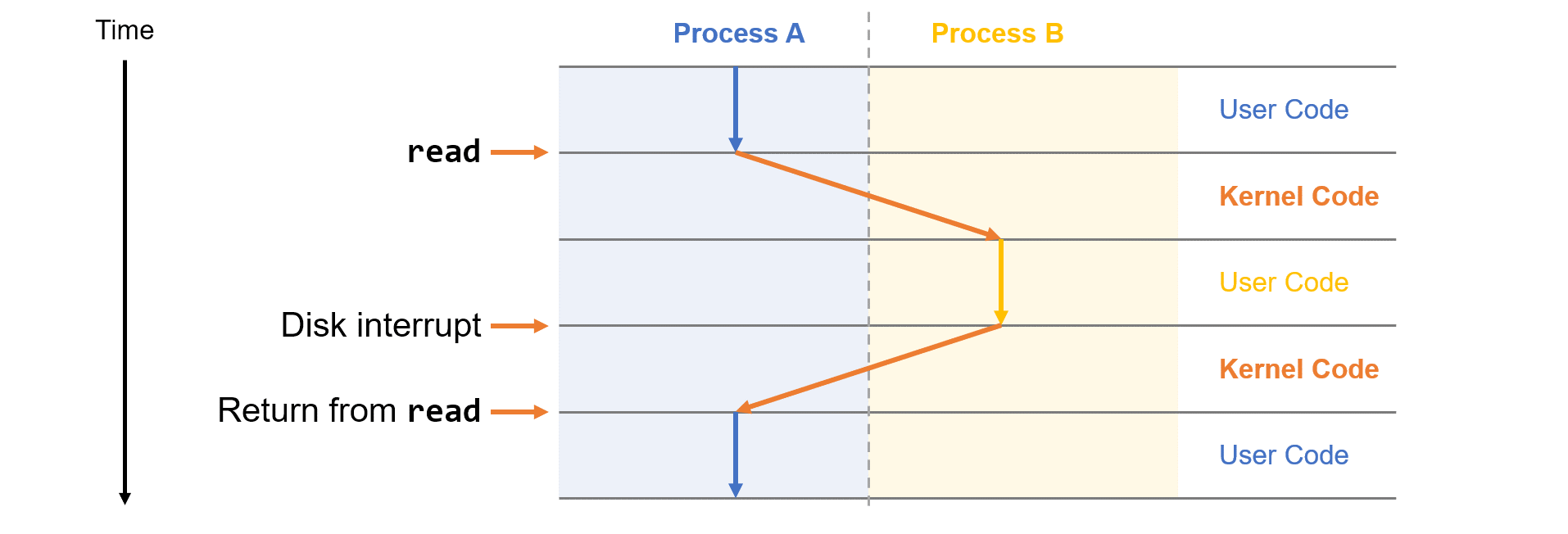
예제에서 쉘 프로그램이 hello 프로그램을 로드하고 실행했을 때와 hello 프로그램이 메세지를 출력할 때 프로그램이 키보드나 디스플레이, 디스크나 메인메모리에 직접 엑세스하지 않고, 운영체제가 제공하는 서비스를 이용합니다.
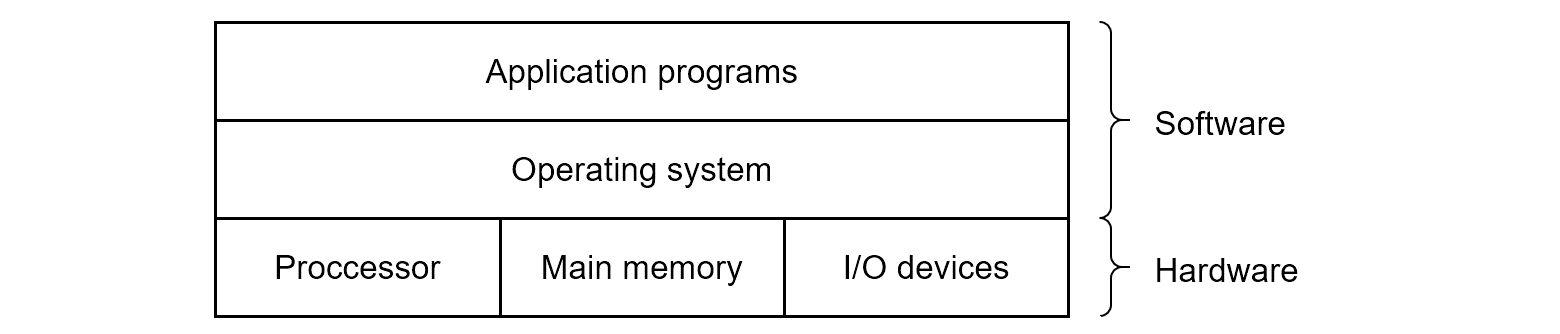
운영체제는 하드웨어와 소프트웨어 사이에 위치한 소프트웨어 계층으로, 응용 프로그램이 하드웨어를 제어하려면 언제나 운영체제를 통해야합니다. 운영체제의 주요한 목적을 간단히 말하면 다음과 같습니다.
- 응용프로그램들이 하드웨어를 잘못 사용하는 것을 막기 위해
- 응용프로그램들이 복잡한 저수준 하드웨어 장치들을 단순하고 균일한 메커니즘을 사용하여 조작할 수 있도록 하기 위해
운영체제는 이 두가지 목적을 추상화를 통해 달성하고 있습니다.
추상화: 복잡한 자료, 모듈, 시스템 등으로 부터 핵심적인 개념 또는 기능을 간추려 내는 것. 전문적인 단어가 아니라 우리가 익히 알고있는 추상화와 같은 개념
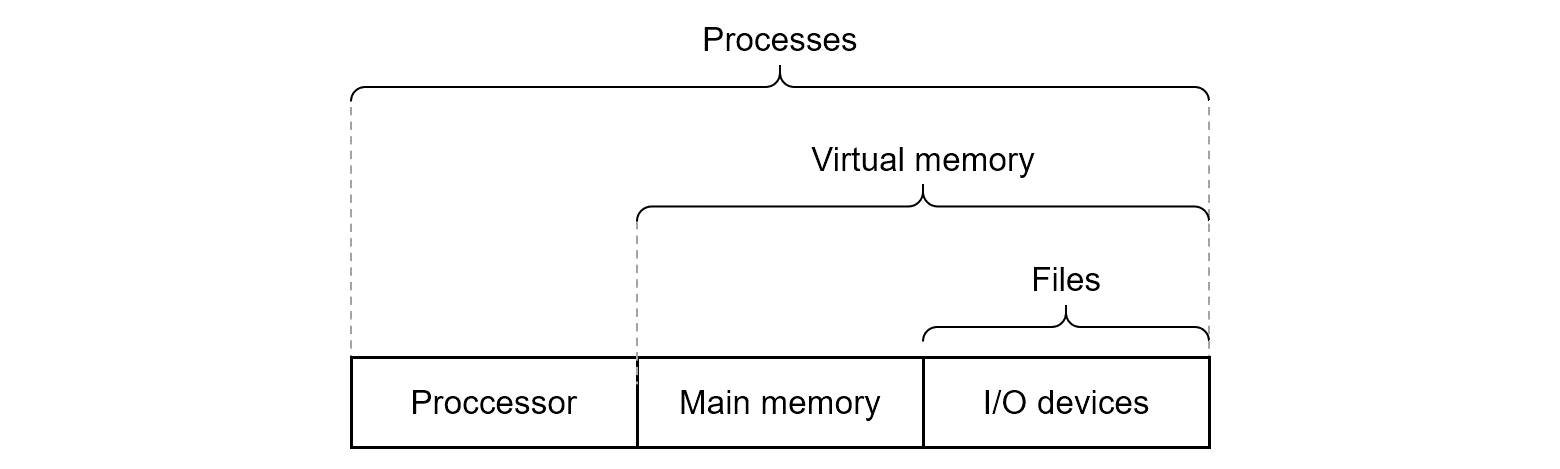
- 파일: 입출력 장치의 추상화
- 가상 메모리: 메인 메모리와 디스크 입출력 장치의 추상화
- 프로세스: 프로세서, 메인 메모리, 입출력장치 모두의 추상화
프로세스(Process)
프로세스는 실행중인 프로그램에 대한 운영체제의 추상화이며, 컴퓨터에서 연속적으로 실행되고 있는 프로그램을 말합니다.
CPU가 멀티코어를 가지고 있다고 하더라도 대부분의 시스템에서 프로세스를 실행할 CPU의 숫자보다 더 많은 프로세스들이 존재합니다. 대부분의 시스템를 기준으로 프로세스는 동시성과 병렬성을 가지며, 이를 통해 다수의 프로세스가 동시에 실행하는 것 처럼 보이게 합니다. 운영체제는 Context Switching을 통하여 여러 프로세스를 교차 수행합니다.
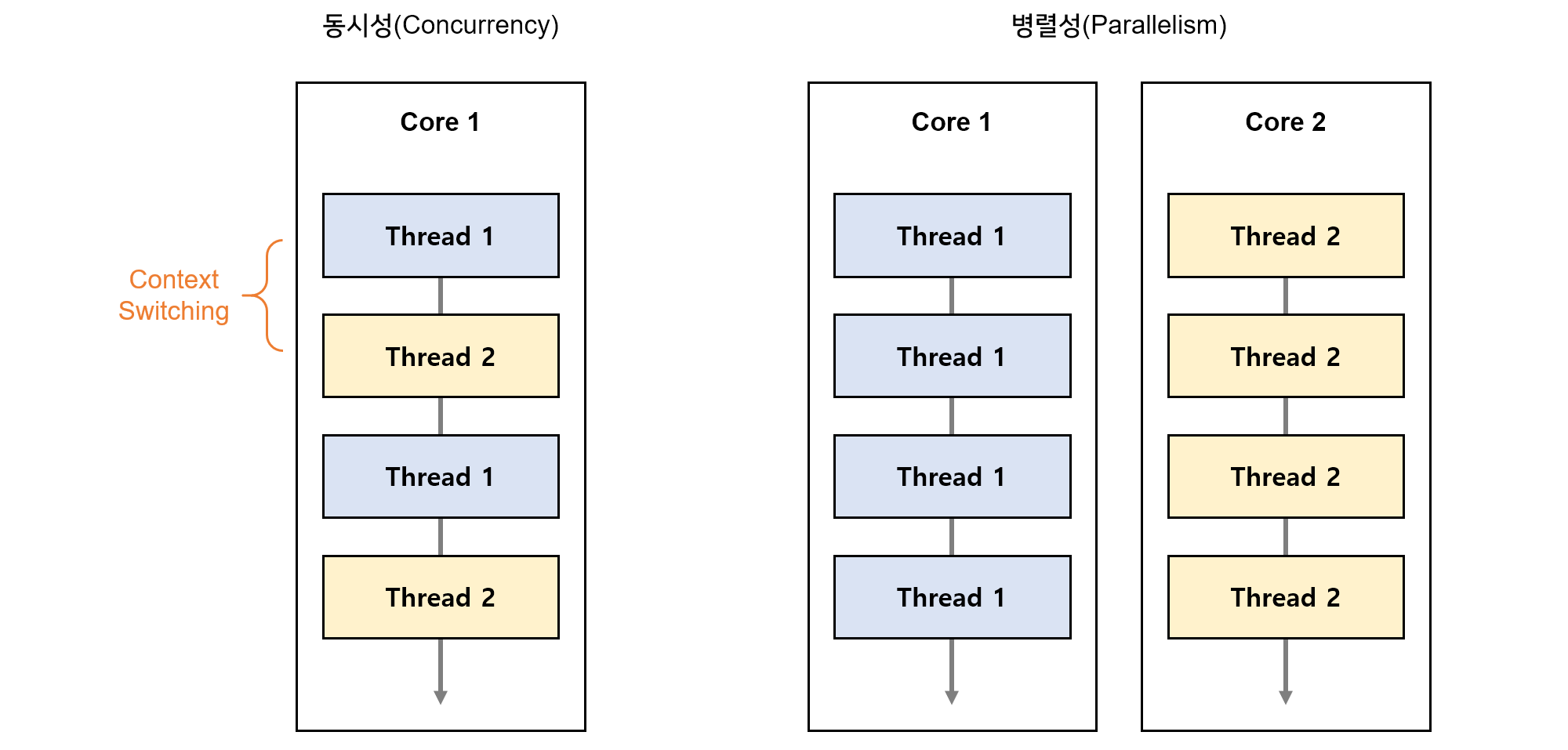
동시성(Concurrency): 하나의 CPU에서 여러개의 일을 한번에 처리. OS의 Scheduling에 따라 Context Switching을 통해 여러 테스크를 동시에 처리하는 것 처럼 보이게 함
병렬성(Parallelism): 여러개의 CPU에서 여러개의 일을 처리.
운영체제는 프로세스가 실행하는 데 필요한 모든 상태정보의 변화를 추적합니다. 이 컨텍스트(Context)라고 부르는 상태정보는 PC, 레지스터 파일, 메인 메모리의 현재 값을 포함하고 있습니다. 운영체제는 현재 프로세스에서 다른 새로운 프로세스로 제어를 옮기려고 할 때 현재 프로세스의 컨텍스트를 저장하고 새 프로세스의 컨텍스트를 복원시키는 컨텍스트 스위칭(Context Switching)을 실행하여 제어권을 새 프로세스로 넘겨줍니다. 새 프로세스는 이전에 중단했던 바로 그 위치부터 다시 실행됩니다.
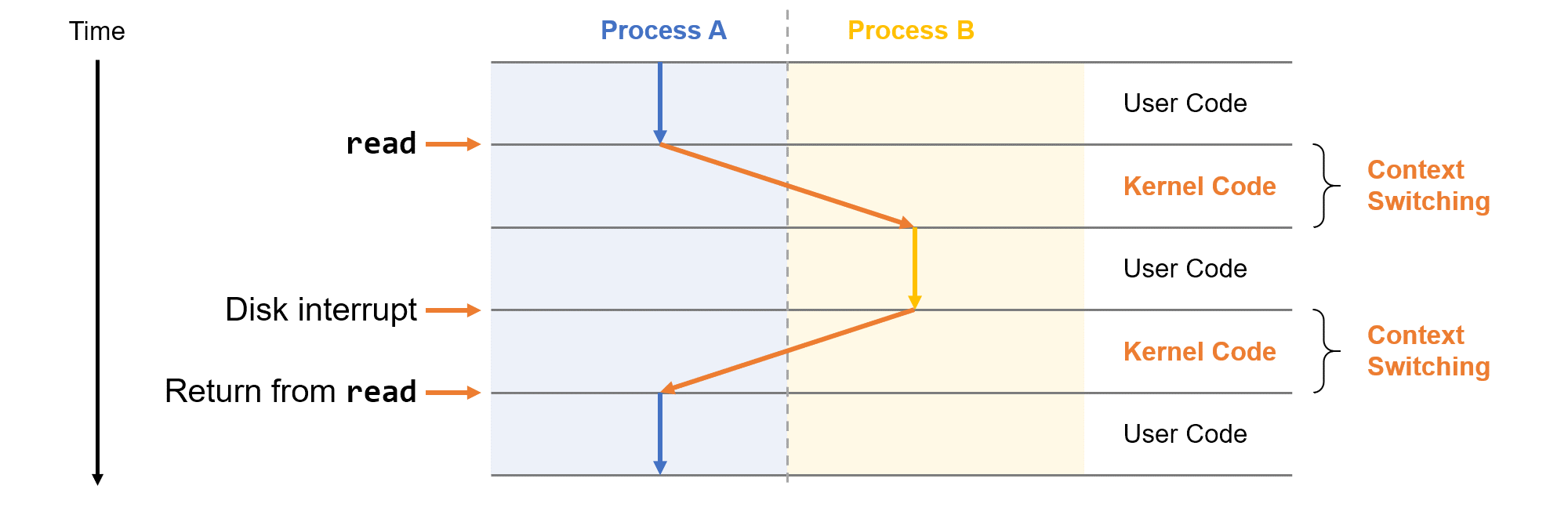
커널은 별도의 프로세스가 아니라 모든 프로세서를 관리하기 위해 시스템이 이용하는 코드와 자료구조의 집합입니다.
하나의 프로세스에서 다른 프로세스로의 전환은 운영체제 커널(kernel)에 의해 관리됩니다. 커널은 운영체제 코드의 일부분으로 메모리에 상주합니다. 응용프로그램이 운영체제에의한 어떤 작업을 요청하면, 컴퓨터는 파일 읽기나 쓰기와 같은 특정 시스템콜을 실행시켜 커널에 제어를 넘겨줍니다. 그러면 커널은 요청된 작업을 수행하고 응용프로그램으로 리턴합니다.
스레드(Thread)
프로세스는 스레드라고 하는 다수의 실행 유닛으로 구성되어 있다. 각각의 스레드는 해당 프로세스의 컨텍스트에서 실행되며 동일한 코드와 전역 데이터를 공유합니다.
다수의 프로세스들에서보다 데이터의 공유가 더 쉽다는 점과 스레드가 프로세스보다 더 효율적이라는 점 때문에 다중 스레딩(multithreading)도 프로그램 속도를 향상시키는 데 많이 사용되는 방법입니다.
가상메모리(Virtual Memory)
물리 메모리에서 프로세스가 작동되게 된다면, 각 프로세스는 실제 메모리 사용량은 적지만 하나의 블록을 이루어 메모리를 차지하기 때문에 메모리 누수가 일어나게 됩니다. 이러한 부분을 해결하기 위해 각 프로세스는 가상주소공간을 가지게 됩니다.
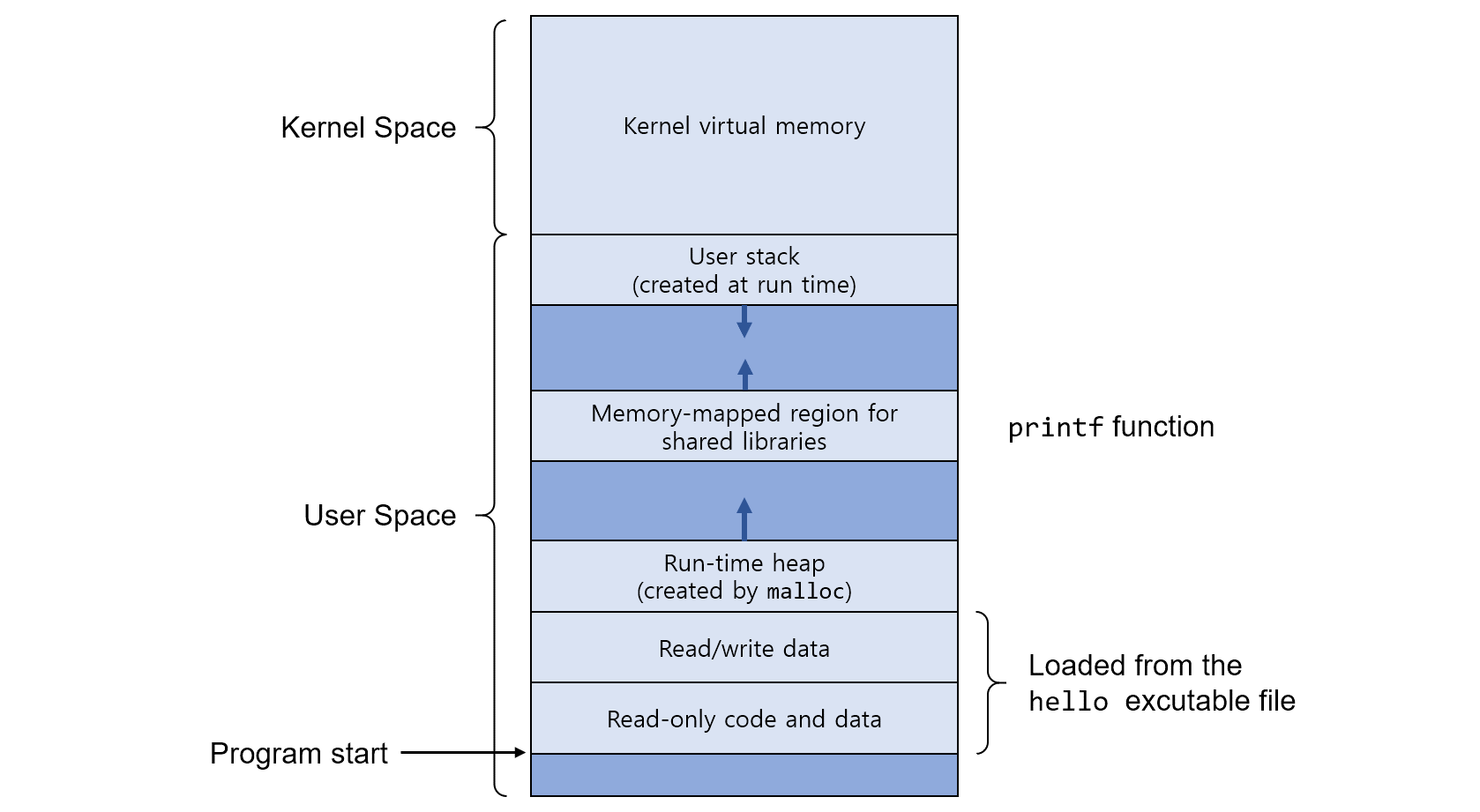
가상 주소 공간은 프로세스 하나가 전체 메모리를 사용하는 것 처럼 동작하게 합니다. 하지만 물리메모리에는 여러개의 블록으로 나누어저 저장되어 메모리를 효과적으로 사용할 수 있게 합니다.
(1) 프로그램 코드와 데이터(Code and Data)
코드는 모든 프로세스들이 같은 고정 주소에서 시작하며, 다음에 C 전역변수에 대응되는 데이터 위치들이 따라옵니다. 코드와 데이터 영역은 실행가능 목적파일인 hello로부터 직접 초기화됩니다.
(2) 힙(Heap)
코드와 데이터 영역 다음으로 런타임 힙이 따라옵니다. 크기가 고정되어 있는 코드, 데이터 영역과 달리 힙은 프로세스가 실행되면서 C 표준함수인 malloc이나 free를 호출하면서 런타임에 동적으로 그 크기가 늘었다 줄었다 합니다.
(3) 공유 라이브러리(Shared libraries)
주소 공간의 중간 부근에 C 표준 라이브러리나 수학 라이브러리와 같은 공유 라이브러리의 코드와 데이터를 저장하는 영역이 있습니다.
(4) 스택(Stack)
사용자 가상메모리 공간의 맨 위에 컴파일러가 함수 호출을 구현하기 위해 사용하는 사용자 스택이 위치합니다. 힙과 마찬가지로 사용자 스택은 프로그램이 실행되는 동안 동적으로 늘어났다 줄어들었다 합니다. 특히, 함수를 호출할 때마다 스택이 커지며, 함수에서 리턴될 때는 줄어듭니다.
(5) 커널 가상메모리(Kernel virtual memory)
주소공간의 맨 윗부분은 커널을 위해 예약되어 있습니다. 응용프로그램들은 이 영역의 내용을 읽거나 쓰는 것이 금지되어 있으며, 마찬가지로 커널 코드 내에 정의된 함수를 직접 호출하는 것도 금지되어 있습니다. 대신, 이런 작업을 수행하기 위해서는 커널을 호출해야 합니다.
파일(File)
파일은 익히 알고있듯이 연속된 바이트들의 집합입니다. 모든 입출력 장치는 파일로 모델링하며, 다양한 입출력 장치들의 통일된 사용성을 제공합니다.

잘 읽고 있습니다 ㅎㅎ