- MySQL 에서 사용할 수 있는 스토리지 엔진 중 거의 유일하게 레코드 기반 잠금 제공 => 높은 동시성 처리 가능, 안정적, 성능 Good
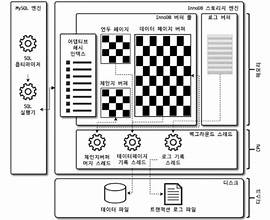
전체 구조
InnoDB가 은행 시스템이라면
- 버퍼 풀:은행 창구(메모리에서 빠르게 처리)
- 디스크: 금고(느리지만 안전하게 보관)
- 언두 로그: CCTV 녹화본(이전 상태 복구용)
- 리두 로그: 거래 장부(장애 발생 시 복구용)
4.2.1 프라이머리 키에 의한 클러스터링
- InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장
=> InnoDB는 데이터를 PK순서대로 디스크에 저장한다라는 의미 - 모든 세컨더리 인덱스는 레코드의 주소 대신 프라이머리 키의 값을 논리적인 주소로 저장
- 프라이머리 키가 클러스터링 인덱스라서 => 프라이머리 키를 이용한 레인지 스캔은 상당히 빨리 처리 가능
- 결과적으로 쿼리의 실행 계획에서 프라이머리 키는 기본적으로 다른 보조 인덱스에 비해 비중이 높게 설정됨(쿼리의 실행 계획에서 다른 보조 인덱스보다 프라이 머리 키가 선택될 확률이 높음)
- 클러스터 키는 8.8절 클러스터링 인덱스에서 설명
왜 좋을까? -> PK로 범위 조회하면 엄청 빠른데(순차적으로 읽으면 되니까), 일반 인덱스는 특정_인덱스 -> PK 찾기 -> 데이터 찾기 (2단계)
MyISAM 스토리지 엔진
- 클러스터링 키 지원 X
- 그래서 프라이머리 키, 세컨더리 인덱스의 구조적 차이 X
- 프라이머리 키는 유니크 제약을 가진 세컨더리 인덱스일 뿐
- MyISAM의 모든 인덱스는 물리적인 레코드의 주소값(ROWID)를 가짐
- MyISAM 테이블 구조, 인덱스는 4.3.3절에서 설명
4.2.2 외래 키 지원
- InnoDB 스토리지 엔진 레벨에서 지원하는 기능
- DB 서버 운영의 불편함 때문에 서비스용 DB에서는 생성하지 않는 경우도 있으나, 그렇다고 하더라도 개발 환경 DB에서는 좋은 가이드 역할 가능
외래 키
- 부모 테이블, 자식 테이블 모드 해당 칼럼에 인덱스 생성 필요
- 변경 시 반드시 부모 테이블 or 자식 테이블에 데이터가 있는지 체크하는 작업 필요 => 잠금이 여러 테이블로 전파됨 => 그로 인해 데드락이 발생할 때가 많아 개발할 때 외래 키 존재 주의
- 데드락: 교착 상태 = 서로 기다리다가 멈추는 상태
- 외래 키가 데드락 유발 => payment 테이블 잠금 -> orders 테이블 확인(FK 검증) -> order 테이블도 잠금
=> 다른 트랜잭션이 orders를 먼저 잠그면? 데드락 발생 가능!
관리 작업 실패 or 서비스에 문제가 생긴 경우
- foreign_key_checks 시스템 변수 OFF 설정 => 외래 키에 대한 체크 작업을 일시적으로 중시시킬 수 있음 => 레코드 적재, 삭제 등의 작업도 부가적인 체크가 필요하지 않아 빠르게 처리 가능
- 외래 키 체크를 해체했을 경우에도 일관성은 맞춰야 함
4.2.3 MVCC(Multi Version Concurrency Control)
- 읽기가 쓰기에 막혀버리는 상황을 피하자
- 일반적으로 레코드 레벨의 트랜잭션을 지원하는 DBMS가 제공하는 기능
- 목적: 잠금을 사용하지 않는 일관된 읽기 제공
- InnoDB의 경우 언두 로그(Undo Log)를 이용해 기능 구현
- 멀티 버전: 하나의 레코드에 대해 여러 개의 버전이 동시에 관리됨
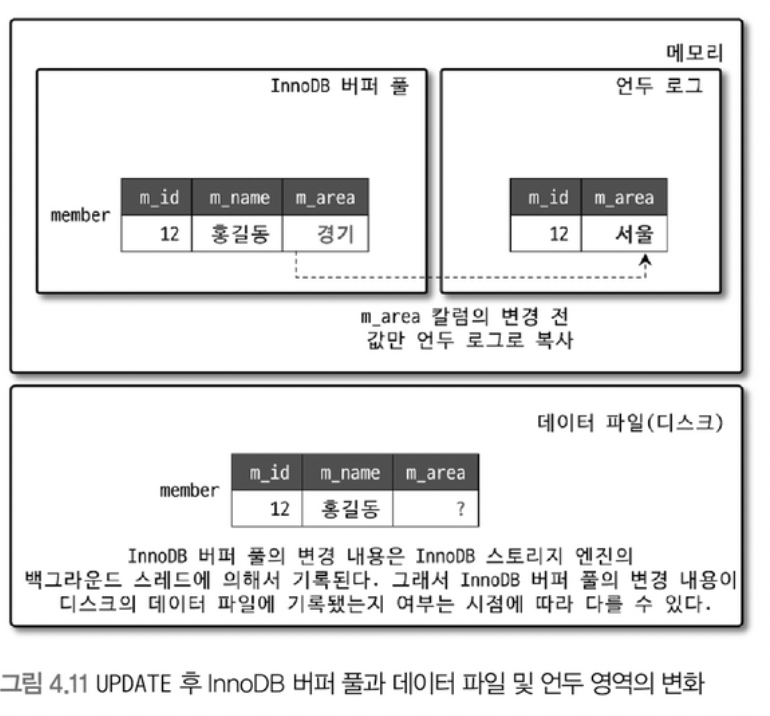
MVCC 동작
- 격리 수준은 READ_COMMITED
- INSERT => 버퍼 풀과 디스크에 INSERT문 데이터가 들어감
- UPDATE => 업데이트된 데이터가 버퍼 풀과 디스크에 들어가고, Undo log에 업뎃 이전의 데이터가 복사되어 들어감(그럴수도 아닐수도 있지만 보통 ACID를 보장해서 일관성이 보장된다고 생각해야)
- COMMIT or ROLLBACK이 되지 않은 경우 레코드 조회?
=> 격리 수준에 따라 달라짐!
- READ_COMMITED: 데이터가 커밋되었든 아니든 변경된 데이터 반환
- 그 이상의 격리 수준: 커밋되지 않았으니 변경되기 이전 내이터를 보관하고 있는 언두 영역 데이터 반환
- 즉, 하나의 레코드에 대해 2개의 버전이 유지되고, 필요에 따라 어느 데이터가 보여지는지 달라지는 구조
- 관리해야 하는 예전 버전의 데이터는 무한히 많아질 수 있으며, 트랜잭션이 길어지면 언두에서 관리하는 예전 데이터가 삭제되지 못하고 오랫동안 관리되어야 함 => 때문에 자연히 언두 영역이 저장되는 시스템 테이블스페이스의 공간이 많이 늘어나는 상황 발생
MVCC가 없을 경우
// MVCC 없는 경우 (가상 시나리오)
// 트랜잭션 A
@Transactional
public void update() {
account.setBalance(9000); // 🔒 쓰기 잠금
// ... 작업 중 (3초)
}
// 트랜잭션 B
@Transactional(readOnly = true)
public void read() {
account.getBalance(); // 🔒 읽기 잠금 필요!
// → A가 끝날 때까지 대기해야 함!
}MVCC가 있을 경우
// 트랜잭션 A
@Transactional
public void update() {
account.setBalance(9000); // 🔒 쓰기 잠금
// 버퍼 풀: 9000
// 언두 로그: 10000 백업
}
// 트랜잭션 B
@Transactional(readOnly = true)
public void read() {
account.getBalance(); // ✅ 잠금 없이 바로 실행!
// → 언두 로그에서 10000 읽어옴
}4.2.5 자동 데드락 감지
데드락과 교착 상태
은행 창구 비유:
손님 A: 1번 창구 사용 중 → 2번 창구 필요
손님 B: 2번 창구 사용 중 → 1번 창구 필요
→ 서로 기다림 = 교착 상태4.2.4 잠금 없는 일관된 읽기(Non-Locking Consistent Read)
- SELECT는 읽기 락도 없고 쓸기 락도 기다리지 않음
잠금 = lock - InnoDB 스토리지 엔진은 MVCC 기술을 이용해 잠금을 걸지 않고 읽기 작업을 수행
(근데 mvcc가 왜 잠금을 걸지 않고 읽기 작업을 할 수 있는 건지 모르겠음 mvcc가 없다면 어떻게 읽기 작업을 해야 하는데?) - InnoDB에서 읽기 작업은 다른 트랜잭션이 가지고 있는 잠금을 기다리지 않고 읽기 작업이 가능함 (lock이 없으니까)
- 격리 수준이 READ_UNCOMMITTED, READ_COMMITED, REPEATABLE_READ 수준인 경우 순수한 읽기(SELECT) 작업은 다른 트랜잭션의 변경 작업과 관계없이 항상 잠금을 대기하지 않고 바로 실행됨
- 특정 사용자가 레코드를 변경하고 아직 수행하지 않은 상태에도, 이 변경 트랜잭션이 다른 사용자의 SELECT 작업 방해 X
- 이것을 잠금 없는 일관된 읽기라고 표현하며 InnoDB는 변경 전 데이터를 읽기 위해 언두 로그를 사용함
4.2.5 자동 데드락 감지
- InnoDB 스토리지 엔진은 내부적으로 잠금이 교착 상태에 빠지지 않았는지 체크하기 위해 잠금 대기 목록을 그래프 형태로 관리
- 데드락 감지 스레드를 가지고 있어서 데드락 감지 스레드가 주기적으로 잠금 대기 그래프를 검사해 교착 상태에 빠진 트랜잭션을 찾아 하나를 강제 종료함
(데드락이 뭐고 교착 상태가 뭐고 트랜잭션을 종료하면 왜 해결되는지?) - 강제 종료 트랜잭션 판단 기준 => 언두 로그 양
- 언두 로그 레코드를 더 적게 가진 트랜잭션이 일반적으로 롤백의 대상이 됨- 트랜잭션이 언두 레코드를 적게 가졌다? => 롤백을 해도 언두 처리를 해야 할 내용이 적고, 트랜잭션 강제 롤백으로 인한 서버 부하를 덜 유발함
- InnoDB 스토리지 엔진은 상위 레이어인 MySQL 엔진에서 관리되는 테이블 잠금은 볼 수 없어 데드락 감시가 부확실할 수 있음 => innodb_table_locks 시스템 변수를 활성화하면, 스토리지 엔진 내부 레코드 잠금 + 테이블 레벨의 잠금 감지 가능(활성화하자)
동시 처리 스레드가 매우 많아지거나 각 트랜잭션이 가진 잠금의 갯수가 많아질 경우
- 데드락 감지 스레드가 느려짐
- 데드락 감지 스레드는 잠금 목록을 검사해야 함 => 잠금 상태가 변경되지 않게 잠금 목록이 저장된 리스트(잠금 테이블)에 새로운 잠금을 걸고 데드락 스레드를 찾게 됨- 데드락 스레드가 느려지면 => 서비스 쿼리를 처리 중인 스레드는 더 작업 못하고 대기하면서 서비스에 악영향 미침
- 이 경우엔 데드락 감지 스레드가 더 많은 CPU 자원 소모 가능성 O
- 이 경우엔 innodb_deadlock_detect 시스템 변수를 OFF로 설정해 데드락 감지 스레드를 끌 수 있음
- 만약 PK나 세컨더리 인덱스를 기반으로 매우 높은 동시성 처리를 요구하는 서비스가 있다면 해당 변수를 비활성화해서 성능 비교를 해 봐라
4.2.6 자동화된 장애 복구
-
InnoDB는 손실이나 장애로부터 데이터를 보호하기 위한 여러 메커니즘 탑재
-
이 메커니즘으로 MySQL 서버가 시작될 떄 완료되지 못한 트랜잭션이나 디스크에 일부만 기록된 데이터 페이지 등에 대한 일련의 복구 작업이 자동 진행
-
MySQL 서버와 무관하게 디스크나 서버 하드웨어 이슈로 InnoDB 스토리지 엔진이 자동으로 복구 못 하는 경우가 발생할 수 있는데, MySQL 서버가 시작될 때 자동 복구 시작 시점에서 복구될 수 없는 손상이 있으면 자동 복구를 멈추고 MySQL 서버가 종료되어 버림
=> 이땐 innodb_force_recovery 시스템 변수를 설정해 서버를 시작해야 함 -
이 설정값이 InnoDB 스토리지 엔진이 로그 파일의 손상 여부 검사 과정을 선별적으로 진행할 수 있게 함
innodb_force_recovery 설정 가능 값에 맞춰 실행
=> 이걸해도 안 되면 백업을 이용해 구축하는 방법밖에 없음
4.2.7 InnoDB의 버퍼 풀
- InnoDB 스토리지 엔진에서 가장 핵심적인 부분으로, 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간
- 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해 주는 버퍼 역할도 함
- 데이터를 변경하는 쿼리는 데이터 파일의 이곳저곳에 위치한 레코드를 변경하기 때문에 랜덤한 디스크 작업을 발생시킴 => 버퍼 풀이 이러한 변경된 데이터를 모아 처리하면 랜덤함 디스크의 작업 횟수를 줄일 수 있음
4.2.7.1 버퍼 풀의 크기 설정
-
일반적으로 물리 메모리의 80%를 InnoDB의 버퍼 풀로 설정하라는 내용의 게시글도 존재하지만, OS와 각 클라이언트 스레드가 사용할 메모리까지 고려해서 설정해야 함
-
레코드 버퍼: 각 클라이언트 세션에서 테이블의 레코드를 읽고 쓸 때 버퍼로 사용하는 공간
-
커넥션이 많고 사용하는 테이블도 많으면 레코드 버퍼 용도로 사용되는 공간이 꽤 많이 필요해질 수 있음
-
MySQL 서버가 사용하는 레코드 버퍼 공간은 별도로 설정할 수 없으며, 전체 커넥션 개수와 각 커넥션에서 읽고 쓰는 테이블 개수에 따라서 결정됨
-
또한 버퍼 공간은 동적으로 해제되기도 하므로 정확히 필요한 메모리 공간 계산 불가
-
MySQL 5.7버전부터 InnoDB 버퍼 풀의 크기를 동적으로 조절할 수 있게 개선
=> 가능하면 InnoDB 버퍼 풀의 크기를 적절히 작은 값으로 설정해서 조금씩 상황을 봐 가면서 증가시키는 게 최적 -
회사라면 그 서버의 메모리 설정 기준으로 버퍼 풀의 크기를 조정
-
처음으로 MySQL 서버를 준비한다면?
- OS의 전체 메모리 공간이 8GB 미만 => 50% 정도만 InnoDB 버퍼 풀로 설정하고 나머지 메모리 공간은 다른 프로그램이 사용할 수 있는 공간 확보
- 전체 메모리 공간이 그 이상이라면 50%에서 시작해서 최적점을 찾을 때까지 올리자
InnoDB 버퍼 풀
- innodb_buffer_pool_size 시스템 변수로 크기 설정 가능 => 동적으로 크기 확장 가능
- 크기 변경은 크리티컬한 변경이므로 MySQL 서버가 한가한 시점을 골라 진행해야 함
- 버퍼 풀을 크게 변경하는 건 시스템 영향도가 크지 않지만, 줄이는 경우엔 시스템 영향도가 매우 크므로 하지 않게 주의해ㅑㅇ 함
- InnoDB 버퍼 풀은 내부적으로 128MB 청크 단위로 쪼개어 관리 => 버퍼 풀의 크기를 조정하기 위한 단위로 처리
- InnoDB 버퍼 풀은 내부 잠금 경함을 줄이기 위해 버퍼 풀을 여러 개로 쪼개어 관리할 수 있게 개선되었음
- 쪼개지면서 세마포어 자체도 경합이 분산되며 해결
(버퍼 풀 전체를 관리하는 잠금으로 왜 내부 잠금 경합이 유발되고, 내부 잠금 경합은 무엇이고, 쪼개면 왜 해결됨?) - innodb_buffer_pool_instances 시스템 변수를이용해 버퍼 풀을 여러 개로 분리해서 관리할 수 있는데, 각 버퍼 풀을 버퍼 풀 인스턴스라고 표현함
- 기본적으로 버퍼 풀 인스턴스 개수는 8개로 초기화되지만, 전체 버퍼 풀을 위한 메모리 크기가 1GB 미만이면 버퍼 풀 인스턴스는 1개만 생ㅅ겅됨
- 메모리 공간이 40GB 이하라면 기본 값인 8을 유지, 더 크다면 버퍼 풀 인스턴스당 5GB가 되게 인스턴스 개수를 설정하자
4.2.7.2 버퍼 풀의 구조
- InnoDB 스토리지 엔진은 버퍼 풀이라는 거대한 메모리 공간을 페이지 크기 조각으로 쪼개어 InnoDB 스토리지 엔진이 데이터를 필요로 할 때 해당 데이터 페이지를 읽어서 각 조각에 저장함
- 버퍼 풀의 페이지 크기 조각을 관리하기 위해 InnoDB 스토리지 엔진은 크게 LRU 리스트, 플러시(Flush) 리스트, 프리(Free) 리스트라는 3개의 자료 구조를 관리함
- 프리 리스트: 버퍼 풀에서 실제 사용자 데이터로 채워지지 않은 비어 있는 페이지들의 목록으로, 사용자의 쿼리가 새롭게 디스크의 데이터 페이지를 읽어야 할 때 사용
- LRU 리스트: LRU와 MRU가 리스트가 결합된 형태
- 관리 목적: 디스크로부터 한 번 읽어온 페이지를 최대한 오랫동안 InnoDB 버퍼 풀의 메모리에 유지해 디스크 읽기 최소화- 과정
1. 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사
A. InnoDB 어댑티브 해시 인덱스를 이용해 페이지 검색
B. 해당 테이블의 인덱스(B-Tree)를 이용해 버퍼 풀에서 페이지 검색
C. 버퍼 풀에서 이미 데이터 페이지가 있었다면 해당 페이지의 포인터를 MRU 방향으로 승급
- 디스크에서 필요한데이터 페이지를 버퍼 풀에 적재, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼 풀 LRU 헤더 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더 부분으로 이동
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가 최근에 얼마나 접근했었는지에 따라 나이가 부여되며, 버퍼 풀에 상주하는 동안 쿼리에서 오랫동안 상주하지 않으면 데이터 페이지에 부여도니 나이가 오래되고 해당 페이지는 결국 버퍼 풀에서 제거, 버퍼 풀의 데이터 페이지가 쿼리에 의해 사용되면 아이가 초기화되어 다시 젊어지고 MRU의 헤더 부분으로 옮겨짐
- 필요한ㄷ ㅔ이터가 자주 접근되었다면 해당 페이지의 인덱스 키를 어댑티브 해시 인덱스에 추가
- 따라서, 자주 사용되면 InnoDB 버퍼풀의 MRU 영역에 계속 살아있음
- 사용되지 않으면 LRU 끝으로 밀려나 버퍼 풀에서 제거
- 과정
- 플러시(Flush) 리스트: 디스크로 동기화되지 않은 데이터를 가진 데이터 페이지(더티 페이지)의 변경 시점 기준의 페이지 목록 관리
- 디스크에서 읽은 상태에서 변경이 없다면 관리되지 않고, 일단 한 번 데이터의 변경이 가해진 데이터 페이지는 플러시 리스트에 관리되고, 특정 시점이 되면 디스크로 기록- 데이터가 변경되면 InnoDB는 변경 내용을 리두 로그에 기록하고, 버퍼 풀의 데이터 페이지도 변경 내용을 반영
- 리두 로그의 각 엔트리는 특정 데이터 페이지와 연결됨
- but, 리두 로그가 디스크로 기록되었다고 해서 데이터 페이지가 디스크로 기록되었다는 것을 항상 보장하지는 않음
- 반대의 경우 InnoDB 스토리지 엔진은 체크포인트를 발생시켜 디스크의 리두 로그와 데이터 페이지의 상태를 동기화하게 됨
- 체크포인트: MySQL 서버가 시작될 떄 InnoDB 스토리지 엔진이 리두 로그의 어느 부분부터 복구를 실행해야 할지 판단하는 기준점을 만드는 역할
4.2.7.3 버퍼 풀과 리두 로그
-
InnoDB 버퍼 풀은 서버의 메모리가 허용하는 만큼 크게 설정하면 할수록 쿼리 성능이 빨라짐 => 근데 이건 데이터 캐시 기능만 향상시킴
-
InnoDB 버퍼 풀은 DB 서버 성능 향상을 위해 데이터 캐시와 쓰기 버퍼링이라는 두 가지 용도가 있음
-
쓰기 버퍼링 기능까지 향상시키려면 InnoDB 버퍼 풀과 리두 로그의 관계 이해가 필요
-
일단 InnoDB 버퍼 풀이 클린 페이지, 더티 페이지를 가지고 있음 => 더티 페이지는 데이터 상태가 달라서 언젠간 디스크에 기록 되어야 함
- 근데 버퍼 풀에 더티 페이지가 무한정 있을 수는 없으니까 => 데이터 변경이 계속 발생하면 리두 로그 파일에 기록된 로그 엔트리가 어느 순간 다시 새로운 로그 엔트리로 덮어 씌워짐
=> 따라서 InnoDB 스토리지 엔진은 전체 리두 로그 파일에서 재사용 가능 공간과 재사용 불가능한 공간을 구분해서 관리해야 하는데, 재사용 불가능한 공간을 활성 리두 로그라고 함 -
로그 파일 공간은 순환 사용하지만, 기록될 때마다 로그 포지션은 증가된 값을 갖고 LSN이라 칭함
-
주기적으로 체크포인트 이벤트를 발생시켜 => 리두 로그와 버퍼 풀의 더티 페이지를 디스크로 동기화하는데, 이러면 발생한 체크포인트 중 가장 최근 체크포인트의 지점의 LSN이 활성 리두 로그 포인트의 시작점이 된다
-
하지만 활성 리두 로그 공간의 마지막은 계속해서 증가하므로 체크포인트와 무관
-
체크포인트 에이지: 활성 리두 로그 공간의 크기
-
그러니까 일단 이해가 안 됐고 리두 로그 사이즈를 잘 고려하자(112p - 113p)
4.2.7.4 버퍼 풀 플러시
-
8.0부터 대부분의 서비스에서는 더티 페이지를 디스크에 동기화하는 부분(더티 페이지 플러시)에서 예전과 같은 디스크 쓰기 폭증 현상 발생 X
-
디스크 쓰기 동기화와 관련된 시스템 설정들이 있지만 성능 문제가 발생하지 않는다면 굳이 조정할 필요는 없다
-
2개의 플러시 기능을 백그라운드로 실행
4.2.7.4.1 플러시 리스트 플러시 (일단 나중에 돌아옴)
4.2.7.4.2 LRU 리스트 플러시
4.2.7.5 버퍼 풀 상태 백업 및 복구
-
5.6 버전부터 버퍼 풀 덤프 및 적재 기능이 도입되어 innodb_buffer_pool_dump_now 시스템 변수를 이용해 현재 InnoDB 버퍼 풀 상태 백업 가능
-
innodb_buffer_pool_load_now 시스템 변수를 이용해 MySQL 서버를 다시 시작했을 때 백업된 버퍼 풀의 상태 다시 복구 가능
-
InnoDB 스토리지 엔진이 버퍼 풀의 LRU 리스트에서 적재된 데이터 페이지의 메타 정보만 가져와서 저장하기 때문에 버퍼 풀 백업 파일 크기는 버퍼 풀이 엄청 처도 몇십 MB 이하임 => 그래서 백업은 짱 빠름
-
근데 백업된 버퍼 풀의 내용을 다시 버퍼 풀로 복구하는 과정은 InnoDB 크기에 따라 시간이 걸림 => 백업된 내용에서 각 테이블의 데이터 페이지를 다시 리스크에서 읽어와야 하니까
-
그래서 시스템 변수로 상태값 확인 가능
4.2.7.6 버퍼 풀의 적재 내용 확인
- 8.0 버전부터 informaiton_schema 데이터베이스에 innocached_indexs 테이블 추가: 테이블의 인덱스별로 데이터 페이지가 얼마나 InnoDB 버퍼 풀에 적재되어 있는지 확인 가능
4.2.8 Double Write Buffer
-
리두 로그는 리두 로그 공간의 낭비를 막기 위해 페이지의 변경된 내용만 기록함
-
그래서 InnoDB의 스토리지 엔진에서 더티 페이지를 디스크 파일로 플러시할 때 일부만 기록되는 문제 발생 => 그 페이지 내용 복구 못할 가능성도 있음
-
이 현상을 파셜 페이지, 톤 페이지라고 함 => 하드웨어 오작동이나 시스템 비정상 종료 등으로 발생 가능
-
이 문제를 막기 위해 Double-Write 기법 사용
-
innodb_doubleWrite 시스템 변수로 제어 가능
방법
- 더티 페이지를 디스크로 플러시한다
- 실제 데이터 파일에 변경 내용을 기록하기 전 해당 더티 페이지를 우선 묶어 한 번의 디스크 쓰기로 시스템 테이블스페이스의 DoubleWrite 버퍼에 기록
- 그러고 각 더티 페이지를 파일의 적당한 위치에 하나씩 랜덤으로 쓰기 실행
- 실제 파일에 다 적히면 DoubleWrite 버퍼 공간 기록이 필요없어짐 => 중간에 실패했을 때만 원래의 목적으로 사용됨
- 만일 실패된 데이터가 있으면 원본이랑 DoubleWrite랑 비교해서 다른 값은 DoubleWrite 값 복제해서 기록
- 보통 데이터의 안정성을 위해 자주 사용
- HDD처럼 자기 원판이 회전되는 저장 시스템은 한 번의 순차 디스크 쓰기라 부담이 되지 않지만, SSD처럼 랜덤 IO나 순차 IO나 비용이 비슷한 저장 시스템에서는 부담스러움
=> 데이터의 무결성이 매우 중요한 서비스에서 활성화하자
