사용자 증가에 따른 아키텍처 진화 과정 (AWS 영상 듣고 1차 정리)
사용자 수 < 1,000
주요 고려사항
- 서버 선정 및 이중화 구성
- DB 구성
- 사용자 인증 서비스
- 소스코드 관리 및 배포
용도에 맞는 EC2 서버 선택
(1) 업무에 적합한 서버 선정
- CPU, 메모리,I/O별 인스턴스 타입
- 필요 성능에 따른 스토리지 선택
(2) 필요 시 손쉬운 서버 타입 변경 - 용량 산정 고민 X
EC2
- AWS에서 비용, 성능, 용량면에서 탄력적인 클라우드 컴퓨터를 제공하는 서비스 (클라우딩 컴퓨터 서비스)
서버 이중화 구성
- 사용자가 지정하거나 AWS가 가용 영역을 알아서 지정하면 서로 다른 가용 영역에 이중화 구성을 함
AWS Elastic Load Balancing을 활용한 부하 분산
- 여러 서버를 구성할 경우에 요청이 분산되도록 Load Balancing 기능이 필요
- AWS에선 ELB를 쓰라고 함
- ALB VS NLB (AWS에서 제공하는 서비스인데, 개념보단 AWS 기술이니까 필요할 때 검색해서 적절한 서비스를 이용하면 될듯함)
Load Balancing
- '부하 분산' => 일을 밸런스 있게 맞추는 기능
- 한 곳의 서버에 트래픽이 몰리는 것을 방지하고, 여러 서버에 적절히 분산시켜 주는 기능
Amazon RDS
- 이건 내가 써 봐서 정리
- 6개 DB 엔진 기반의 관계형 데이터베이스 관리형 서비스
- Amazon Aurora, MySQL, PostgreSQL, MariaDB, SQL Server, ORACLE
그럼 NoSQL 쓸 땐 이런 서비스가 딱히 안 필요한가??
- AWS에선 DynamoDB(NoSQL 전용 관리형 서비스)를 사용, 높은 트래픽을 자동으로 처리할 수 있음(카카오톡 메시지 저장처럼 빠른 응답이 필요한 서비스에 적합)
특징
- 간편한 관리
- 뛰어난 확장성
- 가용성 및 내구성
- 성능과 낮은 비용
기본 아키텍처
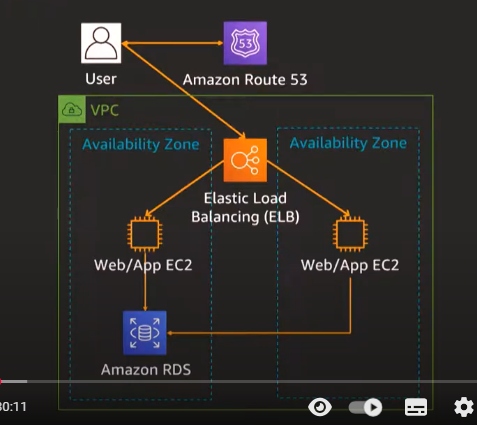
- Amazon Route s3 : 가용성과 확장성이 뛰어난 클라우드 Domain Name System(DNS) 웹 서비스
DNS
- 사용자에게 친숙한 도메인 이름을 컴퓨터가 네트워크에서 서로를 식별할 때 사용하는 IP 주소로 변환하는 인터넷 표준 프로토콜의 구성 요소
사용자 인증 서비스
Amazon Cognito를 이용한 빠른 인증 구현
- 관리형 사용자 디렉토리
- 내장 UI
- Federation
- AWS 크리덴셜
- 표준 토큰
Amazon Cognito
- 웹/모바일 앱에 대한 인증/권한 부여, 사용자 관리 제공, 로그인 기능 제공 서비스
사용자 수 > 1,000
주요 고려사항
- 시스템 확장
- DBMS 고 가용성
- 백업
- 시스템 모니터링
EC2 오토 스케일링
- 사용자가 많아지게 되면 특정 시간대의 리퀘스트가 많이 몰리는 경우 발생
=> 이것에 대응하기 위해선 서버 대수가 탄력적으로 증가해야 함 - AWS는 EC2 오토 스케일링 기능으로 이것을 대응하게 해 줌
- 가변적 동시 접속자 대응
- 부하, 장애 대응, 비용 절감 효과
DBMS 고 가용성 고려
- DB 장애 시 시스템 서비스 불가
- DB가 Single Point of failure 상태
=> DB 고 가용성 방안 필요
DBMS 고 가용성
- DB 서버의 장애 상황에서 다운 타임을 최소화하기 위한 방안을 가르키는 경우가 많음
Amazon RDS 다중 AZ 배포 <= 클러스터링인가?
- 위의 방안으로 제공하는 기능
- 가용 영역 1에 Master 인스턴스, 가용 영역 2에 Stand-by 인스턴스 존재
- 동기식 물리적 복제를 통한 데이터 정합성
RDS 다중 AZ 배포는 클러스터링인가?
- 다중 AZ 배포 "고 가용성을 위한 이중화" <= 장애 대비
- 클러스터링 "여러 개의 DB 인스턴스를 하나의 논리적 DB로 운영하는 방식"
=> 비슷하지만 목적이 다른 느낌
백업
- AWS Backup 서비스를 통해서 백업 관리를 자동화해라
모니터링
- CloudWatch를 활용한 모니터링
사용자 수 > 10,000
주요 고려사항
- 성능
- 부하분산
Amazon CloudFront
- 성능과 부하분산을 해결하기 위해 사용 가능한 서비스
- AWS CDN 서비스
서버 부하 줄이는 방법
(1) 사용자가 요청 전송
(2) 해당 요청이 사용자와 가까운 클라우드 프론트 팝으로 먼저 전달
(3) 한번 응답한 캐시 컨텐츠를 캐시해 둠
(4) 다음에 동일 소스 요청이 오면 캐시에 뒀던 데이터로 직접 응답을 줌
(5) 이 과정으로 빠르게 사용자에게 응답 전송 가능
콘텐츠 전송 네트워크(CDN)
- 데이터 사용량이 많은 애플리케이션의 웹페이지 로드 속도를 높이는 상호 연결된 서버 네트워크
- 주 목적은 대기 시간을 줄이거나 네트워크 설계로 인해 발생하는 통신 지연을 줄이는 것
- 클라이언트와 웹 사이트 서버 간에 중간 서버를 두어 효율성을 높임
- 웹 서버에 대한 웹 트래픽을 줄이고, 대역폭 소비를 줄이며, 애플리케이션 사용자 환경 개선
- 장점 : 페이지 로드 시간 단축, 대역폭 비용 절감, 콘텐츠 가용성 제고, 웹 사이트 보안 강화
Amazon Aurora 읽기 복제본 오토스케일링
- DB 부하를 줄이면 시스템 성능 개선이나 부하 분산에 도움이 됨
RDS 읽기 복제본 인스턴스로 DB 부하 분산
캐시 적용
- 빈번하게 액세스해야 하는 데이터의 경우엔 DB보다 캐시 서버에서 빠르게 응답 제공 가능
사용자 수 > 100,000
주요 고려사항
- Loosely Copled 아키텍처, 분산 아키텍처
- 서버리스 아키텍처
- 분산 시스템 모니터링
비동기 서비스를 이용한 Loose coupling
- 서비스 간의 결합도를 낮추는 아키텍처로 대표적인 기술은 키와 토픽 방식으로 메세지를 전달하는 것
서버리스 아키텍처
- 사용자가 서버를 미리 프로비저닝 해 두거나 관리할 필요없이, 애플리케이션 로직만 개발해 놓으면 요청에 따라 탄력적으로 리소스가 스케일링되는 컴퓨팅 서비스
- 대표적인 서비스는 AWS Lambda
용도에 적합한 DB 서비스 적용
분산 아키텍처 적용
=> 이것을 더 발전시키면 마이크로 서비스 아키텍처로 진화할 수 있음
모니터링
- AWS X-Ray가 기능 제공
사용자 수 > 1,000,000
주요 고려사항
- 재해복구(DR)/멀티 리전 시스템 고려
- 멀티 리전 시스템 배포
CloudFormation으로 인프라 리소스를 모델링
s3 교차 리전 복제 (다른 서비스도 비슷한 기능이 존재한다 어쩌구)
- 다른 리전으로 시스템을 확장하려면 인프라뿐만 아니라 데이터도 다른 리전으로 잘 전송할 수 있어야 함
멀티 리전 배포
멀티 리전 시스템
사용자 수 > 10,000,000
주요 고려사항
- 글로벌 시스템 확장
- 멀티 리전 시스템 확대
대용량 트래픽 처리 (2차 정리)
대용량 트래픽
- 특정 웹사이트나 서비스에 짧은 시간 내에 대량의 요청이 발생하는 상황
- EX) 온라인 쇼핑몰 할인 이벤트, 스트리밍 서비스의 실시간 방송, 게임 서버의 출시 직후 대량 접속
대용량 트래픽 처리 방법
- 대용량 트래픽을 효과적으로 처리하려면 서버의 부하를 줄이고, 시스템을 확장하고, DB와 네트워크 구조를 최적화해야 함
1. 수직 확장(Scale-Up) VS 수평 확장(Scale-out)
- Scale-up : 기존 서버의 성능을 향상(CPU, RAM 업글) -> 한계 있음
- Scale-out : 여러 대의 서버를 추가하여 부하 분산 -> 클라우드 환경에서 일반적으로 선호
Scale-out
1. 방법
- 애플리케이션을 여러 서버에 배포하고 트래픽 분산
- 데이터베이스 샤딩 혹은 읽기 복제본 활용
- 클라우드 환경에서 Auto Scaling을 사용하여 필요할 때만 서버 추가/삭제
- 장점
- 무한에 가까운 확장성
- 특정 서버 장애시 다른 서버가 트래픽 처리할 수 있어 안정성 Good
- 단점
- 애플리케이션이 여러 서버에 동작하도록 설계 필요
- 부하 분산을 위한 로드 밸런싱 필수
2. 로드 밸런싱(Load Balancing)
- 클라이언트 요청을 여러 서버로 분산하여 과부하 방지
- 알고리즘 찾아보기
알고리즘
1. 라운드 로빈
- 요청을 서버에 순차적 배분
- 단순하지만 각 서버의 부하 고려 X
- Least Connections
- 현재 가장 적은 연결을 가진 서버로 트래픽 분배
- 실시간 부하를 고려하여 좀 더 효율적
- IP Hash
- 클라이언트 IP 주소를 해싱하여 특정 서버로 라우팅
- 특정 사용자가 항상 같은 서버에 연결되도록 보장 (세션 유지 필요할 때 사용)
3. DB 성능 개선
- 읽기/쓰기 분리
- 캐싱 적용 : Redis, Memcached 활용하여 반복 조회되는 데이터를 캐싱
- 샤딩(Sharding) : 데이터를 여러 DB 인스턴스로 나눠 저장하여 트래픽 분산
Redis, Memcached에 대해 알아보기
- Redis : 고급 기능이 있는 Key-Value 저장소
- Memcached : 단순한 Key-Value 저장소
4. CDN 활용
- 정적 콘텐츠 등을 사용자 가까운 곳에서 캐싱하여 빠른 응답
동작 방식
1. 사용자가 웹사이트 요청
2. CDN 노드(엣지 서버)가 가까운 위치에서 응답
3. 처음 요청 시 원본 서버에서 가져와 캐싱
4. 다음 요청부터는 캐시된 데이터로 응답하여 속도 향상
5. 비동기 처리 & 메시지 큐
- 요청을 바로 처리 X => 대기열(Queue)에 저장하여 비동기적 실행
- 메시지 큐(Kafka, RabbitMQ, SQS)에 넣어 비동기적 실행
Kafka, RabbitMQ에 대해 알아보기
6. 서버리스 아키텍처
- 특정 이벤트가 발생할 때만 실행되는 서버리스 컴퓨팅
7. 멀티 리전 & 재해 복구
- 서비스 장애를 대비해 여러 지역(리전)에 인프라 배포

기술 블로그