Introduction
쌩 텍스트로 학습하는 능력은 지도 학습의 의존성을 줄이는 데에 중요하다. 대부분 자연어처리 모델은 직접 라벨링한 데이터를 쓰는데, 데이터가 부족한 도메인에서 쓰기에는 한계가 있기 때문에, 라벨링이 되지 않은 데이터에서 annotation을 뽑아낼 수 있는 모델이 중요하다.
하지만 라벨이 없는 데이터에서 정보를 얻기란 두 가지 이유로 어려운데,
1. 전이를 할 수 있는 표현을 학습하기에 어떤 최적화 목표가 있는지 불분명하다.
2. 표현을 목표하는 태스크에 전이하기에 가장 효과적인 방법이 무엇인지 결정된 바가 없다.
비지도 사전 훈련 + 지도 파인튜닝 을 사용하는 반지도학습 모델을 소개한다.
- 약간의 조정만 해서 쓸 수 있는 보편적인 표현을 학습하는 것이 목표
- 학습 과정
1. 라벨이 없는 데이터에서 language model
2. 1에서 학습한 파라미터를 지도학습에 해당하는 타겟 태스크에 적용
- 트랜스포머 모델 사용
장기 의존성 문제 해결할 수 있는 모델 - 전이에는 traversal-style(그게 뭐시여)에서 파생된 task-specific 인풋 사용
Framework
- 방대한 코퍼스에 고용량의 언어 모델을 학습
- 라벨된 데이터가 있는 특정 태스크에 모델을 파인튜닝으로 조정
1. Unsupervised pre-training
비지돋된 코퍼스의 토큰 가 있을 때 이 likelihood를 최대화하기 위한 언어모델을 사용.
는 context window의 크기, 는 신경망 파라미터. SGD를 사용해서 훈련되었음.
언어 모델로 트랜스포머 디코더 사용. 인풋 토큰에 대해 멀티헤드 셀프 어텐션 적용하는 모델임
는 토큰들의 컨텍스트 벡터, n은 레이어 개수, 는 토큰 임베딩 매트릭스, 는 포지션 임베딩 매트릭스
2. Supervised fine-tuning
목적함수로 모델을 학습시킨 다음, 파라미터들을 지도 타겟 태스크에 적용함.
라벨된 데이터셋 안에 각 인스턴스는 인풋 토큰 과 라벨 가 존재.
인풋들은 사전학습된 모델을 지나서 마지막 트랜스포머 블록의 activation 값인 을 얻고, 이 값은 선형 아웃풋 층에 들어가서 파라미터로 를 예측하게 된다.
이렇게 되면 이 층은 이 목적함수를 최대화하는 방향으로 학습된다.
또한 부가적인 목적으로 파인 튜닝에 언어 모델을 추가하는 것이 지도 학습 모델의 일반화를 개선하고, 빠르게 수렴할 수 있게 하는 것을 발견했다.
그래서 이 목적에서는 다음의 함수를 최적화한다. 는 가중치이다.
결론적으로, 파인튜닝 단계에서 추가로 필요한 파라미터는 와 구분자 토큰에 대한 임베딩 뿐임.
다음은 1, 2 과정을 시각화한 그림이다.
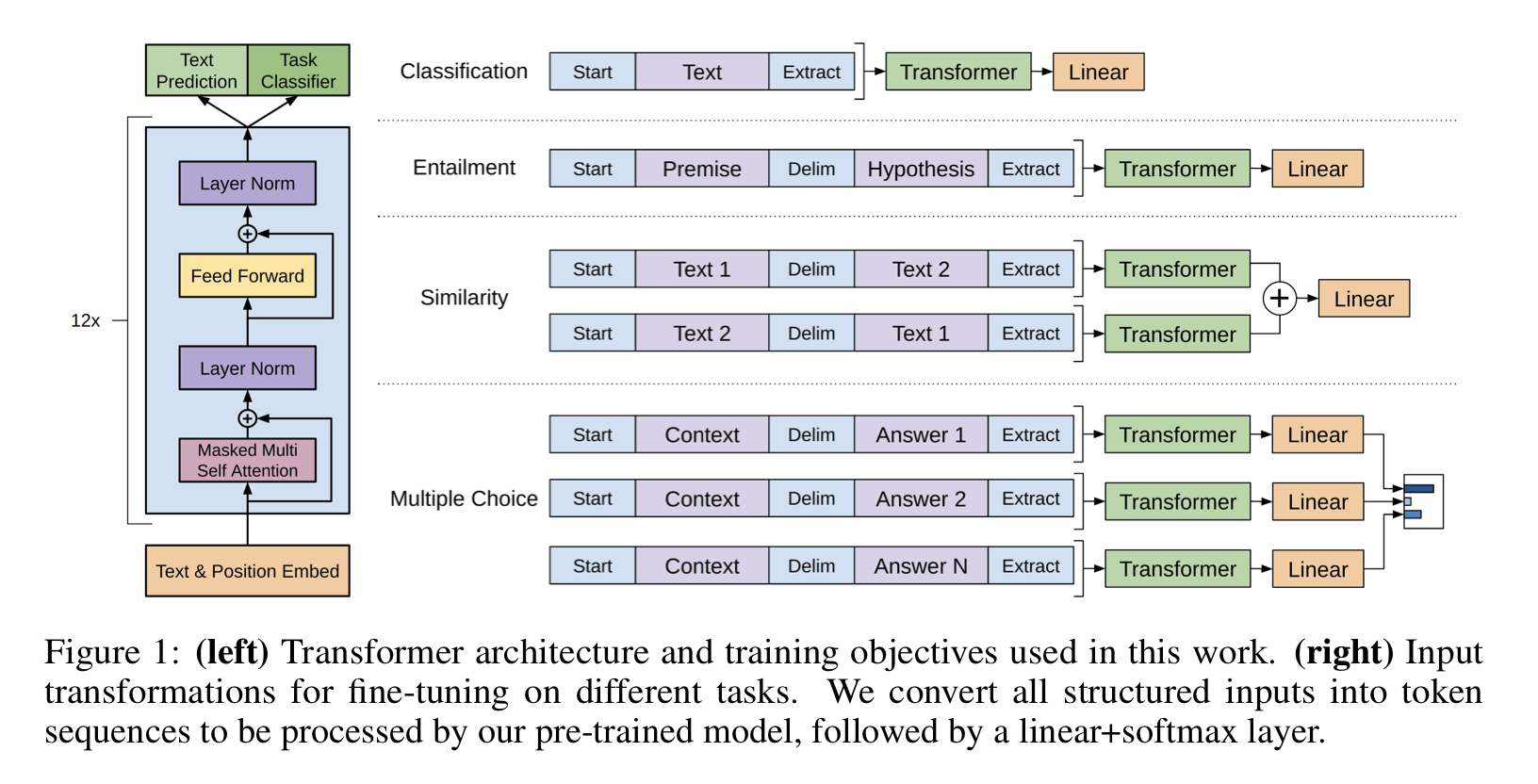
3. Task-specific input transformations
텍스트 분류와 같은 태스크는 바로 파인튜닝을 할 수 있지만, 질의응답이나 함의관계와 같은 태스크는 문장쌍 같은 구조화된 인풋이 필요하다. 하지만 사전학습 모델은 인접한 시퀀스들에 대해 학습했기 때문에, 이 구조를 맞춰주는 추가 작업이 필요하다.
이전 연구들은 태스크마다 맞춤 모델을 소개했지만, 여기서는 traversal style을 사용했다. 구조화된 인풋을 시퀀스로 변환하는 작업이다. 이 변환 작업은 큰 변화 없이도 사전학습 모델을 다양한 태스크에 적용할 수 있게 한다.
- Textual entailment task
전제 와 가설 토큰 시퀀스를 구분자 $를 사이에 넣어 합친다.
형태는 다음과 같다: p$h
- Similarity
비교하는 두 문장 간의 순서가 없기 때문에 인풋 시퀀스가 모든 가능한 순서를 담고 있도록 한다. 그리고 두 문장의 표현 을 생성하기 위해 독립적으로 처리하고 션형층에 들어가기 전에 더한다.
- Question Answering and Commonsense Reasoning
컨텍스트 문서 , 질문 , 가능한 답변 집합 가 주어진다. 와 를 각 답변과 더하고 사이에 구분자를 넣어준다.
형태는 다음과 같다:
각 시퀀스는 독립적으로 처리된 후 소프트맥스 층으로 정규화되어 가능한 답변에 대한 분포가 아웃풋으로 나온다.
Analysis
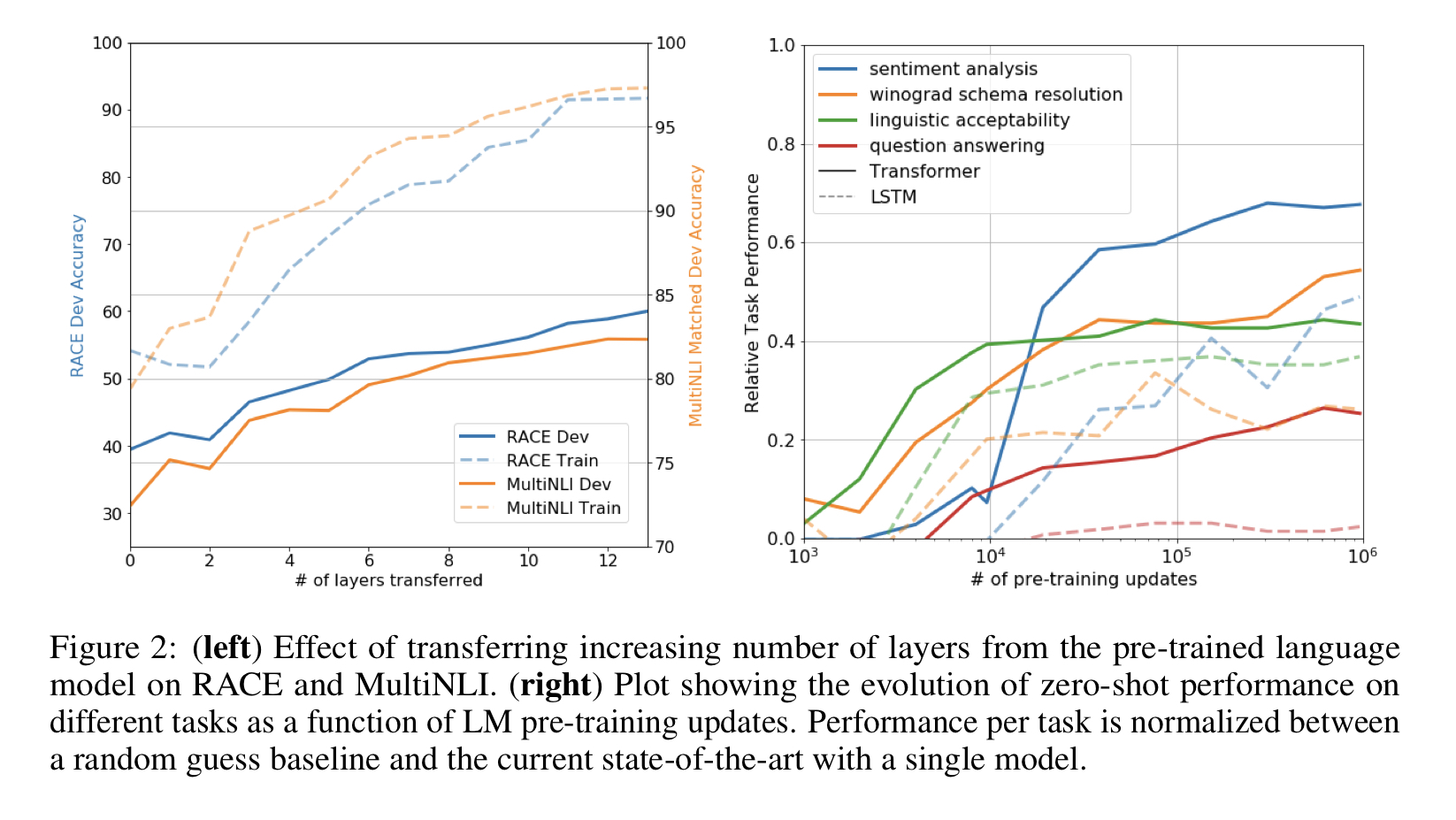
Impact of number of layers transferred
전이된 층의 개수에 따른 모델 성능 확인
MultiNLI와 RACE 데이터셋에 전이된 층의 개수에 따른 모델의 성능을 관찰한 결과 MultiNLI에는 모든 전이를 했을 때 성능이 최대 9% 까지 올라가는걸 확인함. 즉 전이된 각 층이 태스크 수행에 유용하다는걸 의미.
Zero-shot Behaviors (이해 못 함,,,)
왜 트랜스포머의 LM 사전학습이 효과적인가
- Zero-shot: 훈련 데이터가 거의 없어도 분류 가능하도록 학습하는 것.
먼저 두 가지의 가설을 세움.
1. 생성 모델은 언어 모델링 능력을 개선하기 위해 다양한 태스크를 학습한다.
2. 트랜스포머의 구조화된 attentional 메모리가 LSTM과 비교했을 때 전이에 도움이 된다.
지도된 파인튜닝 없이 태스크를 수행했을 때 성능이 어떤지 휴리스틱한 답을 디자인했다.
그래프를 보면 휴리스틱이 안정적이고 지속적으로 증가한 것으로 보아 generative pre-training이 다양한 태스크의 기능성을 학습하는 데 도움이 되는 것을 확인했다.
그리고 LSTM이 제로샷 성능에서 더 높은 분산을 보인다. 즉 트랜스포머의 inductive bias가 전이에 도움이 된다.
- inductive bias: 학습에서는 보지 못한 데이터에 대해 예측을 할 수 있도록 추가적으로 사용하는 가정. 본 적이 없는 데이터에 대해 판단을 내리기 위해 학습과정에서 습득한 bias
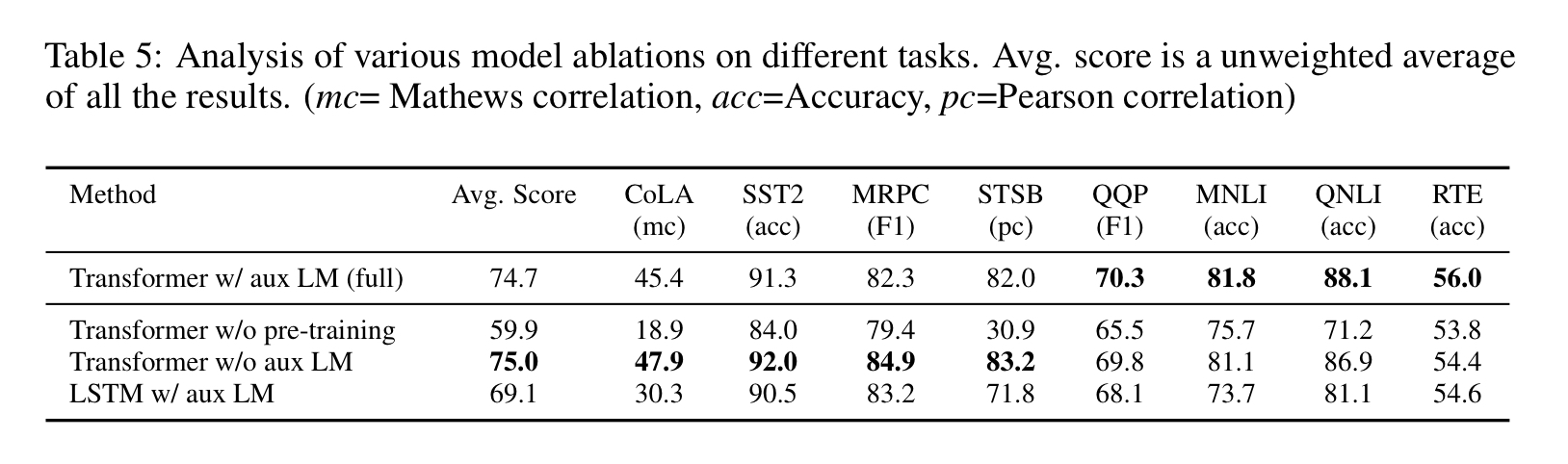
Ablation studies
3가지의 다른 ablation studies 비교
ablation: 삭마, 절제
라고 함. 하나씩 제외하고 성능 비교하는걸 말하는 듯.
-
파인튜닝 과정에서 LM 목적 없이
부가적인 목적이 NLI, QQP 태스크에서 도움이 되는 것을 확인할 수 있다. 큰 데이터셋에서는 효과를 보이지만 작은 데이터셋은 그렇지 않았다. -
트랜스포머와 단일층 2048 유닛 LSTM 비교
LSTM은 평균 5.6의 스코어가 떨어진 것을 확인할 수 있었다. MRPC에서만 트랜스포머 능가했음. -
사전학습 없이 트랜스포머를 바로 지도학습 태스크에 훈련
사전학습 없이는 모든 태스크에서 성능이 안 좋았고, 전체 모델과 비교했을 때 14.8%의 성능 저하를 확인함.
-끝-
