Window Function
- 로우별 그룹을 지정해서 값을 집계하는 함수
- group by 절과는 다름
- group by 절 사용 시, 집계 대상에 따라 로우 수가 줄어들지만, window 함수는 그렇지 않음
-> 로우 수는 그대로, 집계 값 산출 가능
- 집계 함수 :
sum,max,min,avg,count... - 순위 함수 :
row_number,rank,dense_rank - 행 순서 함수 :
first_value,last_value,lag,lead등이 있음 - 비율 함수 :
percent_rank,ratio_to_report,cume_dist,ntile
- window 함수 구문
PARTITION BY: Group by 같은 역할
ORDER BY: ORDER BY 역할
ROW 또는 RANGE: WHERE의 역할 : window 절
window 함수() OVER (PARTITION BY col1, col2, ...
ORDER BY col1, col2,...
ROW 또는 RANGE )
# PARTITION BY : 분석함수 집계가 되는 대상으로 로우 값의 범위, 그룹
# PARTITION BY 생략시 전체 로우가 분석함수 집계 대상이 됨
# ORDER BY : 분석함수 계산 시, 고려되는 로우 순서- WINDOW 절 : ROW 또는 RANGE
1. Ranking Function
1️⃣ row_number() : 일련 번호
창 파티션 내의 행 순서에 따라 한 행부터 시작하여 각 행에 대해 고유한 일련 번호를 반환합니다.
- Examples
# Task1 : 부서별로 사원의 급여 순으로 순번을 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, row_number() OVER (PARTITION BY b.department_id
ORDER BY a.salary) as dept_sal_seq
, a.salary
FROM employees a
JOIN department b
on a.department_id = b.department_id
ORDER BY 2,4;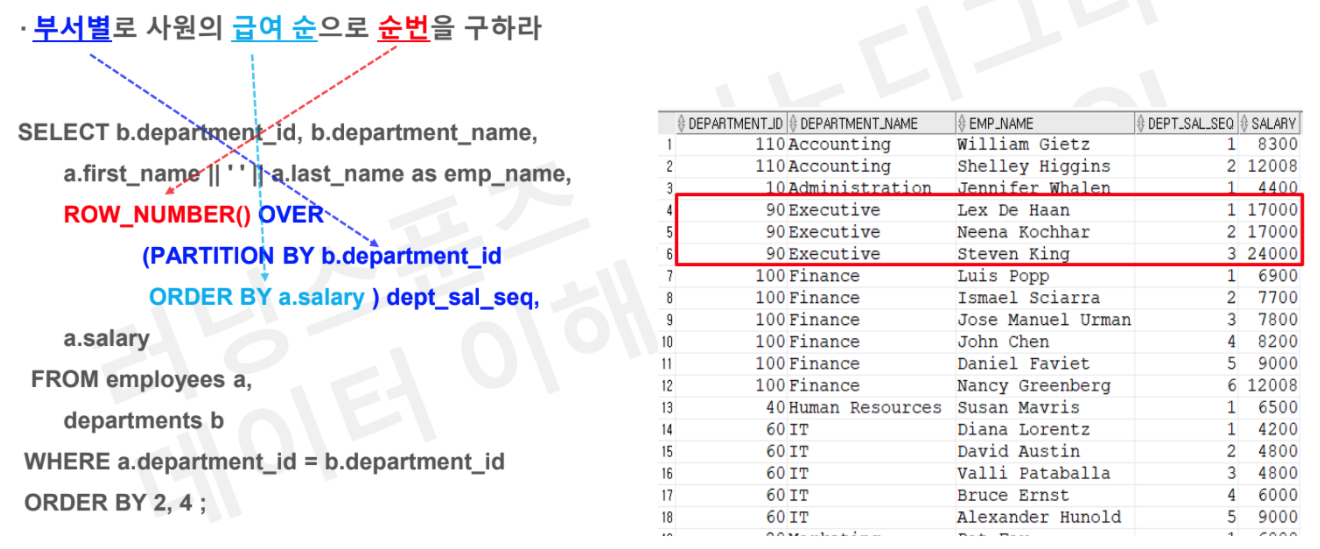
# Tsak2 : 부서별로 사원의 급여가 높은 순으로 순번을 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, row_number() OVER (PARTITION BY b.department_id
ORDER BY a.salary desc) as dept_sal_seq
, a.salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;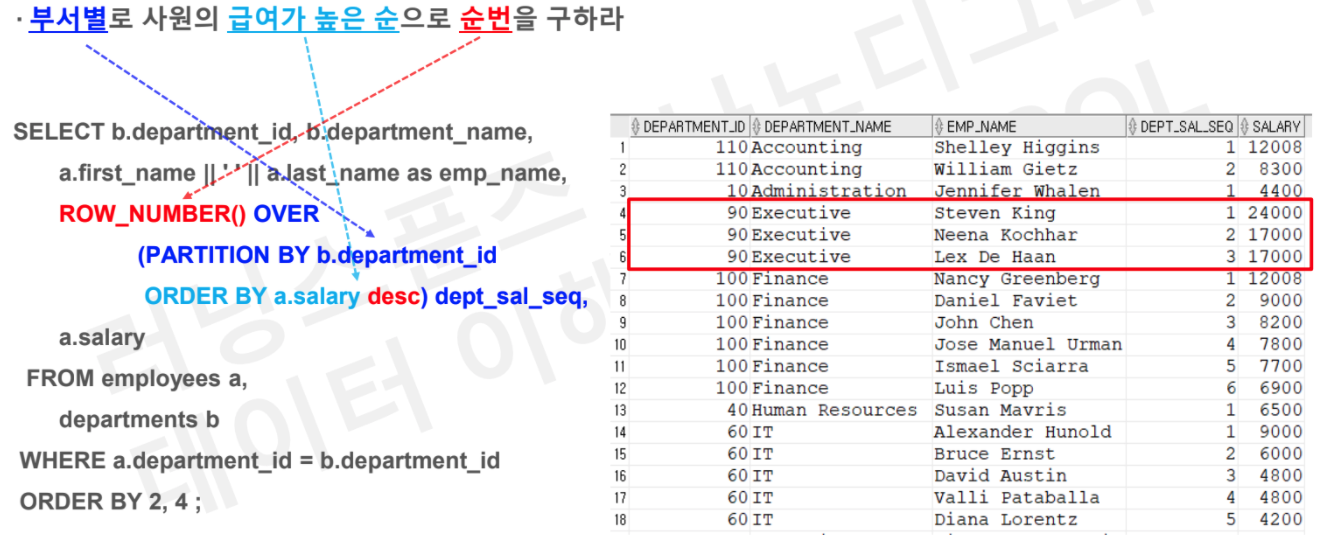
# Task3 : 전 사원의 급여가 높은 순으로 순번을 구하라
-- 방법 1
SELECT b.department_id, b.department_name,
, a.first_name || ' ' || a.last_name as emp_name
, row_number() OVER (ORDER BY a. salary desc) as sal_seq
, a.salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 4;
--방법 2: 가상컬럼 rownum 활용
SELECT b.department_id, b.department_name,
, a.first_name || ' ' || a.last_name as emp_name
, a.salary
, rownum as sal_seq
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 4;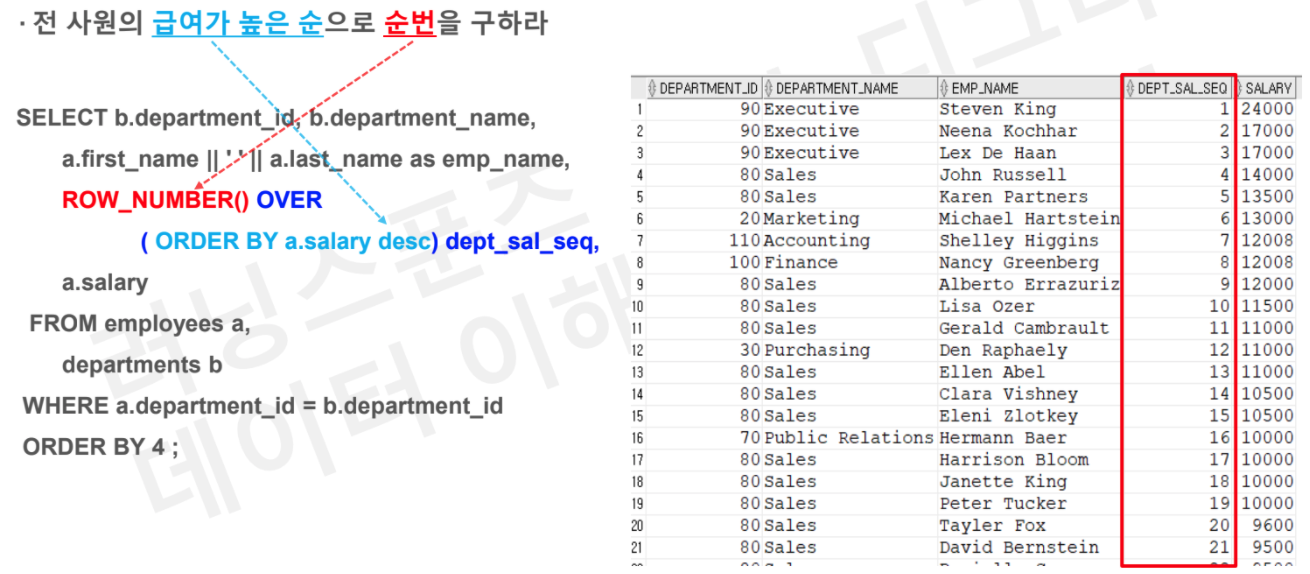
2️⃣ rank() : 순위
- 그룹에 있는 값의 순위를 반환
- row_number()와 쿼리 결과 값 다른점 체크할것
- Examples
# Task1 : 부서별로 사원의 급여가 높은 순으로 순위를 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, rank() OVER (PARTITION BY b.department_id
ORDER BY a.salary desc) as dept_sal_seq
, a.salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;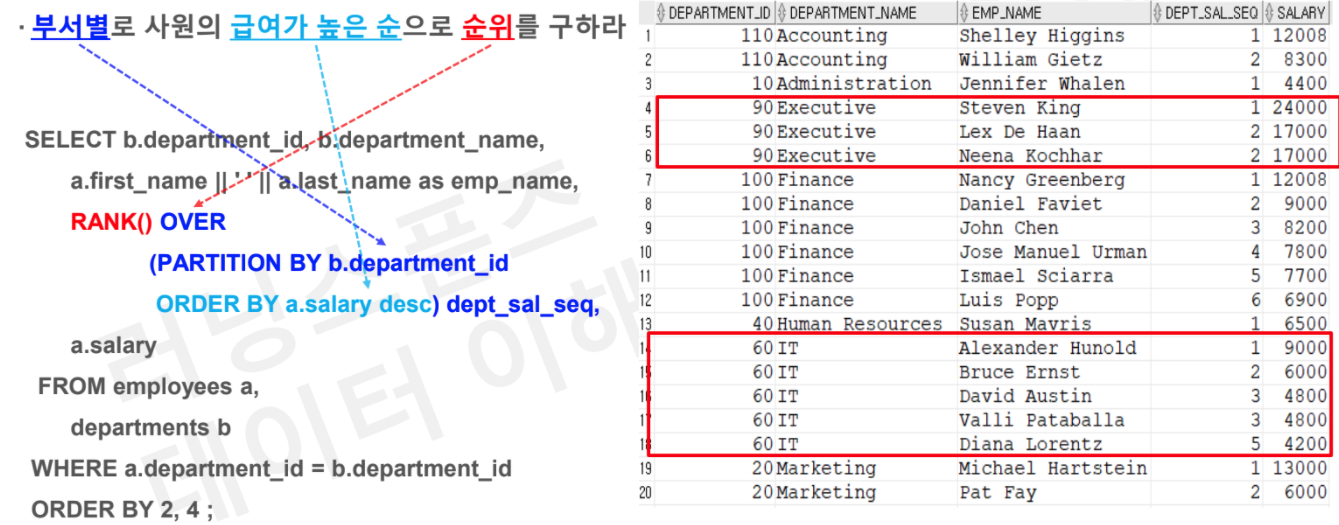
3️⃣ dense_rank() : 누적 순위
- 그룹에 있는 값의 순위를 반환
- 동점 값이 시퀀스에서 차이를 만들지 않는다는 점을 제외하면 rank()와 유사
- Example
# Task1 : 부서별로 사원의 급여가 높은 순 누적순위
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, dense_rank() OVER (PARTITION BY b.department_id
ORDER BY a.salary desc) as dept_sal_seq
, a.salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;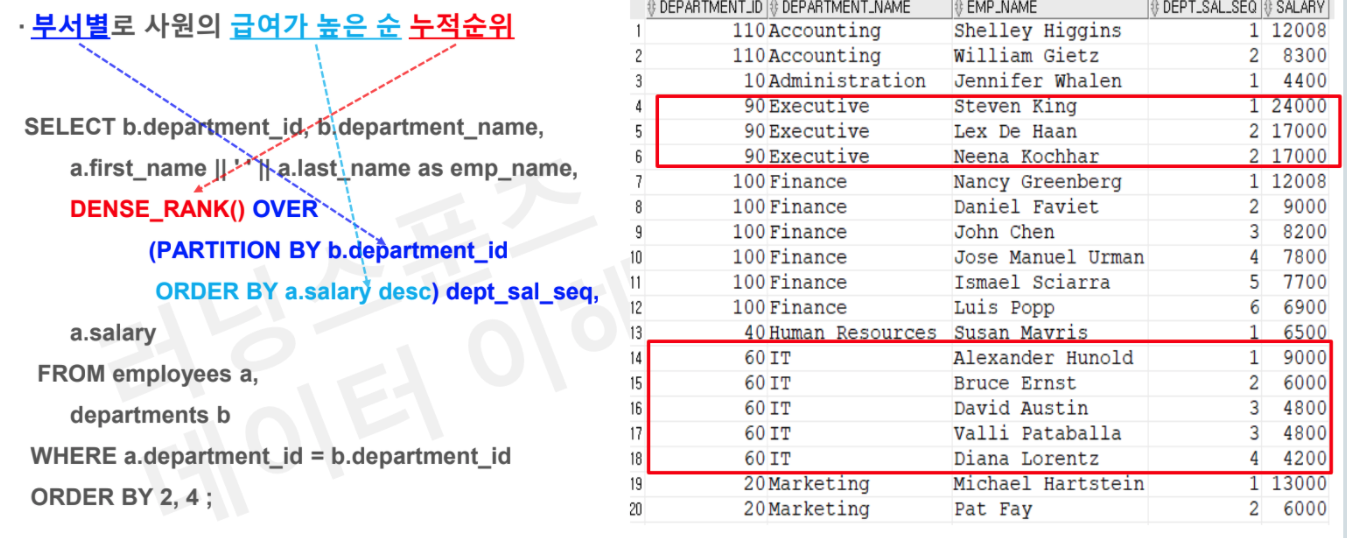
2. Value Functions
1️⃣ LEAD(expr, offset, default) : 후행 로우값
- 현재 행 뒤에 있는 행의 값을 반환
- offset : 간격 띄우기로 생락 시 기본 오프셋은
1 - 후행 로우값이 없을경우 default 값이 반환
- default 값이 지정되지 않으면
null이 반환 - Examples
# Task 1 : 부사별, 입사일자 순, 직후 사원의 급여를 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.hire_date
, a.salary
, LEAD(salary) OVER (PARTITION BY b.department_id
ORDER BY a.hire_date) as lead_salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;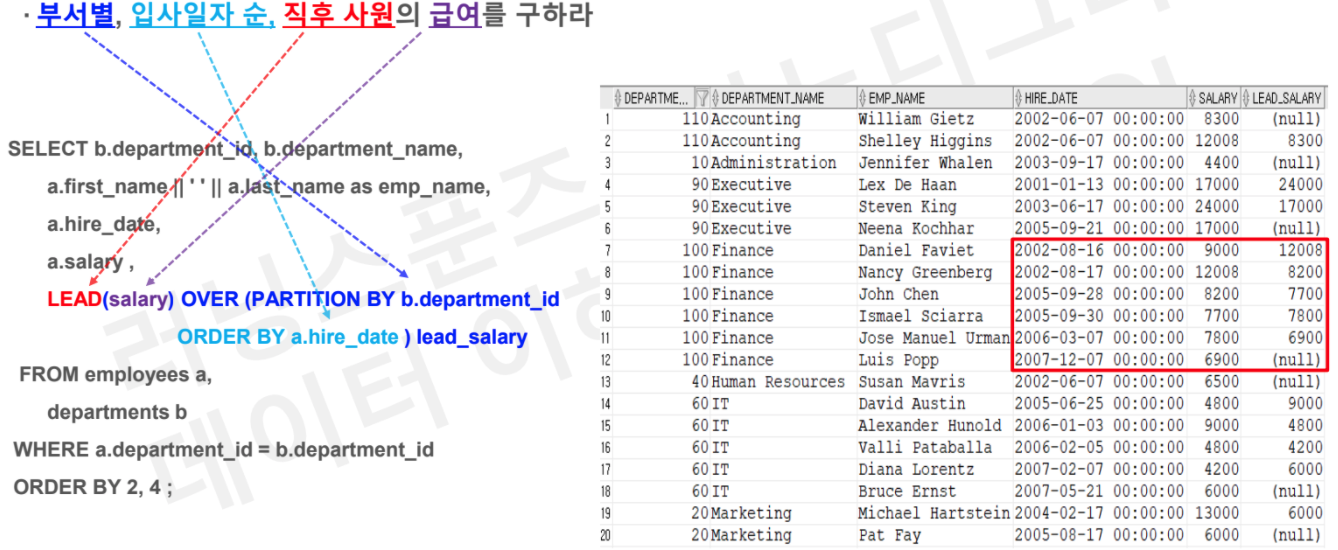
# Task1 : 부서별, 입사일자 순, 직후 사원의 급여를 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.hire_date
, a.salary
, LEAD(salary,1,0) OVER (PARTITION BY b.department_id
ORDER BY a.hire_date) as lead_salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;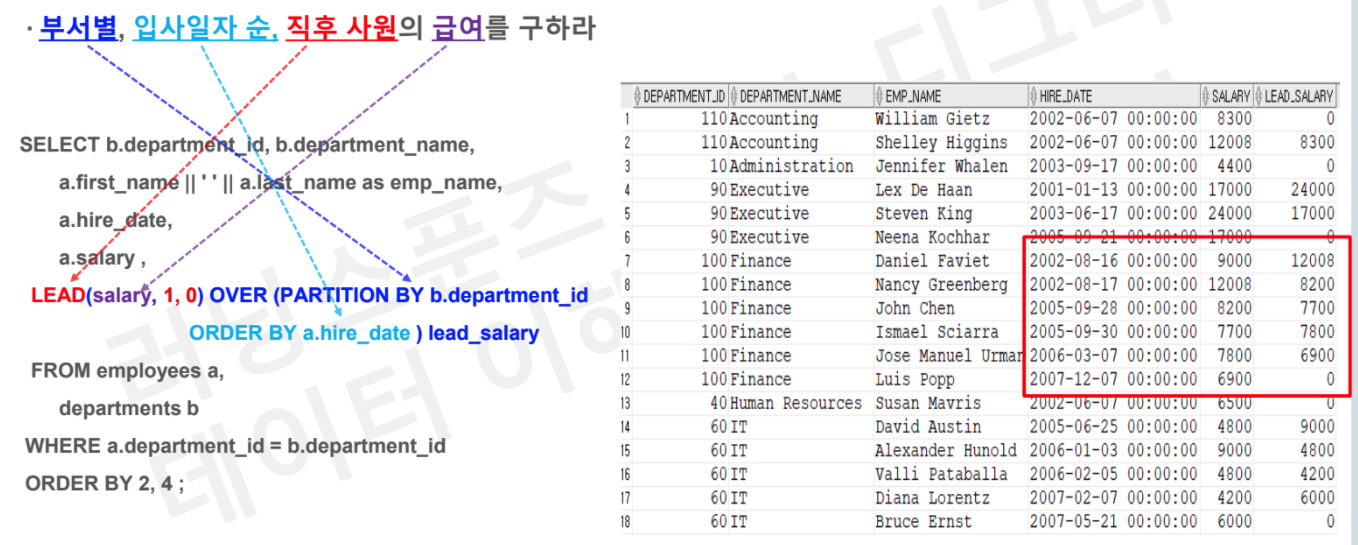
# Task 2 : 부서별, 입사일자 순, 2 로우 후 사원의 급여를 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.hire_date
, a.salary
, LEAD(salary,2,0) OVER (PARTITION BY b.department_id
ORDER BY a.hire_date) as lead_salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;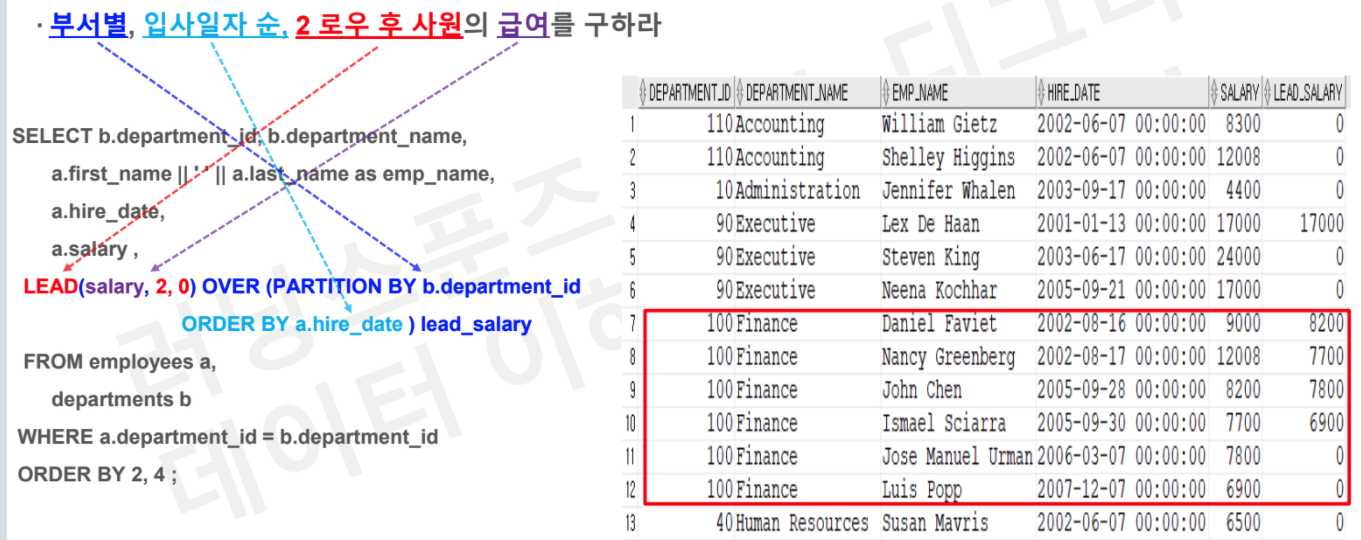
2️⃣ LAG(expr, offset, default) : 선행 로우값
- Examples
# Task 1 : 부서별, 입사일자 순, 직전 사원의 급여를 구하라
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.hire_date
, a.salary
, LAG(salary, 1, 0) OVER (PARTITION BY b.department_id
ORDER BY a.hire_date) as lag_salary
FROM employees a
JOIN departments b
on a.department_id = b.department_id
ORDER BY 2,4;
3️⃣ first_value(x)
- Returns the first value of the window
4️⃣ last_value(x)
- Returns the last value of the window
3. Aggregate Function
집계 함수는 현재 행의 window 프레임 내에 있는 행의 각 행에 대해 계산됨
sum, min, max, avg, count
- Examples
# Task 1 : 부서별 평균 급여와 사원의 급여를 동시에 조회
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.salary
, ROUND(AVG(a.salary) OVER (PARTITION BY b.department_id
ORDER BY b.departmnet_id), 0) as dept_avg_sal
FROM employees a
JOIN depatments b
on a.department_id = b.department_id
ORDER BY 2,3;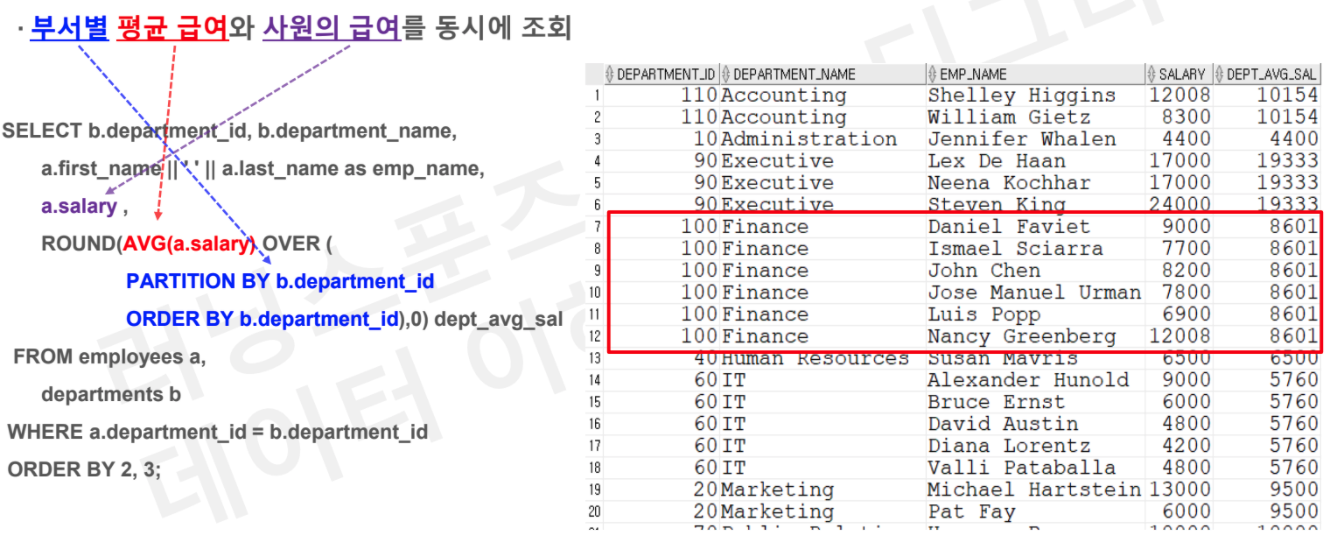
# Task 2 : 사원의 급여왕 부서별 누적 급여 조회
SELECT b.department_id, b.department_name
, a.first_name || ' ' || a.last_name as emp_name
, a.salary
, ROUND(SUM(a.salary) OVER(PARTITION BY b.department_id
ORDER BY a.salary), 0) as dept_cum_sum
FROM employees a
JOIN department b
on a.department_id = b.department_id
ORDER BY 2,4;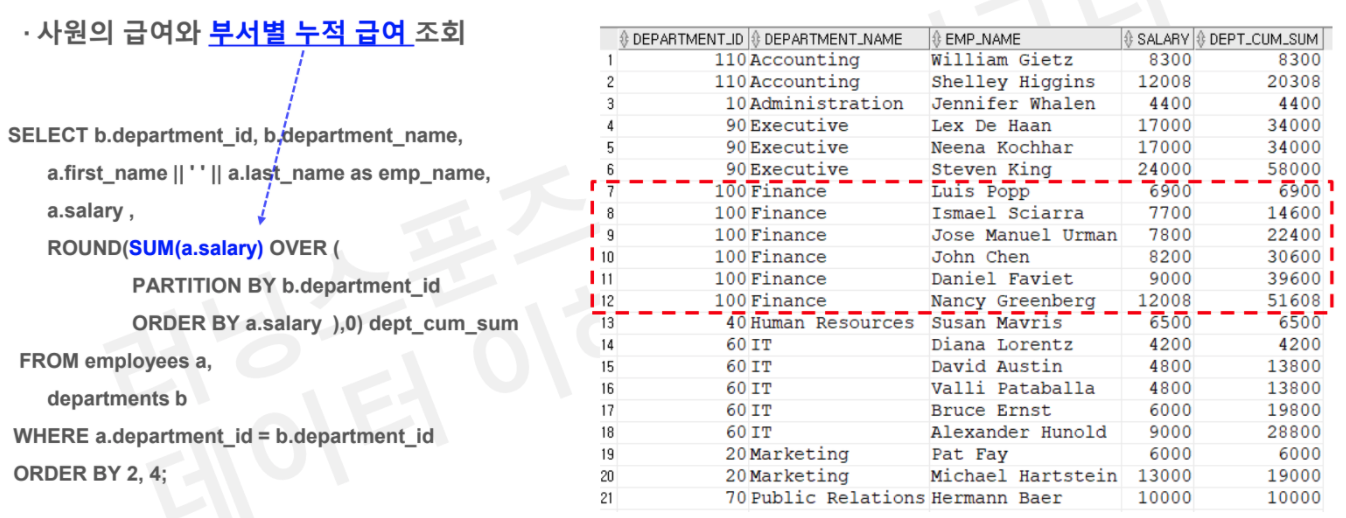
| https://prestodb.io/docs/current/functions/window.html#aggregate-functions
