웹스크랩핑 vs 크롤링
- 웹스크랩핑 : 웹사이트에서 내가 원하는(필요한) 부분의 데이터만 읽어오는 것
- 크롤링 : 검색엔진이 웹 페이지 내에 있는 모든 하이퍼링크를 타고 들어가면서 모든 내용을 읽어가는 것
웹스크랩핑(데이터 수집)
-
필요한 라이브러리
-pandasimport pandas as pd
-requestsimport requests
-BeautifulSoupfrom bs4 import BeautifulSoup as bs
-Tqdm : 여러페이지를 받아오는 경우 어디까지 진행했는지 확인하는 용도
반복되는 오래걸리는 작업을 할 때 사용하면 좋다. -
데이터 수집 과정
1) 수집하고자 하는 페이지의 URL 찾기url = "https://~"
2) 판다스로 읽어와 보기pd.read_html(url)
3) 판다스로 동작이 안될경우 requests 라이브러리를 통한 http 요청
response = requests.get(url, headers = headers)
4) BeautifulSoup으로 html 해석
soup= bs(response.text, 'html.parser')
5) soup.select 를 통해 원하는 태그(table)에 접근
temp = soup.select('table')
6) 판다스로 DataFrame을 받아온다
table = pd.read_html(str(temp))
필요한 라이브러리
1. Requests
: 파이썬에서 동작하는 작고 빠른 브라우즈
-HTTP(웹사이트)를 호출하는데 사용되는 라이브러리
-웹서버로부터 초기 html만 받을 뿐 추가 CSS/JavaSript 처리 못함
API
어떤 방식(method)의 HTTP 요청을 하느냐에 따라서 해당하는 이름의 함수를 사용한다.
GET 방식: requests.get()
POST 방식: requests.post()
PUT 방식: requests.put()
DELETE 방식: requests.delete()
2. BeautifulSoup
: html 파서로 지정 html로부터 원하는 위치/형식(태그)의 문자열 획득
데이터 수집 과정
Case 1 ) Pandas를 통한 데이터 수집
1. 수집 페이지 URL 찾기
url ='http:/ ~
2. 판다스로 읽어와 보기
pd.read_html(url)
- 판다스의 pd.read-html 기능으로 데이터가 정상 수집 된다면 requests나 다른 라이브러리 사용할 필요없이 매우 간단하게 코드 한줄로 수집할 수가 있다.
- 하지만 정상 수집이 안된다면 requests 라이브러리를 사용하여 웹페이지 가져오기
Case 2 )
1. 수집 페이지 URL 찾기
개발자 도구(or 마우스 오른쪽 -> 검사) -> NETWORK -> DOCS -> CLEAR
-> 수집할 페이지 넘기기 -> 원하는 페이지 URL 클릭 -> HEADERS 탭
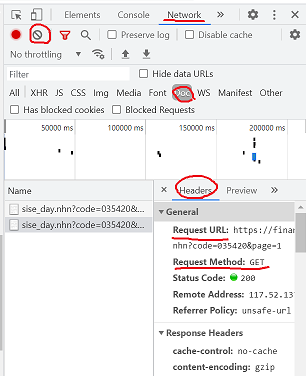
2. Requests를 통한 http 요청
import requests
url = 'http:// ~'
headers = {'user-agent': 'Mozilla/5.0 ~'}
response = requests(url, headers = headers)
response.textuser-agent 코드는 network을 통해 url 찾았던 headers 탭에서 찾을 수 있다.
user-agent
나의 블라우저가 웹사이트에 접속할 때 주는 header 정보에 따라서 사이트가 스마트폰, 데스크 탑인지 판단하고 어떤 화면을 보여 줄지 판단 한다.
사람(user-agent)이 아닌 컴퓨터 접근(웹스트랩핑 or 크롤링) 일때 웹사이트가 접속을 차단하여 원하는 정보를 가져가지 못하게 막는다.
headers 에 user-agent를 딕셔너리 형태로 넣어서 사람이 접근한것처럼 해준다.
url(웹페이지) 에 접속할때 header 정보로 'user-agent'를 넘겨준다는 뜻
3. BeautifulSoup으로 html 해석
from bs4 import BeautifulSoup as bs
soup = bs(response.text, 'html.parser')`4. soup.select으로 원하는 태그만 가져오기
temp = soup.select('table')
5. pandas로 데이터 프레임 받아오기
table = pd.read_html(str(temp))
※ 이때 temp를 str()로 묶어 주어야 정상적으로 작동함※
코드
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
url = 'http://~'
headers = {'user-agent': '~'}
response = requests(url, headers = headers)
soup = bs(respons.text, 'html.parser')
# soup = bs(respons.text, 'lxml') 도 가능
temp = soup.select('table')
table = pd.read_html(str(temp))주피터 노트북 실습
네이버 금융 페이지를 통한 네이버 일별 시세 수집하기
