
신경망
입력층, 은닉층, 출력층으로 표현할 수 있는 구조
if 가중치를 갖는 층 3개 → 3층 신경망
신경망 학습(딥러닝): 종단간 기계학습
- 사람의 개입이 필요없음, 데이터 입력에서부터 목표한 결과를 사람의 개입 없이 얻는다.
활성화 함수
활성화 함수는 입력 신호의 총합(편향, 노드, 가중치를 계산한 값)으로 출력 신호로 변환하는 함수이다. 이 총합이 활성화를 일으키는지 계산한다.
계단 함수
퍼셉트론의 활성화 함수로 쓰이며, 특정 임계값을 넘기면 활성화되는 함수
시그모이드 함수
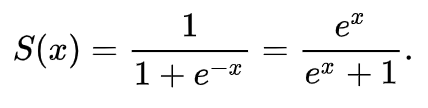
신경망의 활성화 함수로 쓰이며, 입력에 따라 출력이 연속적으로 변화
계단 함수, 시그모이드 함수 둘다 비선형이라는 공통점 존재
신경망에서 활성화 함수는 선형이 아닌 비선형 함수를 사용해야 한다.
선형 함수(y = ax + b): 층을 아무리 깊게 해도 ‘은닉층이 없는 네트워크’로도 똑같은 기능을 할 수 있다는 데에 문제점 존재
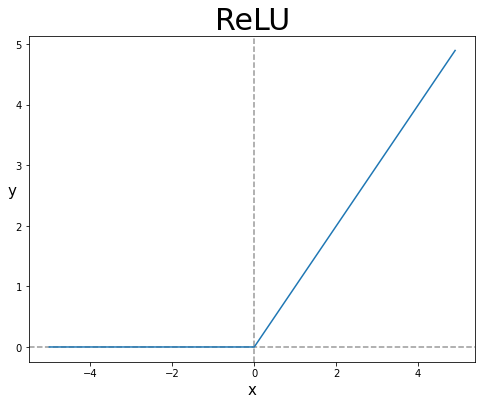
ReLU 함수
시그모이드에 비해 최근에는 ReLU 함수를 주로 이용
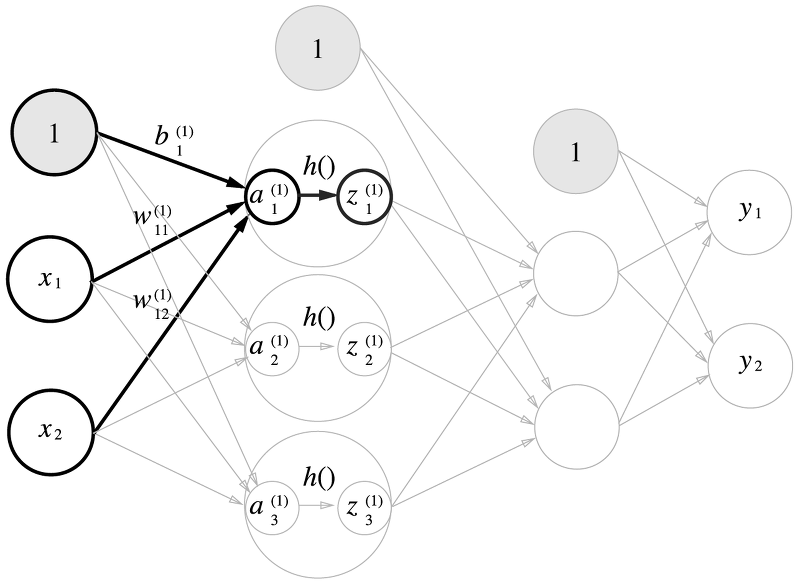
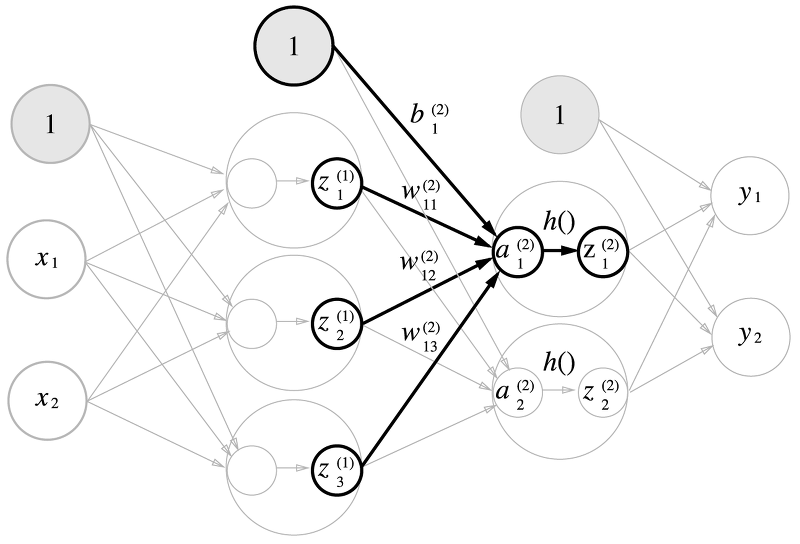
다차원 배열의 계산 & 3층 신경망 구현
행렬의 곱을 사용해서 출력층 값을 계산해주고, 활성화 함수는 시그모이드 함수를 사용한다.
(1 X 2) * (2 X 3) = (1 X 3)
(1 X 3) * (3 X 2) = (1 X 2)
출력층 설계
신경망은 출력층에서 사용하는 활성화 함수에 따라 분류 or 회귀에 쓰일지 결정된다
회귀 - 항등 함수
분류 - 소프트맥스 함수
항등 함수
입력을 그대로 출력
소프트맥스 함수
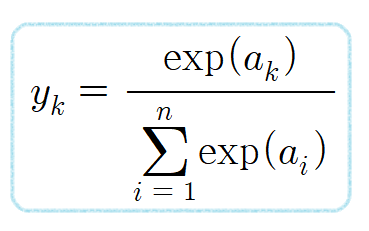
함수의 출력은 0에서 1.0 사이의 실 → 출력을 ‘확률’로 해석 가능하다
ex) y[1]의 확률은 0.245(24.5%), y[2]의 확률은 0.737(73.7%)로 해석 가능
→ 2번째 확률이 가장 높으니 답은 2번째 클래스
지수함수는 단조증가 함수이므로, 원소의 대소 관계는 변하지 않는다
→ 출력이 가장 큰 뉴런이 위치는 달라지지 않는다
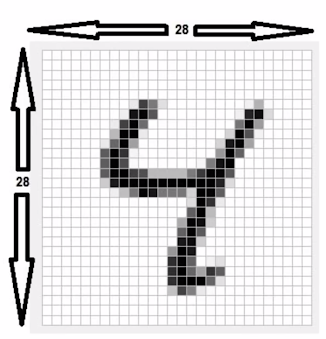
손글씨 숫자 인식(MNIST 데이터)
MNIST 데이터: 0 ~ 9까지의 손글씨 데이터
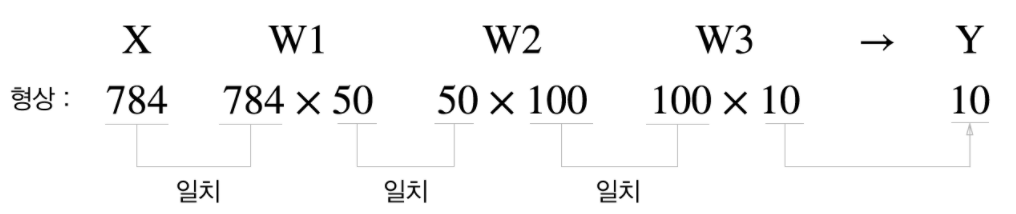
신경망 각 층의 배열 형상
입력층: 뉴런 784개(28 * 28)
출력층: 뉴런 10개(0 ~ 9 까지의 확률)
배치 처리
이미지 여러 장을 한꺼번에 입력하는 경우 배치 처리를 한다
배치: 하나로 묶은 입력 데이터

전체코드
import sys, os
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록
import numpy as np
import pickle
from dataset.mnist import load_mnist
from common.functions import sigmoid, softmax
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
def predict(network, x):
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
x, t = get_data()
network = init_network()
batch_size = 100 # 배치 크기
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1) #가장 높은 값을 가지는 인덱스 반환 -> 에측한 답
accuracy_cnt += np.sum(p == t[i:i+batch_size]) # 예측한 답과 비교 -> 정확도 체크
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))