오차역전파법
가중치 매개변수의 기울기를 효율적으로 계산하는 방법
수치 미분 방법 → 구현 쉽지만 시간이 오래 걸림
계산 그래프
계산 그래프를 통해 역전파 효율적으로 미분 가능
순전파와 역전파를 활용해서 각 변수의 미분을 효율적으로 구할 수 있다.
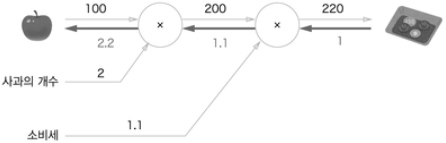
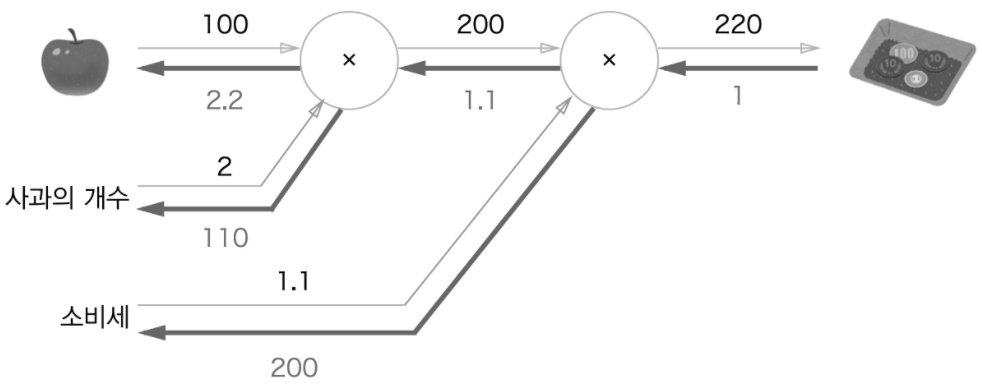
→ 사과 가격에 대한 지불 금액의 미분: 사과 값이 조금 올랐을 떄 지불 금액의 양상 파악
연쇄 법칙
합성 함수의 미분에 대한 성질: 함성 함수의 미분은 합성 함수를 구성하는 각 함수의 미분의 곱으로 나타낼 수 있다.
ex) z = t**2 / t = x + y
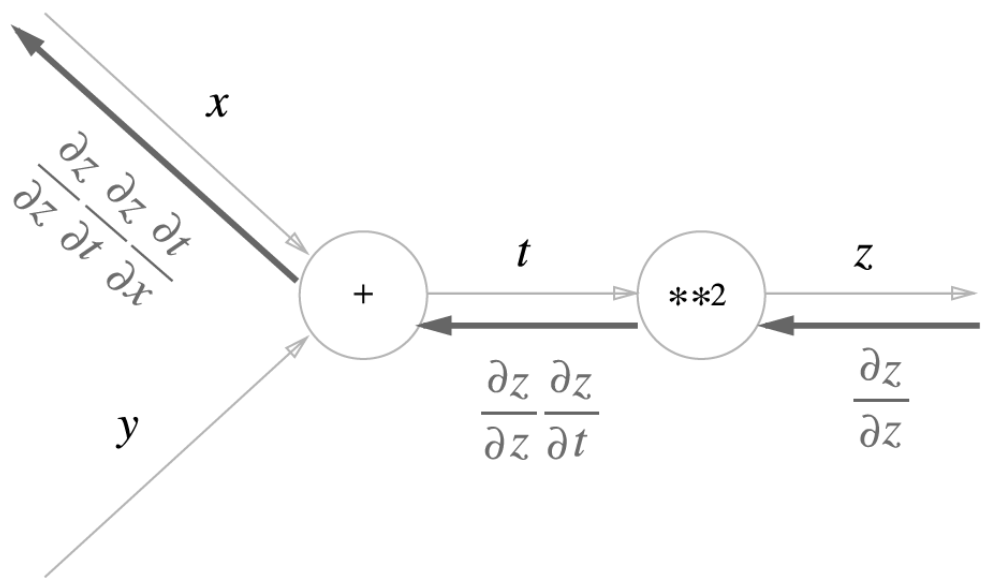
역전파
덧셈 노드의 역전파: 입력 값을 그대로 흘려보낸다
곱셈 노드의 역전파: 상류의 값에 순전파 때의 입력 신호들을 서로 바꾼 값을 곱해서 하류로 보낸다
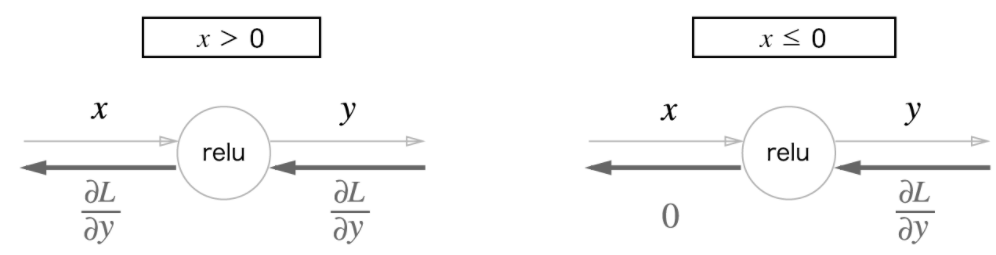
활성화 함수 계층 구현
ReLU 계층
Sigmoid 계층
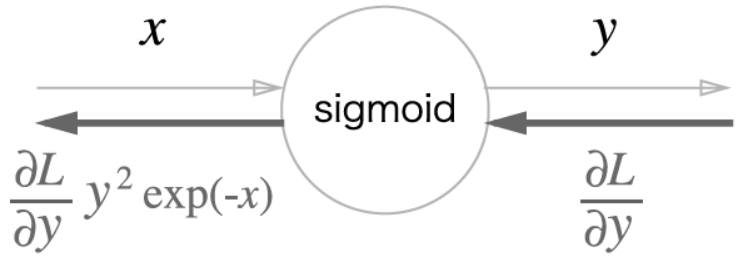
Sigmoid 계층의 역전파는 순전파의 출력만으로 계산할 수 있다
→ y exp(-x) = 1 - y
Affine 계층
신경망 순전파 때 수행하는 행렬의 곱을 기하학에서 부르는 이름
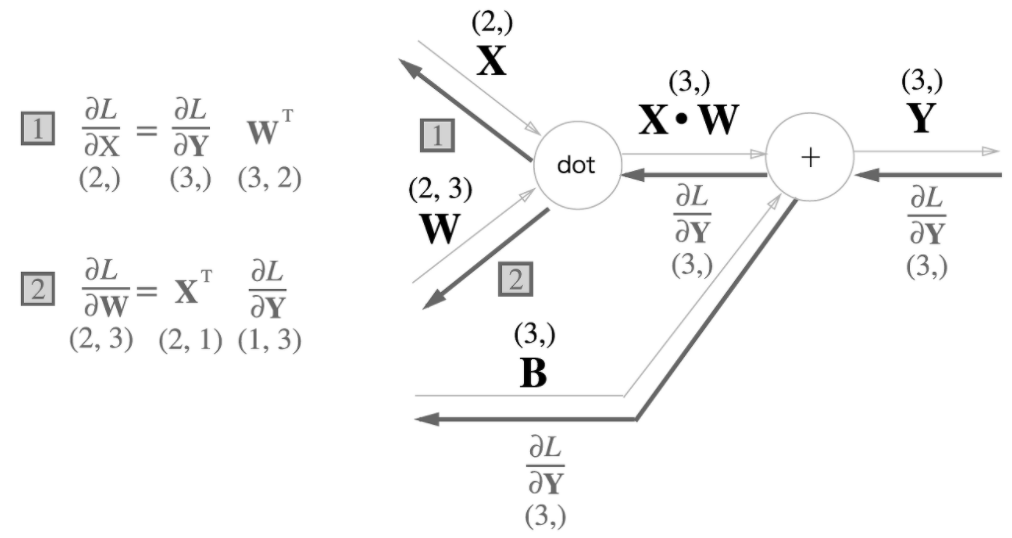
X 와 ∂L / ∂X은 같은 형상이고, W와 ∂L / ∂W도 같은 형상이다
→ 행렬 곱의 역전파는 행렬의 대응하는 차원의 원소 수가 일치하도록 곱 조립
배치용 Affine 계층: X의 형상이 (N, 2)가 된 것
Softmax 계층
출력층에서 사용하며 입력 값을 정규화하여 출력한다
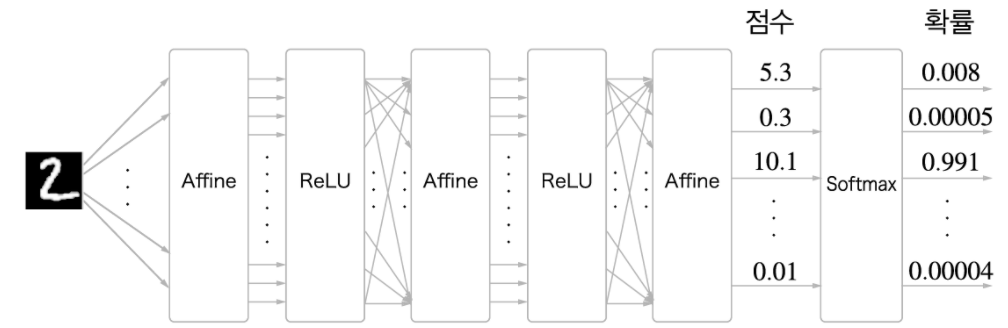
신경망 작업
- 학습: Softmax 계층 필요
- 추론: 마지막 Affine 계층의 출력(점수)을 인식 결과로 이용
Softmax-with-Loss 계층의 계산 그래프
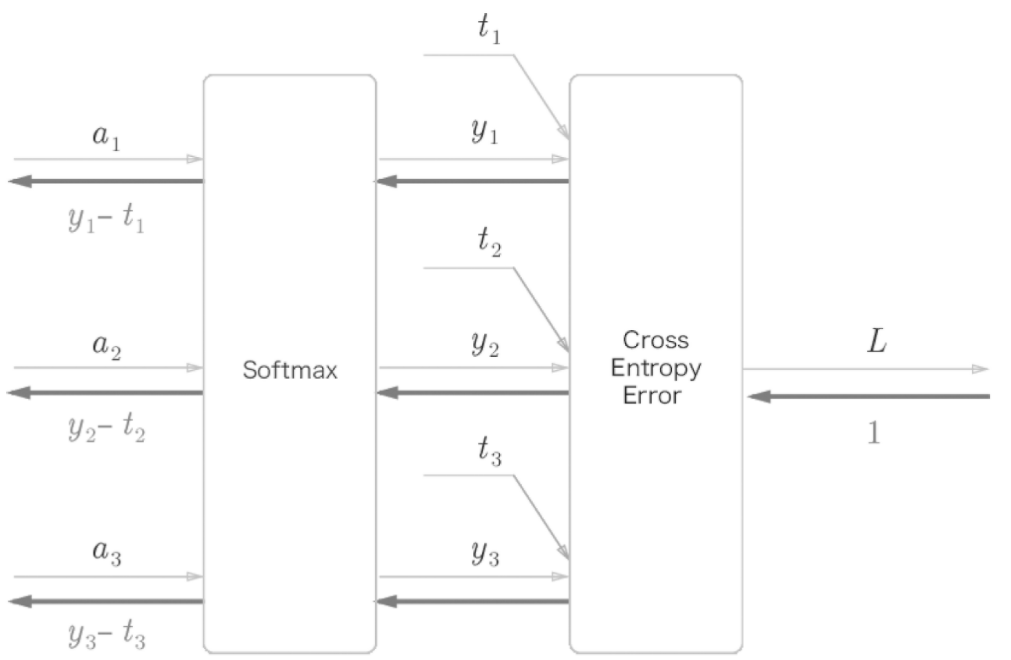
(y1 - t1, y2 - t2, y3 - t3): Softmax 계층의 출력 & 정답 레이블의 차분인 오차
→ 오차의 값에 크기에 따라 학습하는 정도가 결정된다
오차역전파법을 사용한 학습 구현
💡 **전체**신경망에는 적응 가능한 가중치와 편향이 있고, 이 가중치와 편향을 훈련 데이터에 적응하도록 조정하는 과정을 '학습'이라 합니다. 신경망 학습은 다음과 같이 4단계로 수행합니다.
1단계 - 미니배치
훈련 데이터 중 일부를 무작위로 가져옵니다. 이렇게 선별한 데이터를 미니배치라 하며, 그 미니배치의 손실 함수 값을 줄이는 것이 목표입니다.
2단계 - 기울기 산출
미니배치의 손실 함수 값을 줄이기 위해 각 가중치 매개변수의 기울기를 구합니다. 기울기는 손실 함수의 값을 가장 작게하는 방향을 제시합니다.
3단계 - 매개변수 갱신
가중치 매개변수를 기울기 방향으로 아주 조금 갱신합니다.
4단계 - 반복
1~3단계를 반복합니다.
# 데이터 읽기
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 2층 신경망 생성
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
# 하이퍼 파라미터
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 에포치 선정
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size) # 미니배치
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 기울기 산출
#grad = network.numerical_gradient(x_batch, t_batch) # 수치 미분 방식
grad = network.gradient(x_batch, t_batch) # 오차역전파법 방식(훨씬 빠르다)
# 매개변수 갱신
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key] # 오차역전파법으로 구한 기울기를 빼준다.
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print(train_acc, test_acc)오차역전파법으로 구한 기울기 검증
수치 미분: 구현하기 쉽다 but 느리다
오차역전파법: 구현하기 어렵다 but 빠르다
→ 오차역전파법의 결과와 수치 미분의 결과를 비교하여 제대로 구현했는지 검증한다(기울기 확인)
# network = TwoLayerNet()
grad_numerical = network.numerical_gradient(x_batch, t_batch) # 수치 미분 기울기
grad_backprop = network.gradient(x_batch, t_batch) # 오차역전파법 기울기
# 각 가중치의 절대 오차의 평균을 구한다.
for key in grad_numerical.keys():
diff = np.average( np.abs(grad_backprop[key] - grad_numerical[key]) )
print(key + ":" + str(diff))