References
참조 타입과 값 타입
참조 타입과 값 타입에 대한 논쟁은 곧 힙과 스택에 대한 논쟁으로 이어진다. 스택이 힙보다 훨씬 빠르다는 것은 모두가 인정하나 현대 컴퓨터의 수준에서는 미미하다거나 그런 거 신경쓸 바에 빠르게 개발해서 생산성을 높이자는 반론들도 많지는 않지만 있는 듯 하다. 그렇지만 이는 프로그래머로서 한번쯤은 해 봤을만한 고민이고 면접이 되었든 학부 시험이 되었든 한 번쯤은 마주치게 되는 단골 질문이다. Swift는 이를 어떻게 관리하고 있을까? 한 번 자세히 알아보자.
Stack
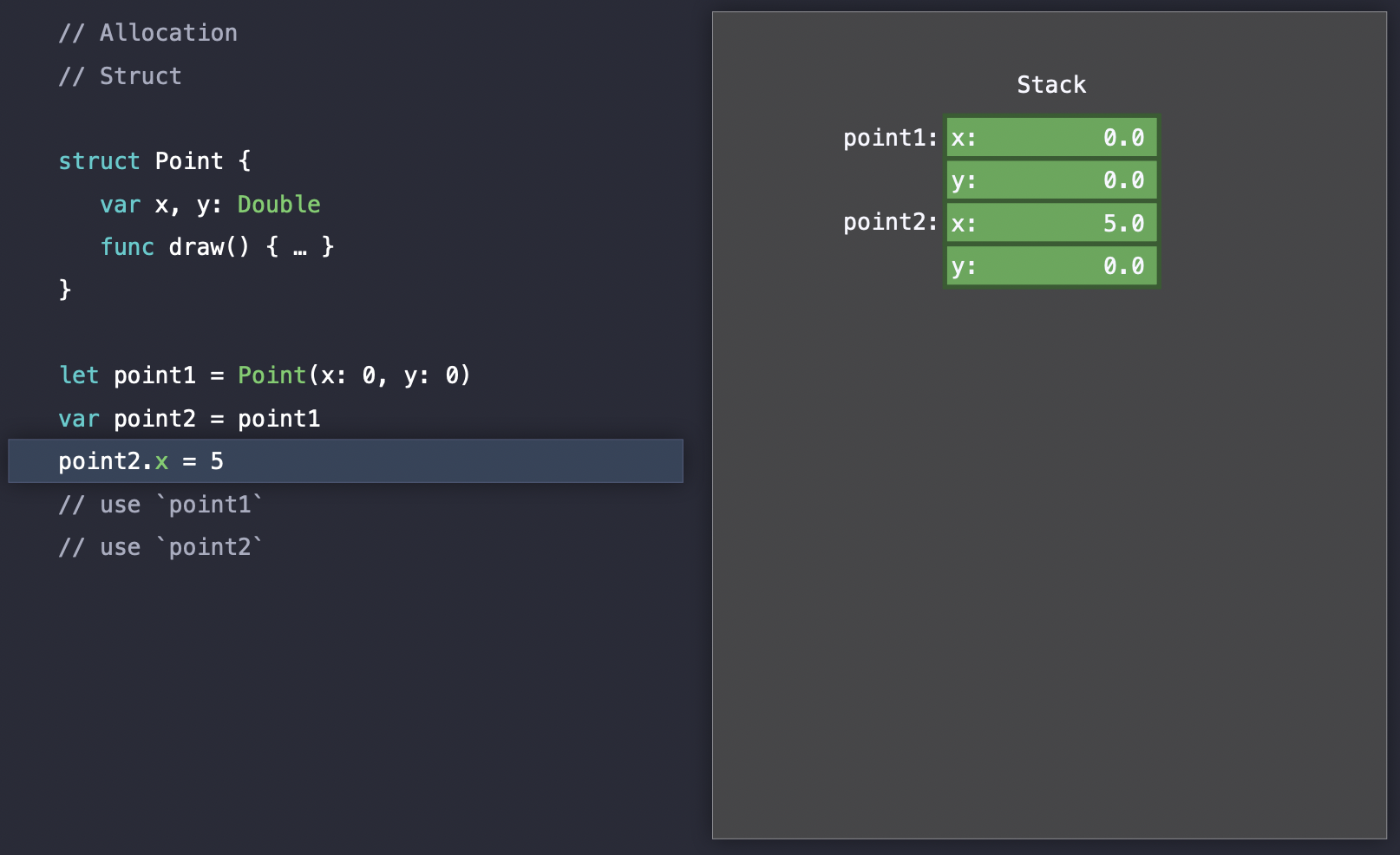
Swift의 Stack은 struct로 대변된다. 영어로 value semantic이라는 용어를 쓰는데 대충 값 타입 비스무리한 거라고 이해를 해 두자. 조금 자세히 설명해본다면 변수를 복사할 때 그 주소가 아닌 값이 그대로 복사가 되고 다른 곳이 아닌 stack에 복사된다는 것이다.
Stack의 장점
Stack은 스택포인터와 push와 pop으로만 이루어진 간단한 작업으로 할당, 해제된다. Heap에 무언가를 저장하기 위해서는 RAM의 빈 공간을 찾는 작업이 필요하다. 10개의 프로퍼티를 가진 class는 (대개) 연속된 10칸의 words 공간을 OS에게 부탁하고 OS는 시발시발 거리며 RAM의 (거의) 전역을 탐색한다. 하지만 Stack은 그냥 위에 던져 넣으면 된다. 속도 면에서 이득을 볼 수 밖에 없다.
또한 stack은 쓰레드 별로 1개씩 할당된다. 고전적인 CS 문제인 프로세스와 쓰레드의 차이는 무엇일까요? 에 대한 답변을 여기서 정리해보자면 프로세스는 프로그램의 단위고 쓰레드는 작업의 단위다. Heap은 프로그램 곳곳에 쓰이는 참조 타입을 관리하므로 공통된 하나의 것일 필요가 있지만 쓰레드에서 이루어지는 작업은 지역적이므로 스택은 각자 관리한다. 이말인 즉슨 스택의 경우 data race를 걱정할 필요가 없다는 것이다. 퍼포먼스에 이점을 갖는 이유가 하나 더 생겼다.
Stack의 단점
다만 Stack은 compile 타임에 그 크기가 결정되므로 다소 유연하지 못하다. 또한 갑자기 큰 크기의 자료가 들어오면 이를 견디지 못하고 stack overflow가 발생해 프로그램이 터져버린다.
Heap
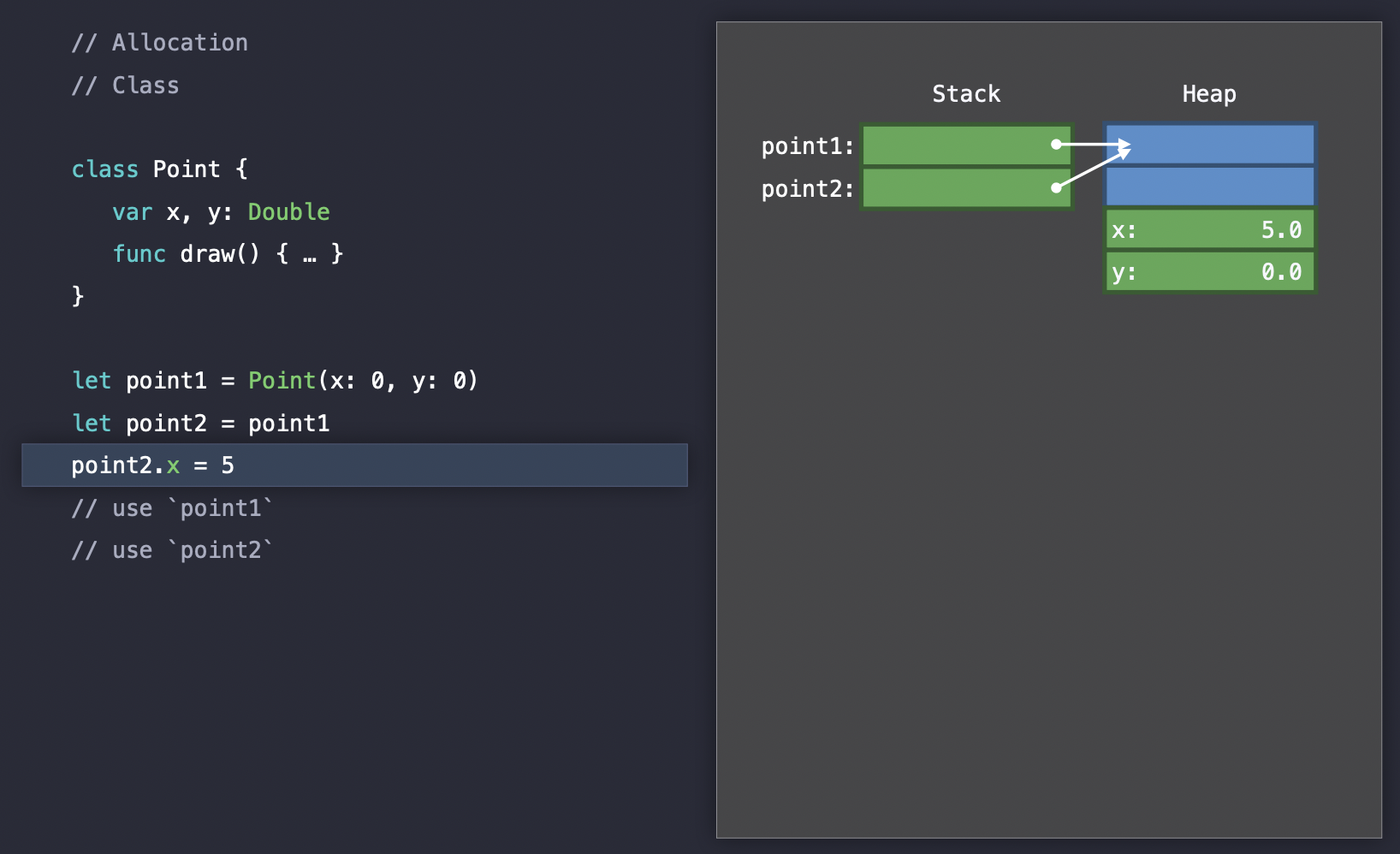
Swift에서는 class가 힙에 저장된다. 그림을 보면 알겠지만 클래스 인스턴스는 주소(포인터)로 접근할 수 있다. 뒤에서도 나오겠지만 힙에 올라간 Point가 2칸이 아니라 4칸인 이유는 type과 referenceCount를 위한 2개의 워드 공간을 필요로 하기 때문이다. 이 둘에 대해서는 뒤에 더 자세히 설명할 것이다.
Heap의 장점
스택의 장점만 본다면 그냥 스택만 한 10gb씩 넣어버리면 슈퍼컴퓨터가 될 것만 같다. 하지만 역시 그러지 못하는 이유가 있다. 애초에 스택이라는 자료구조가 능사는 아니기 때문이다.
앞서 스택의 단점이 유연하지 못함이라고 했다. 이는 스택의 크기가 컴파일 타임에 미리 정해지기 때문이다. 반면 힙의 할당은 런타임에 일어나며 크기가 매우 유동적이라 늘어났다 줄어났다 할 수 있다.
또한 전역적으로 사용되는 변수, 반복적으로 사용되는 변수의 경우 힙을 이용하는 편이 이득이다. 이를테면 크기가 10mb인 이미지를 앱 전반에서 반복적으로 사용한다고 해보자. 이미지가 필요할 때마다 디스크에서 이를 불러와 스택에 넣고 빼고 하는 것은 퍼포먼스에 악영향을 끼칠 것이며 심한 경우 프로그램이 터질 수도 있다. 반면 힙에 이미지를 미리 넣어놓고 필요할 때마다 간단히 참조(주소)만을 제공한다면 훨씬 안정적인 서비스가 가능할 것이다.
Heap의 단점
꽤 많다. 앞에서도 말했지만 일단 속도가 느리다. Heap은 RAM 안에 되는대로 처박아 놓은 우리네 옷장같은 자료구조다. Heap에 무언가를 쓰려면 여유 공간을 찾는 작업이 선행되어야 한다. 읽기의 경우 주소를 갖고 있기 때문에 조금 빠를 수는 있으나 결국 주소를 찾아가 자료를 가져오는 작업이 추가적으로 필요하다.
다음으로는 thread safety를 보장해야 한다. Heap은 의도 자체가 프로그램 곳곳에서 공유할 수 있는 자료를 저장하는 데에 있었다. 이 말인 즉슨 여러개의 작업, 즉 쓰레드가 같은 자료에 접근하려고 할 때 이를 적절히 컨트롤 할 필요가 있다는 뜻이다. 방금 출근 전에 보고 온 주식 가격이 회사에 도착해서도 같을 리가 만무하다. 내가 안 본 사이에 누군가가 바꿔놓았기 때문이다. 힙에 올라가는 자료들은 항상 이런 위험을 갖고 그러므로 atomic하게 자료를 접근, 수정할 필요가 있다.
또한 Swift의 경우 ARC를 위해 추가적인 atomic 리소스가 필요하다. ARC는 Swift가 메모리를 관리하는 방식이다. 누군가가 해당 주소를 참조하면 ARC가 1씩 올라간다. 하지만 이 ARC 역시 참조하려는 자료 꼭대기에 붙어 heap에 올라와 있는 상태이므로 atomic한 접근을 필요로 한다. 이는 Swift의 참조형 자료구조의 특성상 공간을 좀 더 먹게 된다는(한 인스턴스 당 2 words) 찐빠가 생길 수 있다.
Copy on write
무차별적인 값 복사를 방지하기 위해 Swift는 copy on write라는 구조를 채택한다. 값 타입이 여러번 복사될 때 값 자체를 복사하지 않고 주소를 복사하는 방식인데 이는 힙에 간접적으로 버퍼를 갖고 있는 Collection 타입과 같은 몇가지 자료형에만 국한된다. (참고)
