

본 포스팅에서는 Kafka Consumer 을 운영해오면서 겪었던 다양한 배포 문제점들과 이로 인해 발생한 이슈들을 중심으로 논의해보고자 합니다. 기존 배포방식에 대한 문제들을 해결하기 위해 우리는 기존의 Recreate, Rolling 배포 방식의 한계점을 분석하고, 더 나은 배포 전략으로서 Blue Green 을 어떻게 하면 적용할 수 있을 지에 대한 저의 생각과 해결방법을 공유하고자 합니다.
들어가기에 앞서
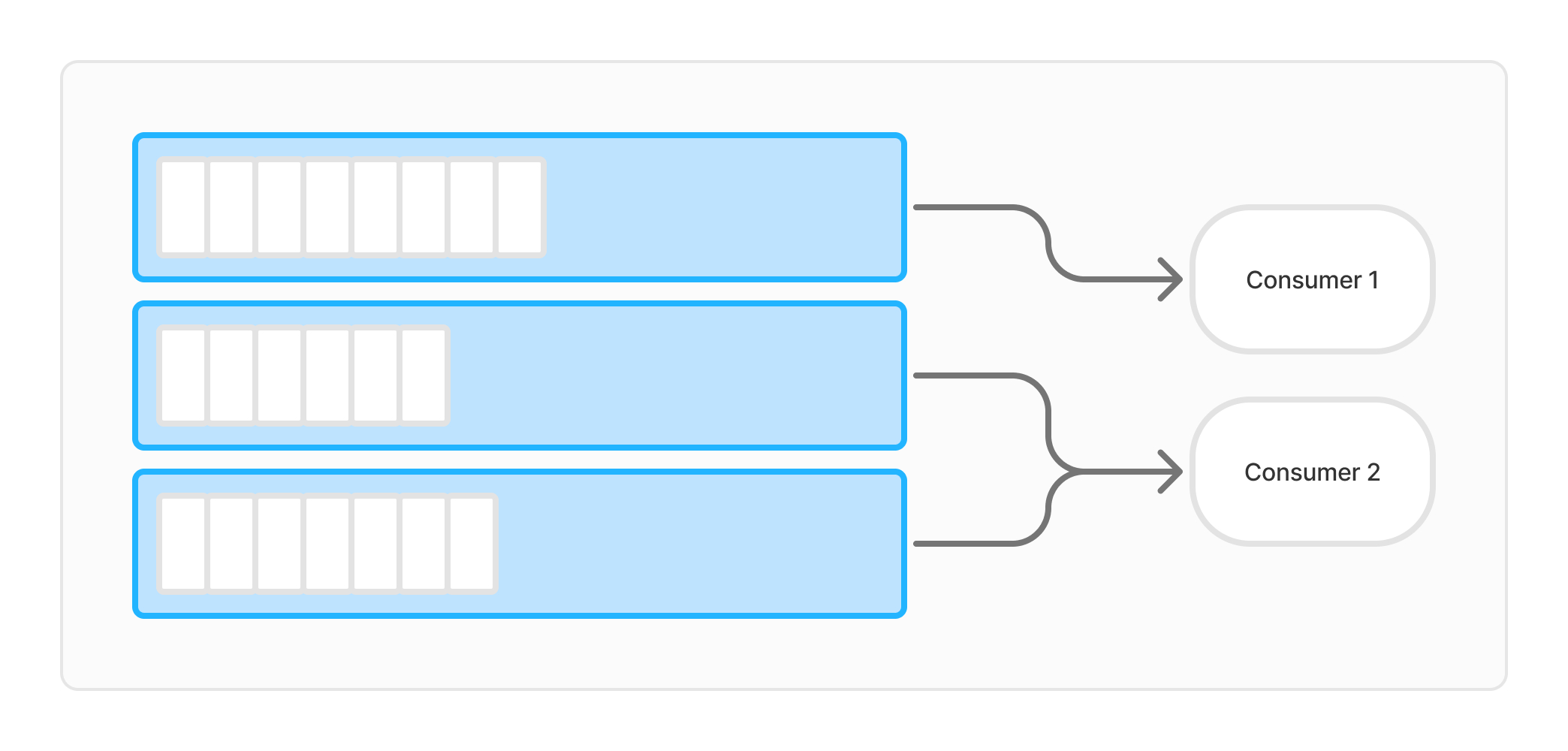
1. Kafka Consumer 개요
Kafka는 대용량의 실시간 로그 및 이벤트 데이터를 처리하는 데 널리 사용되는 분산 스트리밍 플랫폼입니다. Kafka Consumer는 이러한 데이터 스트림을 읽어 처리하는 역할을 합니다. 다양한 애플리케이션에서 Kafka Consumer를 사용하여 Producer-Consumer 모델을 구현할 수 있습니다.
2. Kafka Consumer 배포 방법의 중요성
Kafka Consumer와 같은 컴포넌트를 배포할 때는 서비스의 안정성과 가용성을 유지하는 것이 매우 중요합니다. 배포 과정에서 서비스 중단이나 데이터 손실이 발생할 경우, 비즈니스에 큰 영향을 미칠 수 있습니다. 따라서, 안정적이고 효율적인 배포 방식을 선택하는 것은 매우 중요합니다.
일반적으로 애플리케이션을 배포할 때는 Recreate, Rolling 등의 배포 방식을 사용합니다. 이 방법들도 충분히 Kafka Consumer 를 배포하기에 좋은 방법들입니다. 그러나 이러한 방식들은 몇 가지 단점과 이슈를 가지고 있어, 실제 운영환경에서 부담없이 배포하기에는 부담스러운 것이 사실입니다. 먼저 각 배포 방식과 각 문제점에 대해서 살펴보도록 하겠습니다.
일반적인 배포 방식 각 배포방식의 문제점
Recreate 방식
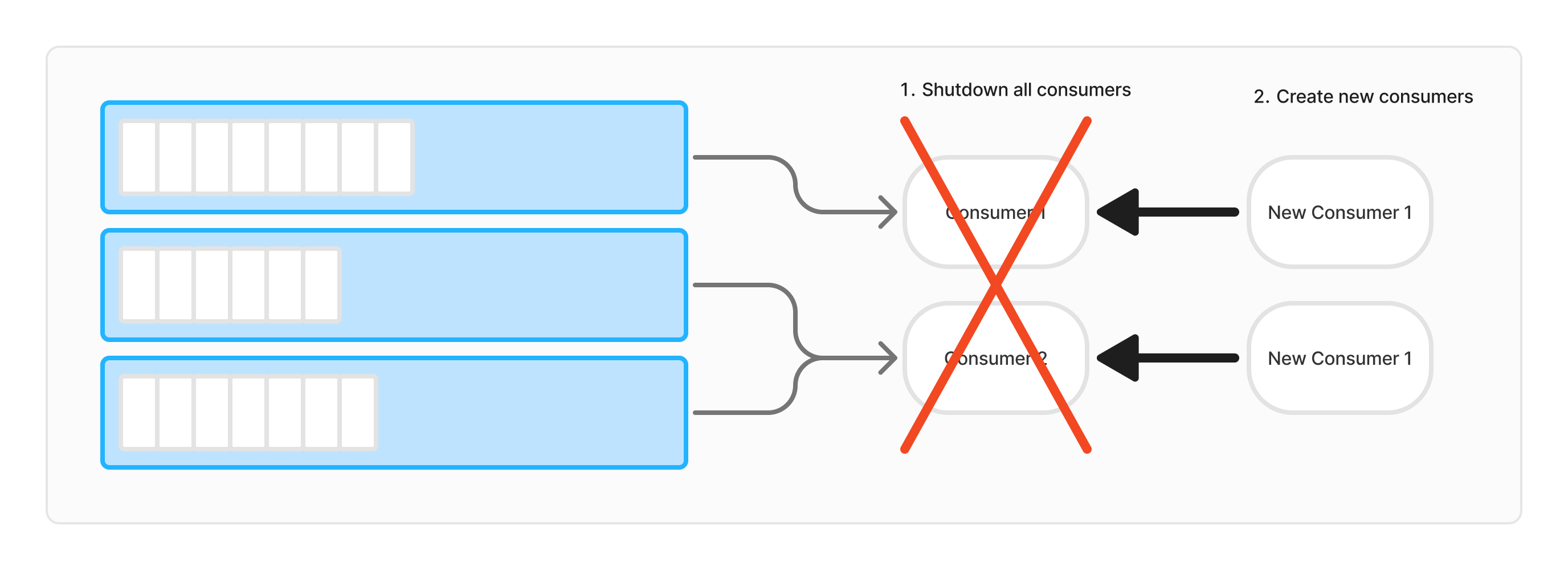
Recreate 배포 방식은 기존 애플리케이션 인스턴스를 모두 종료한 후, 새로운 인스턴스를 생성하는 방식입니다.
문제점
- 서비스 중단 시간
Recreate 배포 방식에서는 모든 인스턴스를 종료하고 새로운 인스턴스를 생성하기 때문에, 그 과정에서 서비스 중단 시간이 발생합니다. 배포에 이슈가 있어 배포내용을 롤백하는 경우에도 중단이 발생하게 됩니다. 이는 사용자 경험에 부정적인 영향을 미칠 수 있습니다. - 데이터 손실 또는 중복 위험
Recreate 방식으로 배포할 경우 어플리케이션을 종료하게 되므로 처리 진행중인 데이터가 있다면 해당 작업 도중 중단이 일어나게 됩니다. 따라서 메시지 손실이 일어날 수 있으며 또는 새로 배포된 어플리케이션이 데이터를 재처리하면서 데이터 중복처리가 발생할 수 있습니다. - 배포 시 다수의 Rebalancing 발생
Consumer 를 다수의 어플리케이션으로 구성했을 경우 어플리케이션이 새로 올라가면서 리밸런싱이 수행됩니다. 리밸런싱이 수행될 시점에 메시지가 처리되고 있었다면 이 또한 데이터 손실 및 중복 처리 등의 이슈를 발생시킬 수 있습니다.
Rolling 방식
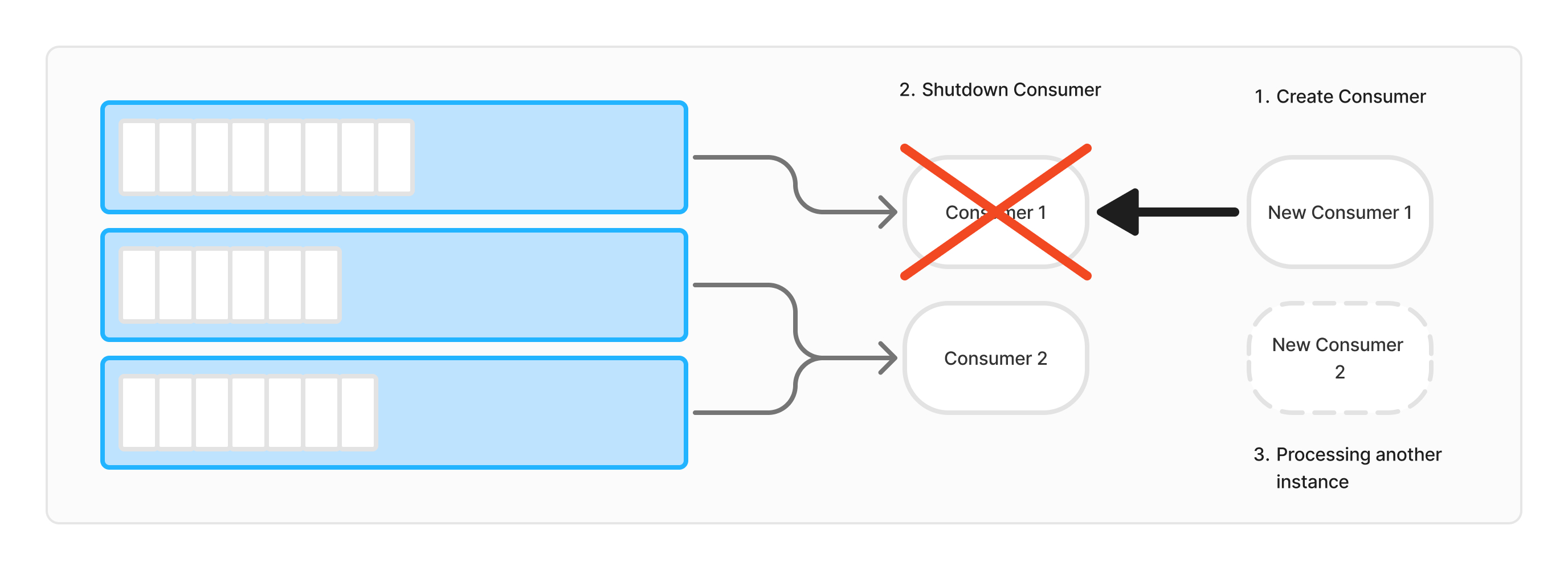
Rolling 배포 방식은 기존 인스턴스를 하나씩 교체하면서 새로운 인스턴스를 배포하는 방식입니다. 해당 방식은 Recreate 방식에 비해 중단포인트가 최소화된다는 장점이 있지만 다음과 같은 문제점이 있습니다.
문제점
- 긴 배포/롤백 시간
Rolling 배포의 경우 각 인스턴스를 순차적으로 업데이트하기 때문에 전체 배포 시간이 길어질 수 있습니다. 문제가 발생했을 때 롤백하는 과정 역시 많은 시간이 소요되며, 이로 인해 서비스의 가용성에 부정적인 영향을 미칠 수 있습니다. - 데이터 손실 또는 중복 위험
Rolling 방식 또한 Recreate 방식과 동일하게 어플리케이션이 종료되므로 데이터 손실 또는 중복의 위험이 있습니다. - 배포 시 다수의 Rebalancing 발생
이 또한 Recreate 방식과 동일하게 데이터 처리 도중 Consumer 가 참여 또는 이탈하면서 Rebalancing 이 다수 발생하게 됩니다.
이상적인 Kafka Consumer 배포 방법의 요건
저는 위에서 명시된 이슈들이 시스템 가용성과 안정성에 적지 않은 영향을 줄 수 있음을 경험을 통해 알게 되었습니다. 데이터의 일관성이 무너지는 문제는 대부분 배포시점에 발생합니다. 그렇다면 이상적인 배포는 어떤 요건들을 갖추어야 할까요?
- 배포 시 Downtime이 존재하지 않을 것: 배포 과정에서 서비스 중단이 발생하지 않도록, 무중단 배포 방식을 구현해야 합니다.
- 배포 시 데이터 처리 중 Rebalancing이 발생하지 않을 것: 데이터 처리중에는 Kafka consumer의 Rebalancing 이 발생하지 않도록 하여, 데이터 처리의 안정성을 유지해야 합니다.
- 배포와 롤백이 즉시 반영될 것: 배포 및 롤백 작업이 빠르게 적용되어야 하며, 문제가 발생할 경우 즉시 원래 형상으로 롤백할 수 있어야 합니다.
- 배포 시 데이터 손실/중복 등의 이슈가 발생하지 않을 것: 배포 과정에서 데이터 손실이나 중복 문제가 발생하지 않도록, 데이터 무결성을 보장할 수 있는 메커니즘을 구현해야 합니다.
블루-그린 배포 방식
블루-그린 배포 개요
Blue Green 배포 방식은 두 개의 환경(Blue와 Green)을 운영하여, 배포 과정에서의 위험을 최소화하는 방식입니다. 현재 운영 중인 환경(Blue)을 유지하면서, 새로운 버전의 애플리케이션을 다른 환경(Green)에 배포하고, 검증 후 트래픽을 전환하는 방식입니다. 해당 방식은 배포 시 Downtime 이 발생하지 않으며, 배포와 롤백의 전환이 자유롭고, Blue 와 Green 배포 환경이 격리되어 서로 영향을 주지 않습니다.
그럼 Kafka 에서 블루-그린 배포를 어떻게 적용할 수 있을까요?
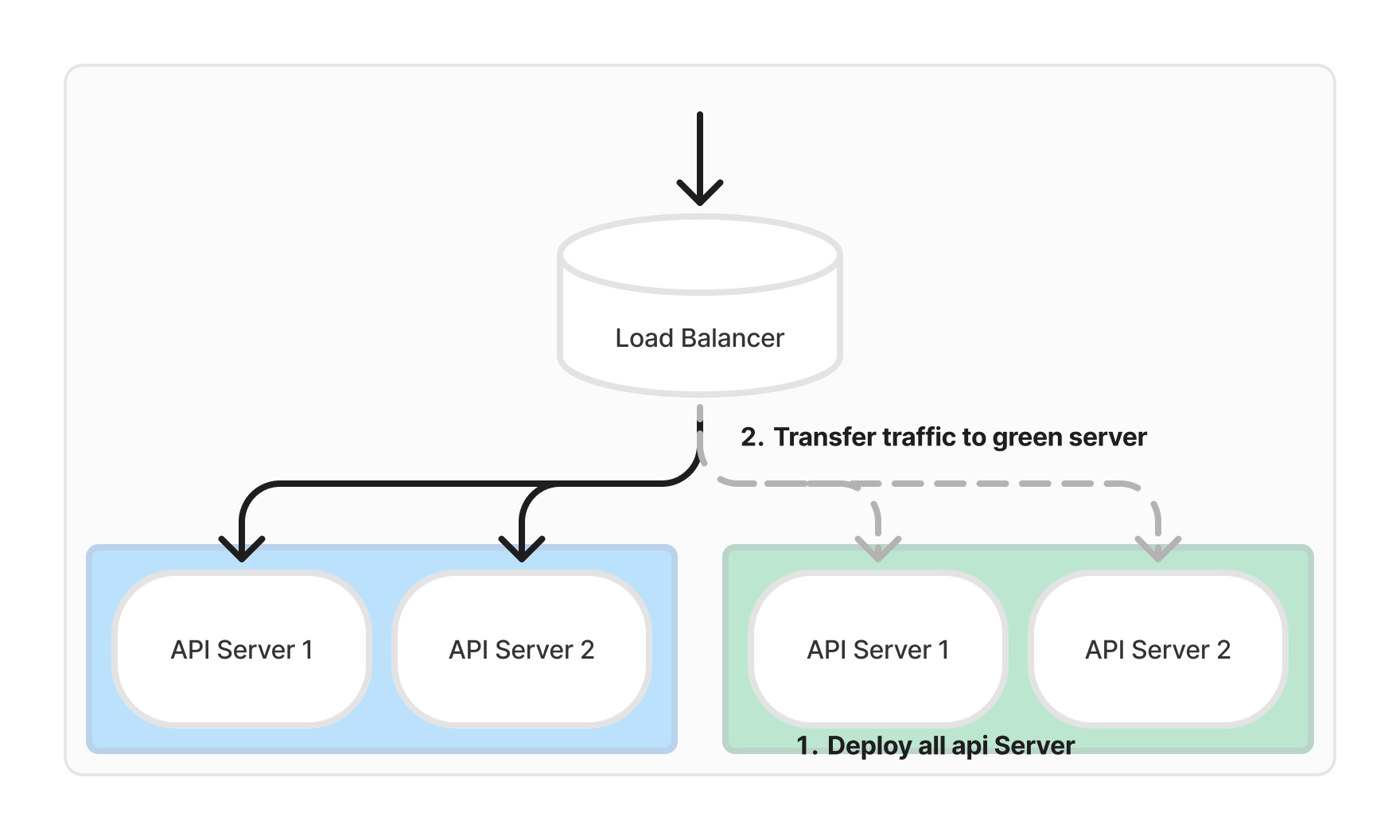
일반적으로 API 서버에서는 위 그림과 같이 두개의 환경을 구성하고 인입되는 트래픽을 Load Balancer 를 통해 Blue-Green 전환하는 방식으로 구현이 되어있습니다. 이런 구조를 Kafka Consumer 에서도 적용하여 Blue-Green 배포 환경을 구성할 수 있을 것입니다.
다음포스팅에서는 Blue Green 배포를 어떻게 구현할 지에 대하여 포스팅 하겠습니다.
