
Goal
- JPQL 소개
- JPQL의 기본 문법에 대해 파악한다.
- parameter binding 방법에 대해 파악한다.
- 프로젝션에 대해 파악한다.
- 페이징 기법에 대해 파악한다.
- FETCH JOIN에 대해 파악한다.
- 벌크 연산에 대해 파악한다.
JPQL 소개
지금까지 우리는
em.find()member.getName()등의 방법으로 조회했다.
만약 '나이가 18세 이상이고, 여성이며, 주소지가 경기도인 회원'을 모두 검색하고 싶다면 어떻게 해야할까?
물론 Java 진영에서 반복문과 조건문을 통해서 어떻게든 조회할 수 있겠지만,
간단한 query를 통해 손쉽게 가져올 수 있다면 좋지 않을까?
그러나 JPA는 엔티티 객체를 중심으로 개발하기 때문에, 모든 DB 데이터를 객체로 변환하여 검색하기는 힘들다.
이를 해결하기 위해, JPA는 SQL을 추상화한 JPQL을 제공하여 테이블이 아닌 엔티티 객체를 대상으로 검색할 수 있게 한다.
문법도 SQL과 매우 흡사하여 손쉽게 Java 진영에서 DB를 다룰 수 있게된다.
하나씩 알아보도록 하자.
JPQL 기본 문법
JPQL은 결국 SQL로 변환되며, 기본적인 문법의 특징은 아래와 같다.
- 엔티티 및 속성은 대소문자를 구분한다. ex) Member, age
- JPQL 키워드는 대소문자를 구분하지 않는다. ex) select, from, where
- 테이블이 아닌 엔티티를 대상으로 query한다.
- 별칭은 필수이며, as는 생략 가능하다.
- 대상 엔티티를 아래와같이 명시하여 query를 수행한다.
- 결과 조회 API는 아래와 같다.
query.getResultList(): 결과가 하나 이상일 때 리스트를 반환한며, 결과가 없다면 빈 리스트를 반환한다.query.getSingleResult(): 결과가 정확히 하나일 때 단일 객체를 반환한다. 결과가 없거나 둘 이상이면 오류를 발생시킨다.


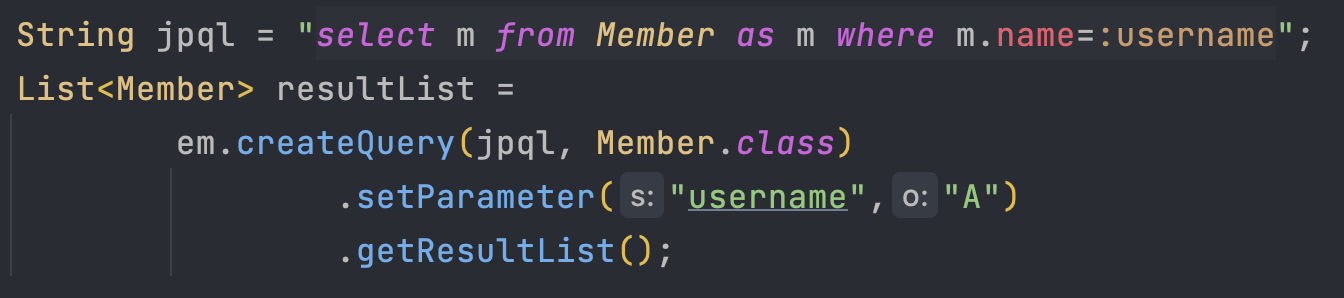
JPQL 파라미터 바인딩
- JPQL은 parameter 기능을 제공하며, 사용 방법은 아래와 같다.
JPQL 프로젝션
- 프로젝션 : SELECT 절에 조회할 대상을 지정하는 것
- 대상 : 엔티티, 임베디드 타입, 기본 데이터 타입

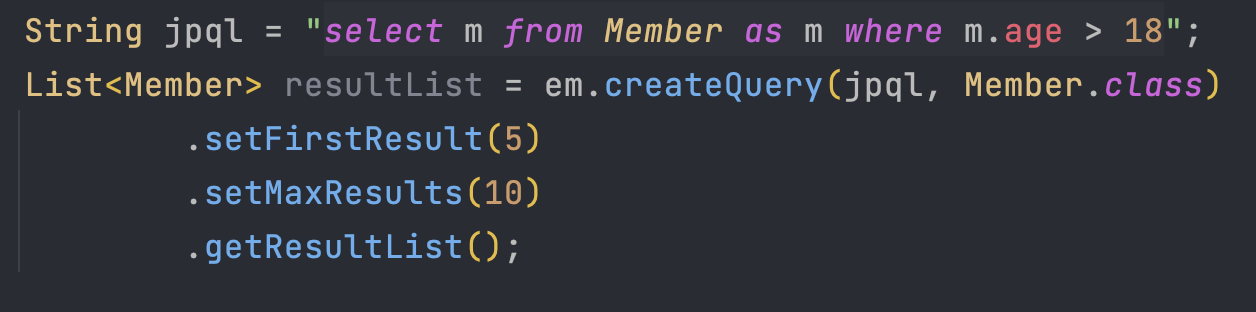
JPQL 페이징
- 페이징은 아래 두 API로 해결된다.
setFirstResult(int startPos): 조회 시작 위치(0부터 시작)setMaxResults(int maxResult): 조회할 데이터 수
JPQL fetch join
- JPA는 JPQL을 통해 조회하는 엔티티와 연관된 엔티티나 컬렉션을 한 번의 SQL로 같이 조회하여 성능을 최적화하기 위해 FETCH JOIN을 제공한다.
- 회원을 조회하며 연관된 팀도 조회하고자 할 때, 다음 쿼리를 수행한다.
- 그렇다면 일반 조인과 어떤 차이를 가질까?
- 일반 JOIN : 연관 엔티티를 프록시, 즉 지연 로딩으로 가져온다.
- FETCH JOIN : 연관 엔티티를 연관관계 매핑에 관계없이 즉시 로딩으로 가져온다. 따라서, N+1 문제에 유의하여 사용해야한다.

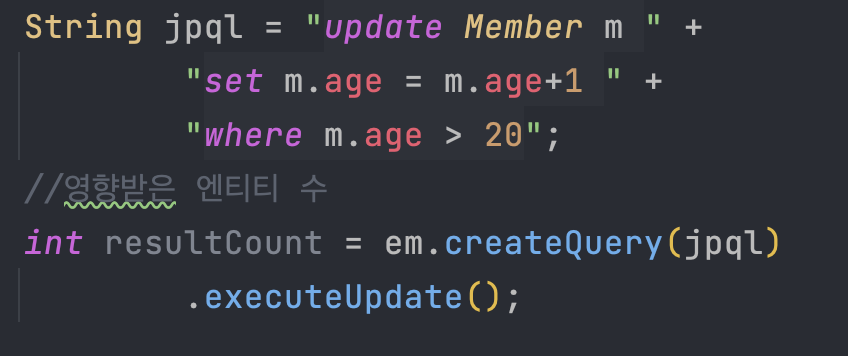
JPQL 벌크 연산
- 벌크 연산 : 대량의 데이터를 한 번에 처리하는 작업
- UPDATE, INSERT, DELETE 등
주의점
- 벌크 연산은 영속성 컨텍스트를 무시하고 DB에 바로 query한다.
따라서, 벌크 연산 수행 후 영속성 컨텍스트를 반드시 초기화해야한다.
참고 자료
💕오류 지적 및 피드백은 언제든 환영입니다. 복제시 출처 남겨주세요!💕
💕좋아요와 댓글은 큰 힘이 됩니다.💕
💕좋아요와 댓글은 큰 힘이 됩니다.💕

I AM WHO I AM