
📍목차
- 가상 메모리의 개요
- 페이징 기법
- 세그먼테이션 기법
- 캐시 매핑 기법
1️⃣ 가상 메모리의 개요
현대 운영체제에서 메모리 관리의 특징은 프로세스가 올라갈 메모리의 위치를 신경 쓰지 않고 프로그래밍할 수 있다는 것이다.
이것을 가능하게 하는 기술을 가상 메모리라고 부른다.
즉, 가상 메모리 덕분에 프로세스는 운영체제의 위치와 물리 메모리의 크기를 신경 쓰지 않고 마음대로 메모리를 사용할 수 있다.
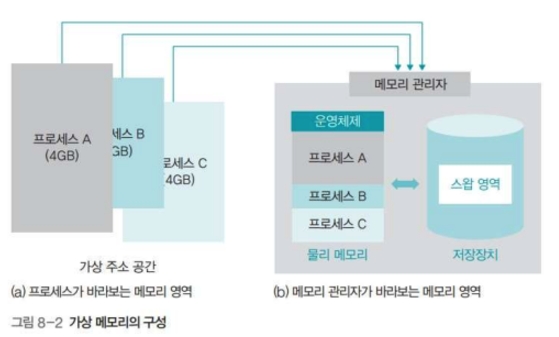
가상 메모리가 물리 메모리의 크기를 넘어서 메모리를 사용하게 할 수 있는 것은 스왑 때문이다.
가상 메모리의 구성 요소인 스왑은 하드디스크에 존재하며, 메모리 관리자가 관리한다.
메모리 관리자는 물리 메모리의 부족한 부분은 스왑 영역으로 보충한다.
스왑인을 통해 프로세스를 메모리로 가져오고, 스왑아웃을 통해 메모리가 부족할 때 프로세스를 스왑 영역으로 보낸다.
가상 주소
프로세스는 가상 주소를 사용하는데, 이는 물리 메모리와 스왑 영역을 합쳐서 사용하는 주소로서 프로세스 관점에서의 주소이다.
가상 메모리 시스템에서 메모리 관리자는 가상 주소를 실제 메모리의 물리 주소로 변환한다.
또한 메모리 관리자는 물리 메모리를 어떻게 나눌지, 프로세스를 어디에 배치할지, 부족한 물리 메모리를 어떻게 처리할지 등 복잡한 문제를 처리한다.
✔️ 매핑 테이블
가상 메모리 시스템에서 가상 주소는 물리 메모리 주소나 스왑 영역 중 한 곳에 위치한다.
메모리 관리자는 가상 주소와 물리 주소를 일대일로 매핑한 매핑 테이블로 메모리를 관리한다.
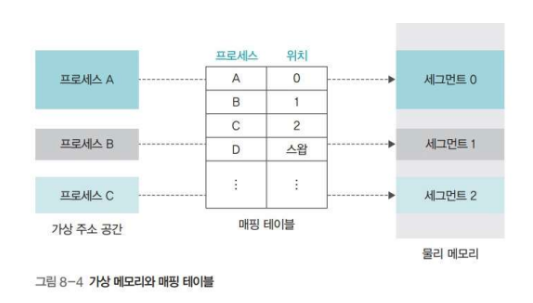
이전 포스팅에서 메모리 분할 방식은 가변 분할 방식과 고정 분할 방식으로 나뉜다고 언급했다.
매핑 테이블은 두 방식에서 모두 적용되며 고정 분할 방식에서의 매핑 테이블을 페이지 매핑 테이블, 가변 분할 방식에서의 매핑 테이블을 세그먼테이션 매핑 테이블이라고 한다.
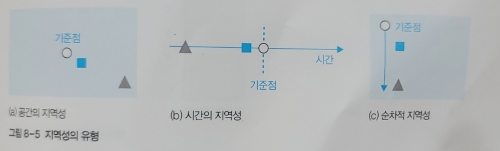
✔️ 지역성
지역성이란, 기억장치에 접근하는 패턴이 특정 영역에 집중되는 성질을 말한다.
지역성은 크게 세 가지로 나뉜다.
- 공간의 지역성 : 현재 위치에서 가까운 데이터에 접근할 확률이 높다.
- 시간의 지역성 : 현재를 기준으로 가장 최근에 접근한 데이터가 더 먼 시간에 접근한 데이터보다 사용될 확률이 높다.
- 순차적 지역성 : 일반적으로 작업은 앞에서부터 순서대로 진행될 확률이 높다.
캐시는 지역성 이론을 사용하는 대표적인 장치다.
공간적으로나 시간적으로 가까이 있는 데이터를 가져옴으로써 캐시 적중률을 높일 수 있다.
현재 1행을 실행 중이라면, 캐시에 10행을 가져오는 것이 100행을 가져오는 것보다 유리할 것이라 판단하기 때문이다.
프로그래밍할 때 goto문을 사용하지 말라고 하는 것도 이와 같은 이유에서이다.
다음 포스팅에서 설명할 페이지 교체 알고리즘도 지역성 이론을 기반으로 앞으로 사용할 가능성이 적은 페이지를 찾아 스왑아웃을 진행한다.
2️⃣ 페이징 기법
✔️ 페이징 기법의 구현
페이징 기법은 고정 분할 방식을 이용한 가상 메모리 관리 기법으로, 물리 주소를 동일한 크기로 나누어 사용한다.
가상 주소의 각 영역은 프레임이라고 부르며, 물리 메모리의 각 영역은 구별을 위해 페이지라고 부른다.
고정 분할 방식이므로 프레임과 페이지의 크기는 같다. 따라서 페이지는 어떤 프레임에도 배치될 수 있다.
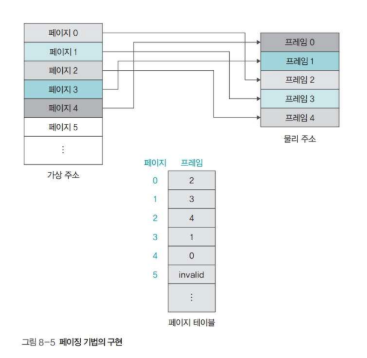
페이지 테이블의 한 개의 열로 구성된다.
모든 페이지의 정보를 순서대로 가지기 때문에, 위에서부터 차례대로 페이지 0, 1, 2와 연결된다.
위 사진에서 페이지 5는 Invalid로 표시되어 있는데, 이는 해당 페이지가 스왑 영역에 있음을 의미한다.
✔️ 페이징 기법의 주소 변환
페이징 기법에서 가상 주소가 물리 주소로 어떻게 변환되는지 알아보자.
페이지 및 프레임의 크기를 10B로 나누고, 10개의 주소를 가진다고 가정하자.
즉 페이지 0에는 0~9번의 주소가 있고, 페이지 1에는 10~19번의 주소가 있는 것이다.
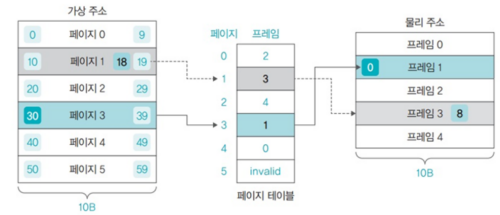
가상 주소 30번을 물리 주소로 변환하는 과정은 아래와 같다.
- 가상 주소 30번의 위치를 페이지에서 찾는다. 30번은 페이지 3의 0번에 있다.
- 페이지 테이블의 페이지 3으로 가서 해당 페이지가 프레임 1에 있음을 알아낸다.
- 따라서 물리 메모리 프레임 1의 0번째 위치에 접근한다.
정형화된 주소 변환
페이징 기법에서는 가상 주소를 로 표현한다.
각각 Virtual Address, Page, Distance를 의미한다.
따라서 가상 주소 30번을 표현하면 이 된다.
한편 물리 주소는 로 표현하고, 각각 Physical Address, Frame, Distance를 의미한다.
즉, 가상 주소 30번을 물리 주소로 표현하면 이 된다.
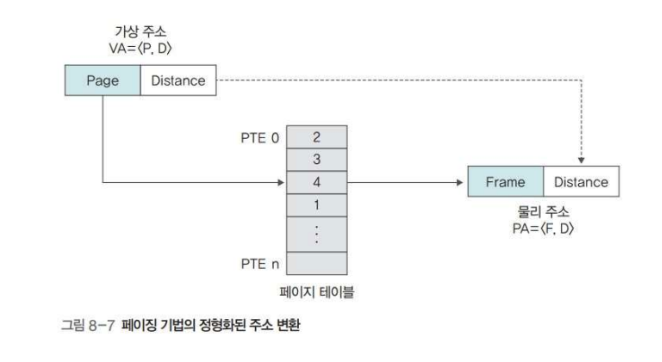
이때 페이지 테이블에서 행을 페이지 테이블 엔트리라고 부른다.
페이징 기법에서 페이지 테이블 엔트리는 프레임 번호만 가진다.
✔️ 페이지 테이블 관리
메모리 관리자는 특정 프로세스가 실행될 때마다 해당 페이지 테이블을 참조하여 가상 주소를 물리 주소로 변환한다.
페이지 테이블은 메모리 관리자가 자주 사용하는 자료구조이고, 빠른 접근을 위해 물리 메모리에서 운영체제 영역에 모아놓는다.
시스템 내에는 여러 프로세스가 존재하고 프로세스마다 테이블 페이지를 갖기 때문에, 전체 페이지 테이블의 크기는 프로세스 수에 비례해서 커진다.
따라서 페이지 테이블의 크기를 적절히 유지해 물리 메모리를 너무 많이 차지하지 않도록 하는 것이 페이지 테이블 관리의 핵심이다.
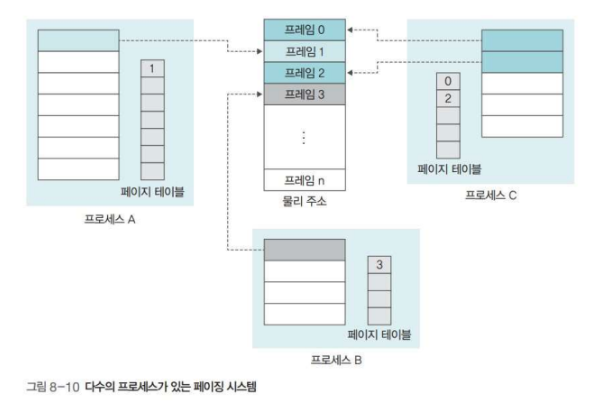
페이지 테이블의 수가 늘어나면 페이지 테이블이 저장되는 운영체제 영역이 늘어나고, 그만큼 사용자 영역이 줄어들게 된다.
물리 메모리의 크기가 작을 때는 프로세스 뿐만 아니라 페이지 테이블의 일부도 스왑 영역으로 옮겨진다.
페이지 테이블 기준 레지스터
각 프로세스가 메모리에 접근할 때, 메모리 관리자는 페이지 테이블의 위치를 빠르게 파악해야 한다.
따라서 페이지 테이블 기준 레지스터를 이용하며, 각 페이지 테이블의 시작 주소가 담기는 레지스터로 각 프로레스의 PCB에 저장된다.
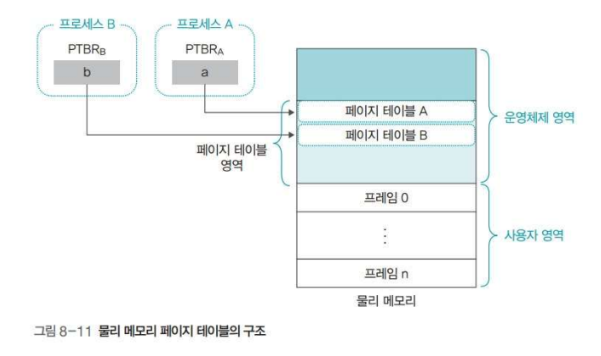
이제 고정 분할 방식에서 페이블 테이블을 관리하는 기법에 대해 알아보자.
🔑 쓰기 시점 복사
여러 개의 같은 브라우저를 메모리에 적재한다면 메모리가 낭비될 것이다.
이때 낭비를 방지하기 위해 메모리에 브라우저를 하나만 올려놓고 공유할 수 있다.
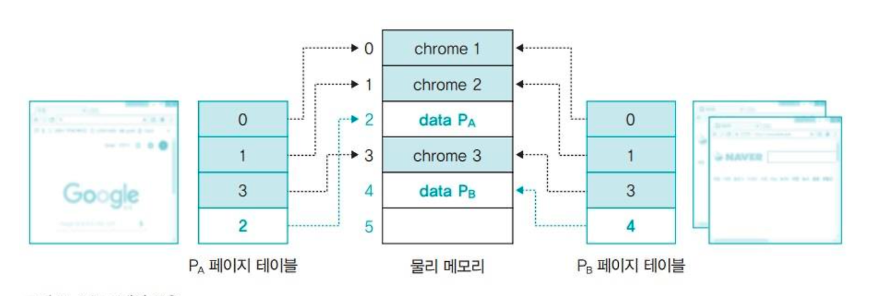
그러나 위 사진에서 프로세스 A는 구글을 보고 프로세스 B는 네이버를 보고 있기 때문에 데이터 영역을 공유할 수 없다.
따라서 데이터 영역은 프로세스별로 다르게 갖되, 나머지 영역은 동일한 메모리 영역을 공유하고 있다.
아래는 프로세스를 fork()로 복사한 직후이다.
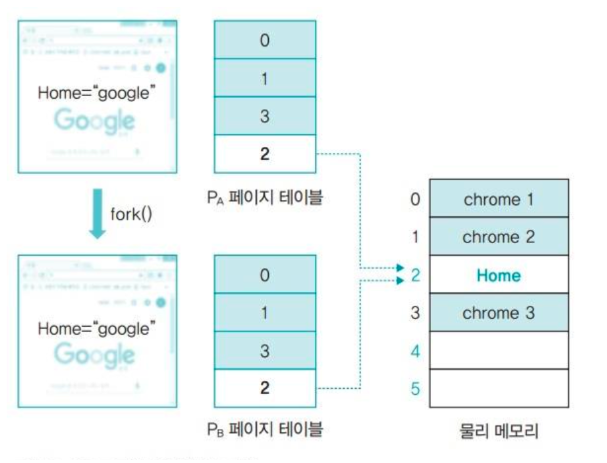
프로세스 A와 B는 동일한 브라우저 코드를 사용하므로 메모리 영역을 공유할 수 있고, 프로세스가 사용하는 변수(Home)는 내용이 변하기 때문에 공유할 수 없다.
그렇다면 공유할 수 없는 데이터를 위한 메모리 공간은 언제 확보해야 할까?
만일 변수를 위한 메모리 공간을 미리 확보했으나 변수의 내용이 끝까지 변하지 않는다면, 사용하지 않는 데이터를 위해 메모리를 낭비하게 된 것이다.
따라서 데이터의 변화가 생길 때까지 메모리 공간 확보를 미루는 것을 쓰기 시점 복사라고 한다.
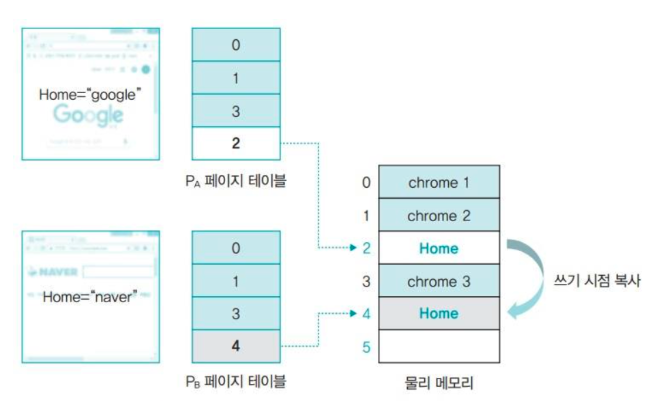
fork() 직후에는 두 프로세스의 변수가 Home = "google"로 동일하지만, 프로세스 B가 네이버로 이동하는 경우 메모리 영역을 복사한 후 Home = "naver"로 바꾼다.
🔑 변환 색인 버퍼 (TLB : Translation Look-ahead Buffer)
메모리 관리 유닛이 가상 주소를 물리 주소로 바꾸기 위해선 메모리에 두 번 접근해야 한다.
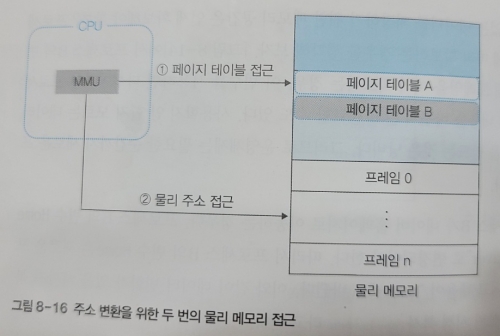
그러나 CPU 내 레지스터나 캐시에 접근할 때보다 물리 메모리에 접근하는 시간이 훨씬 커 CPU 성능이 저하된다.
따라서 페이지 테이블의 일부를 CPU 내로 가져오는데, 이를 변환 색인 버퍼라고 한다.
즉, 변환 색인 버퍼는 캐시된 페이지 테이블이다.
이때 지역성 이론에 근거하여 사용 중이거나 사용이 예상되는 페이지 테이블을 CPU 내로 가져온다.
변환 색인 버퍼 방식에서 메모리 관리자는 주소 변환을 위해 변환 색인 버퍼를 먼저 찾는다.
이때 변환 색인 버퍼에 원하는 페이지 번호가 있으면 TLB 히트, 없으면 TLB 미스라고 한다.
변환 색인 버퍼는 전체 페이지 테이블의 일부만 있기 때문에 <페이지 번호, 프레임 번호>로 구성된다.
TLB 히트라면 곧바로 물리 주소로 변환되며, TLB 미스의 경우 메모리에 있는 페이지 테이블을 사용해 물리 주소로 변환된다.
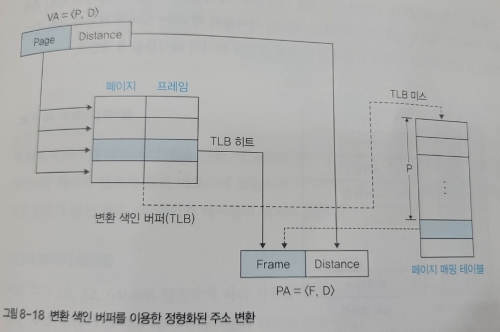
변환 색인 버퍼를 검색할 때 하드웨어적으로 병렬 검색이 가능하도록 구성된다.
따라서 한 번에 모든 행의 페이지를 검색하여 원하는 데이터가 있는지 확인할 수 있다.
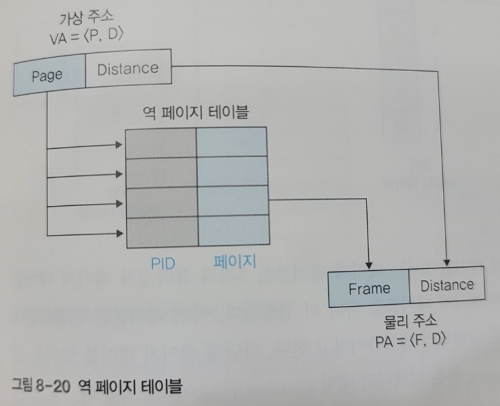
🔑 역 페이지 테이블
역 페이지 테이블 방식은 기존 페이징 방식과는 반대로 페이지 테이블을 구성한다.
즉, 역 페이지 테이블은 물리 메모리의 프레임 번호를 기준으로 페이지 테이블을 구성한다.
역 페이지 테이블의 가장 큰 특징은 물리 메모리를 기준으로 프레임 테이블을 만들기 때문에, 전체 시스템에서 테이블 수가 단 1개라는 점이다. 따라서 테이블 크기가 작다는 장점이 있다.
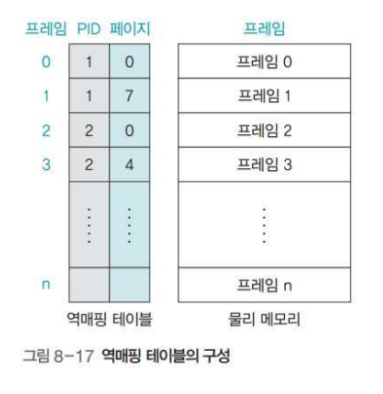
역 페이지 테이블의 0번 행은 프레임 0번에 1번 프로세스의 0번 페이지가 있음을 나타내는 형태로 구성된다.
이러한 역 페이지 테이블은 크기가 작으나 물리 메모리에 접근할 때 프로세스 아이디와 페이지 번호를 모두 찾아야 하는 것이 단점이다.
아래는 역 페이지 테이블 방식에서의 주소 변환 방법을 나타낸다.
🔑 다단계 페이지 테이블
비트 수가 16, 32, 64bit로 발전함에 따라 주소 공간 또한 급격히 늘어났다.
이로 인해 페이지 테이블의 크기 또한 커지게 되어 한 번에 관리하기 힘들어졌는데, 이를 해결하기 위한 방식이 다단계 페이지 테이블이다.
다단계 페이지 테이블은 일정 크기로 자른 페이지 테이블의 바깥쪽에 이를 관리하는 테이블을 만든다.
아래는 2단계 페이지 테이블의 구성을 나타낸 것이다.
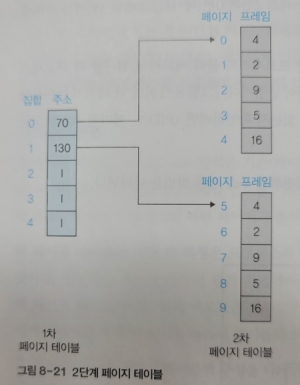
페이지 테이블을 5개씩 잘라 2차 페이지 테이블 만들었고, 이를 관리하는 1차 페이지 테이블을 생성했다.
1차 테이블은 일정하게 자른 2차 페이지 테이블의 물리 메모리 시작 주소를 나타낸다.
1차 테이블에서 I 라고 표시된 것은 2차 페이지 테이블이 아직 만들어지지 않았다는 의미이다.
즉, 다단계 페이지 테이블 방식에서는 페이지 테이블을 필요할 때마다 만들고, 앞 단계 페이지 테이블을 업데이트한다.
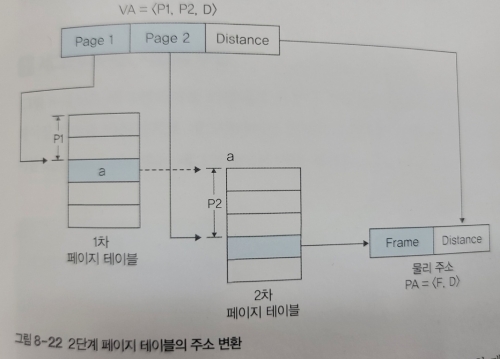
2단계 페이지 테이블 방식에서 가상 주소는 형태로 나타내며,
은 1차 페이지 테이블의 위치 정보를, 는 2차 페이지 테이블의 위치 정보를 나타낸다.
가상 주소는 1차 페이지 테이블을 거쳐 해당하는 2차 페이지 테이블로 이동한 뒤 물리 주소로 변환된다.
페이지 테이블을 10개씩 묶었다고 가정하면 가상 주소 127번은 로, 가상 주소 536번은 으로 변환된다.
물론, 페이지 테이블이 더 커지면 3단계나 4단계로 나누어 다단계 페이지 테이블을 구성할 수 있다.
이는 크기가 큰 페이지 테이블을 같은 크기의 묶음으로 나누어 효율적으로 관리할 수 있고, 페이지 테이블을 필요할 때마다 생성하고 관리함으로써 메모리 공간을 효율적으로 사용할 수 있다.
3️⃣ 세그먼테이션 기법
세그먼테이션 기법은 가변 분할 방식을 이용한 가상 메모리 관리 기법으로, 물리 메모리를 프로세스 크기에 따라 가변적으로 나누어 사용한다.
✔️ 세그먼테이션 기법의 구현
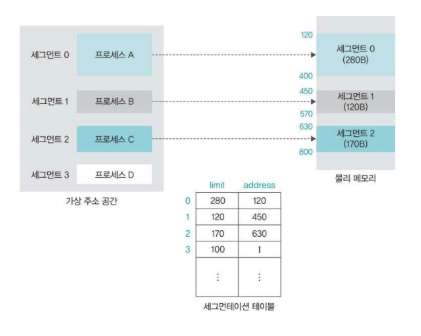
세그먼테이션 테이블에는 세그먼트의 크기를 나타내는 limit과 물리 메모리의 시작 주소를 나타내는 address가 있다.
메모리를 같은 크기로 나누는 페이징 기법과 달리 세그먼테이션 기법에서는 프로세스의 크기에 따라 메모리를 분할하기 때문에 크기 정보를 포함한다.
✔️ 세그먼테이션 기법의 주소 변환
세그먼테이션 기법에서는 가상 주소를 형태로 표기하며, S와 D는 각각 세그먼트 번호와 세그먼트 시작 지점부터의 거리를 나타낸다.
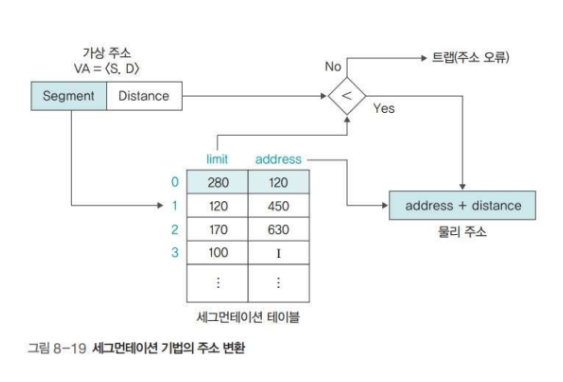
세그먼테이션 기법에서 위쪽에 나타낸 프로세스 A의 주소 32번을 변환하는 과정은 아래와 같다.
- 프로세스 A는 세그먼트 0으로 분할되었으므로 S와 D는 각각 0, 32이다.
따라서 가상 주소는 다. - 세그먼테이션 테이블에서 시작 주소가 120임을 알아내고, 거리 32를 더한 물리 주소 152를 구한다.
이때 메모리 관리자는 거리가 세그먼트의 크기(limit)보다 큰지 점검하고, 크다면 허용된 메모리를 벗어나므로 프로세스를 강제 종료한다. - 메모리 오류가 아니라면 물리 주소 152번에 접근하여 원하는 데이터를 읽거나 쓴다.
즉 limit은 메모리를 보호하는 역할을 하며, limit보다 큰 주소에 접근하려 하면 메모리 오류를 발생시키고 프로세스를 강제 종료한다. 이때 발생하는 오류를 트랩이라고 한다.
트랩은 인터럽트의 한 종류로, 트랩 발생 시 운영체제는 사용자에게 사용자에게 세그먼테이션 오류 메시지를 보낸다.
4️⃣ 캐시 매핑 기법
메모리의 페이징 방식과 마찬가지로 캐시도 메모리를 일정 크기로 나누고, 이를 형태로 나타낸다.
P는 페이지 번호, D는 페이지 내에서 거리를 의미한다.
캐시와 메모리를 매핑하는 다양한 기법에 대해 알아보자.
✔️ 캐시 직접 매핑
메모리를 개의 페이지, 캐시를 개의 페이지로 구성한 경우, 캐시는 메모리보다 작기 때문에 항상 이다.
캐시 직접 매핑에서는 메모리 페이지 수 을 캐시 페이지 수 으로 나누고 이를 블록이라고 한다.
캐시 직접 매핑에서 블록의 첫 번째 페이지는 캐시의 첫 번째 블록으로, 두 번째 페이지는 캐시의 두 번째 블록으로만 올라간다.
이때 캐시에 명시하는 블록 번호를 태그라 하고, 태그를 통해 캐시 히트나 캐시 미스를 확인한다.
그리고 블록에서의 거리를 나타내는 bd를 통해 캐시에서 원하는 데이터를 얻는다.
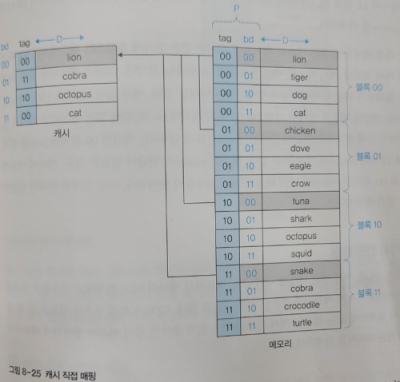
캐시 직접 매핑의 구조를 살펴보자. 메모리의 전체 크기를 16B, 한 페이지의 크기를 1B로 가정하자.
캐시 메모리의 크기를 4B로 가정하면 메모리는 캐시의 크기로 나뉘므로 4개의 블록이 만들어진다.
메모리에서 주소 4bit 중 앞의 2bit는 태그를 나타내고, 이는 블록 번호를 의미한다.
뒤의 2bit는 bd를 나타내며, 캐시에서 적재될 위치 정보를 나타낸다.
뒤의 동물 영단어는 이해를 위해 나타낸 정보이다.
캐시 직접 매핑 방식은 메모리의 페이지가 캐시의 정해진 위치에만 들어갈 수 있다고 언급한 바 있다.
즉, bd가 00이면 캐시의 00 위치에, bd가 01이면 캐시의 01 위치에 들어갈 수 있다.
같은 의미로 캐시의 00 위치에는 lion, chicken, tuna, snake만 올라갈 수 있다.
캐시는 태그를 통해 00 위치에 lion, chicken, tuna, snake 중 무엇이 올라왔는지 확인한다.
태그는 블록 번호를 의미하기 때문이다.
예를 들어 CPU가 메모리 0111의 crow가 필요하다면, CPU 캐시의 11 위치(bd)에 가서 태그가 01인지 확인한다.
그러나 위 사진에서 태그는 00이므로 캐시 미스가 발생하고, CPU는 메모리의 0111로 가서 crow를 가져온다.
장단점
- 장점 : 태그만 확인하면 캐시 히트나 캐시 미스를 파악할 수 있다.
- 단점 : 페이지가 같은 위치에만 올라오기 때문에 자리다툼이 자주 발생한다.
- 예로 lion과 snake가 연달아 필요한 경우, 두 데이터를 모두 캐시에 적재할 수 없어 캐시 적중률이 떨어진다.
✔️ 캐시 연관 매핑
아래는 캐시 연관 매핑 구조를 나타낸 이미지다.

캐시 연관 매핑 구조는 메모리가 캐시의 어느 위치에도 자유롭게 올라갈 수 있도록 캐시가 메모리의 주소를 전부 가진다.
장단점
- 장점 : 메모리가 캐시를 자유롭게 사용할 수 있다.
- 단점 : 캐시 히트나 캐시 미스를 확인하기 위해 캐시의 모든 주소를 검색해야 한다. 따라서 캐시 직접 매핑보다 느리다.
✔️ 캐시 집합-연관 매핑
캐시 직접 매핑과 캐시 연관 매핑의 장점만 취한 방식으로,
캐시 집합-연관 매핑은 캐시를 개 집합으로 나누고 각 집합에 캐시 직접 매핑을 적용한다.
앞서 살펴본 캐시 직접 매핑의 단점은 동일한 bd의 캐시에 대해 자리가 하나밖에 없어 자리다툼이 발생한다는 점이었다.
집합-연관 매핑에서는 직접 매핑을 하는 캐시 메모리를 로 나눔으로써 같은 bd의 캐시 또한 개가 되어 자리다툼 문제가 완화된다.
또한 연관 매핑처럼 모든 캐시를 뒤지는 일 없이 바로 캐시 히트 여부를 알 수 있다.
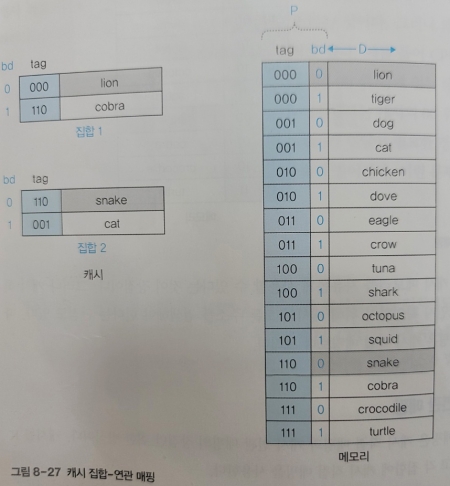
위 이미지는 캐시를 2개의 집합()로 나누고 하나의 집합에 2개의 페이지를 사용할 수 있도록 했다.
따라서 물리 메모리의 주소 4bit 중 마지막 1bit만 bd를 나타내고, 앞 3bit는 태그를 나타낸다.
즉, 주소의 끝이 0이라면 2개의 집합 중 비어있는 첫 번째 위치에 적재된다.
이를 통해 직접 매핑에서 lion과 snake가 모두 캐시에 적재되지 못하는 문제점이 완화된다.
👏 마무리
가상 메모리의 개념과 고정 분할 방식, 가변 분할 방식에서의 메모리 페이지 관리 기법에 대해 알아봤다.
본 포스팅에서 가상 메모리의 배치 정책을 살펴봤다면, 다음 포스팅에서는 가상 메모리 기법에서의 가져오기 정책과 재배치 정책에 대해 알아보자.
참고 자료
💕좋아요와 댓글은 큰 힘이 됩니다.💕
