성능개선 시리즈 - N+1 해결 및 TPS 개선을 중심으로
배경
저번 글에 이어서 성능개선 시리즈를 작성해보겠습니다.
저번 글에서는 슬로우 쿼리의 속도를 제한적으로(10ms)로 설정해서 임의로 슬로우 쿼리 탐지가 정상적으로 잘 작동하는 것을 확인해보았습니다.
AOP를 통해 구현한 N+1 역시 잘 탐지되는지 확인을 해볼까요?
N+1이 대부분 조회 시에 발생하는 문제라는 것을 염두에 두고, 1000만건의 데이터를 삽입한 Product Table을 향해 20개의 데이터로 끊어서 1페이지를 조회하였습니다.
아래와 같이 N+1이 의심되는 쿼리가 발생했습니다.

무엇이 N+1(추정)을 유발하는지 한 번 확인해볼까요?
N+1의 원인
N+1이 추정되는 쿼리는 다음과 같습니다.
- N + 1이 의심되는 api 정보: NPlusOneSuspiciousDto
{url='url: GET /api/v1/products', duration=250, query2cnt={
호출된 횟수: 20, 호출된 쿼리:
select i1_0.id,i1_0.created_at,
i1_0.deleted_at,
i1_0.file_type,
i1_0.full_path_url,
i1_0.is_deleted,i1_0.modified_at,
i1_0.target_id,
i1_0.upload_name
from Image i1_0
where i1_0.target_id=?,
호출된 횟수: 1,
호출된 쿼리:
// 이하 생략(호출 회수가 1회이므로)
}호출 횟수가 1회인 쿼리를 제외하고, 호출횟수가 20회인 쿼리를 중점으로 살펴보겠습니다.
해당 쿼리는 Image에서 targetId를 where절에 조건으로 생성되는 쿼리인데요. 호출회수가 20회인것으로 보아 size문제와 밀접하게 연관된 것으로 유추됩니다.
size를 200으로 설정해보면 어떻게 될까요?
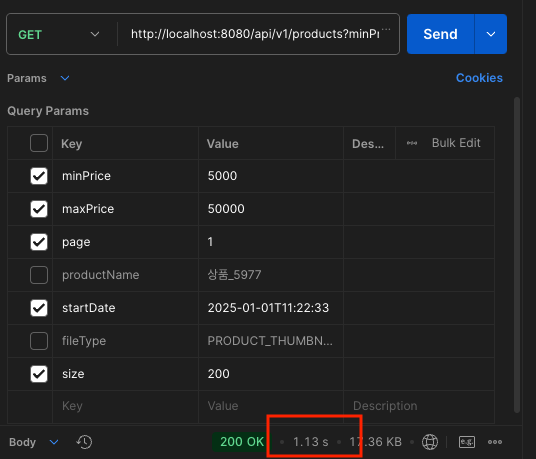
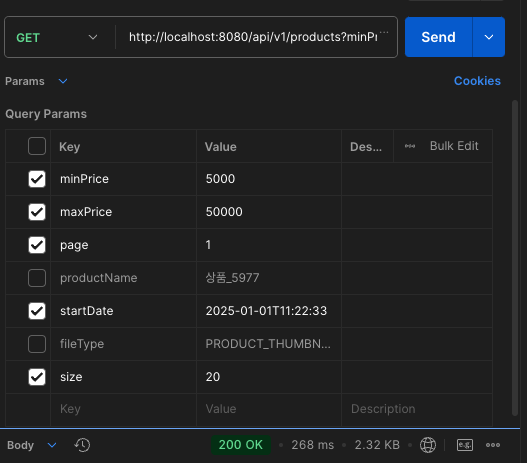
Postman에서 위와 같이 size를 200으로 설정 후 API 호출을 수행하였습니다.
호출결과 무려 1.13초나 소요되는 것을 알 수 있습니다.
결과는 보다시피 동일한 쿼리가 200회 호출된 것으로 보아 size를 어떻게 설정하느냐에 따라서 N(추가 쿼리)가 결정된다라는 것을 확인할 수 있습니다.
부하테스트를 통해서 TPS를 측정해보고 N+1 발생이 의심되는 지점에 대해서 리팩토링 후 다시 부하테스트를 진행하는 형식으로 진행해보도록 하겠습니다.
부하테스트 진행
부하테스트 툴은 Jmeter를 사용했으며, 진행 조건은 다음과 같습니다 .
- Number of Threads(users)
- 100
- Ramp-up period(seconds)
- 50(비교적 짧게 잡음)
- Loop Count
- 10회
성능테스트의 효과를 확실히 체감하기 위해서 Size를 200개 조회한다고 가정하도록 하겠습니다.
위와 같은 가정으로 부하테스트를 돌려보면 아래와 같습니다.
size 200개 조회 시
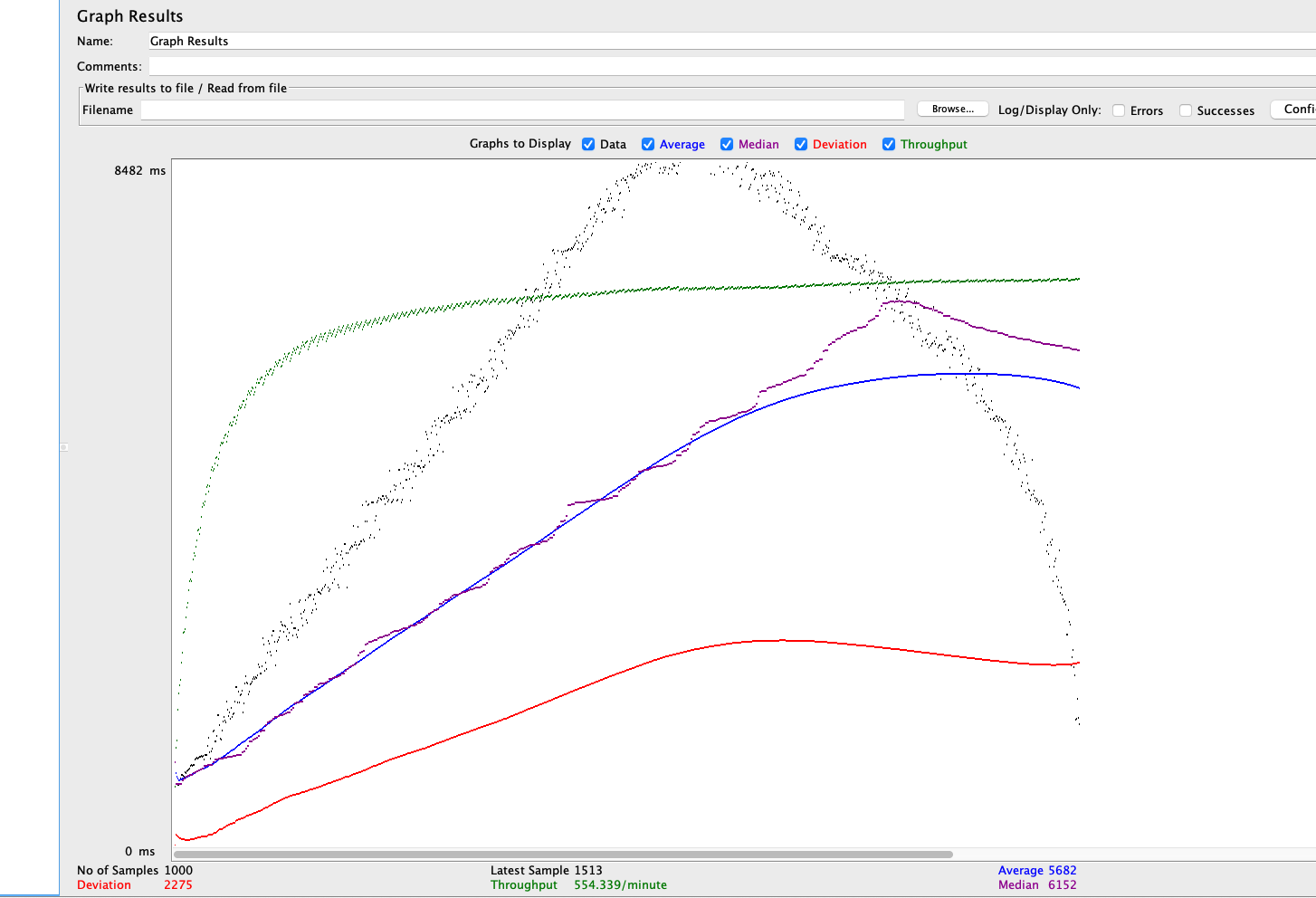
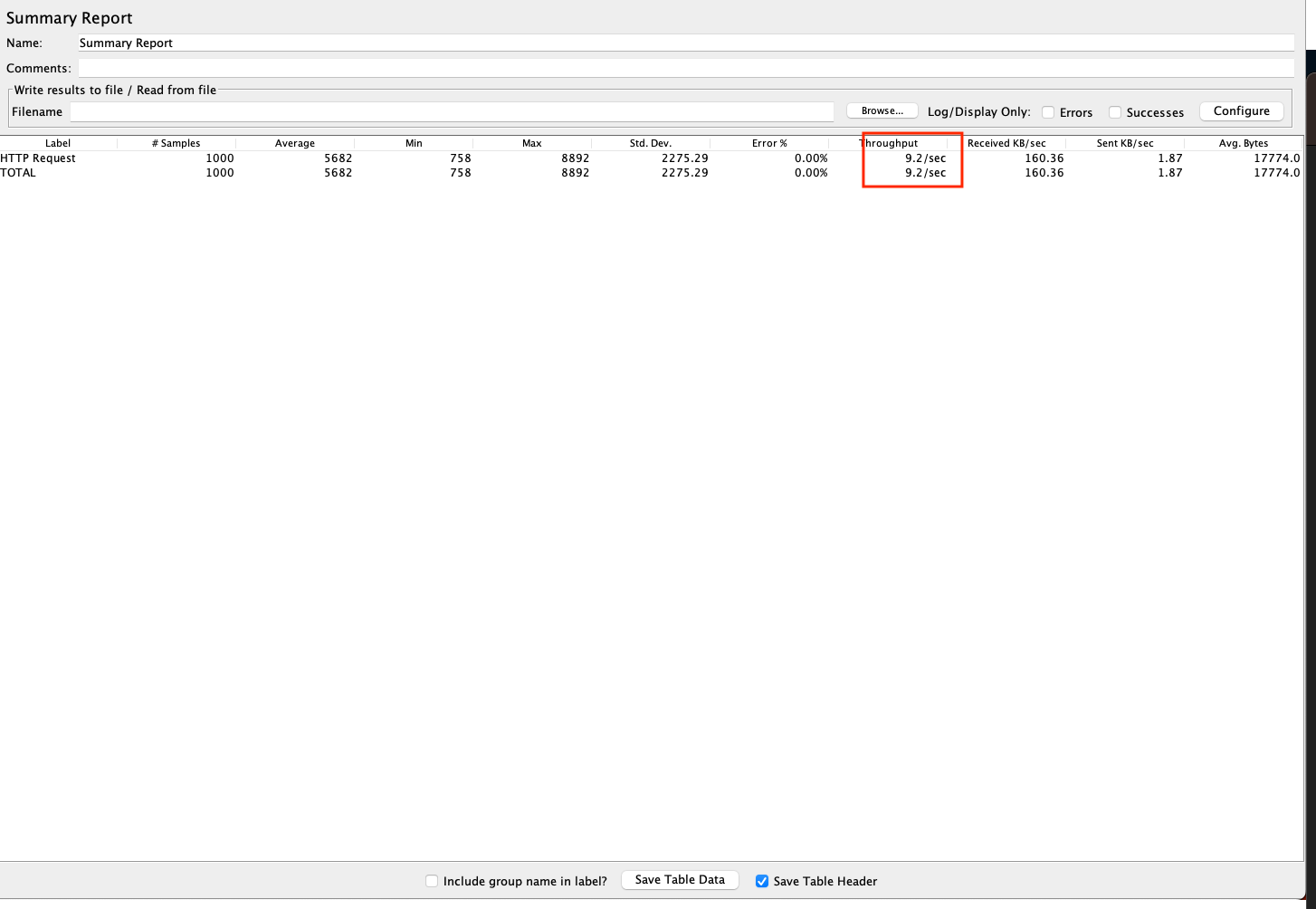
TPS가 9.2가 나오는 것을 확인할 수 있습니다.
N+1의 원인
쿼리를 다시 한 번 잘 살펴보면 Product와 Image를 조회(Select)시에 발생한 문제인 것을 확인할 수 있습니다.
Product와 Image는 직접적인 연관관계를 확장성 측면에서 맺어주지 않았습니다.(Product와 Image를 굳이 연관관계를 맺어주지 않은 까닭은 Image에서 @ManyToOne 연관관계를 맺어줘도 무방하지만, 추후 다른 도메인으로의 확장성을 고려하면 과연 연관관계를 맺어주는게 적절할까하는 것에 대해서 고민했기때문입니다.)
따라서 Product와 Image를 직접적 @ManyToOne연관관계를 사용하지 않은 관계로 fetch join등으로 풀 수있는 문제가 아닙니다. 어떻게 해결할 수 있을까요?
문제의 로직
Image Entity에서 필드로 지정한 ‘target_id’를 기반으로 where 문 이하로 서로 연결할 수 있습니다.
Application에서 Querydsl을 이용하여 Product와 관련된 정보를 가지고오고, Image와 관련된 정보를 가져와서 조립하여 Presentation Layer로 보내주도록 구성하였는데요.
문제의 핵심은 Image를 조회하는 쿼리였습니다.
DB 테이블상 Product와 Image는 현재 서로 연관관계를 맺고있지 않습니다.
public Slice<ProductQueryResponseDto> searchProductsBefore(final ProductSearchConditionRequestDto productSearchConditionRequestDto, final Pageable pageable) {
// 상품조회 조건 생성하는 코드(생략)
// QUERYDSL을 통해서 ProductDomain을 Slice해오는 코드
Slice<ProductDomain> productDomains = productRdbService.getAllProductList(productSearchCondition, pageable);
// 문제가 되는 코드
for (ProductDomain content : contents) {
List<ImageDomain> imageDomains = productImageService.searchProductImagesBefore(content.getProductId().getValue(), productSearchConditionRequestDto.getFileTypes());
listDtos.add(ProductDtoMapper.toSearchResponseDto(content, ImageDtoMapper.toImageResponseDto(imageDomains)));
productIds.add(content.getProductId().getValue());
}
return new SliceImpl<>(listDtos, pageable, productDomains.hasNext());
}
상단의 Application 로직에서 조회한 ProductDomain을 기반으로 하단의 쿼리를 하나씩 실행하기 때문에 Slice에서 조회된 ProductDomain의 개수만큼 Image를 조회하는 쿼리가 실행되는 것입니다. Slice의 크기는 클라이언트에서 받아온 개수만큼 잘라지기 때문에 그 크기가 커질 수록 당연히 성능에는 악영향이 갈 것입니다.
@Query("select i from Image i where i.fileType in :fileTypes and i.targetId =:targetId")
List<Image> findImagesByTargetIdAndFileType(@Param("fileTypes") List<FileType> fileType, @Param("targetId") Long targetId);
In절을 통한 쿼리수 감소
상단의 로직을 어떻게 수정할 수 있을까요?
일단 쿼리를 손 볼 수 있습니다.
where 문 이하를 단순히 하나의 targetId를 가지고 오는게 아니라, 전체 targetId를 가지고 와서 in절로 활용하면 각 개별 쿼리가 수행되지 않게 구성할 수 있습니다.
수정한 쿼리의 로직은 다음과 같습니다.
@Query("select i from Image i where i.targetId in :targetIds and i.fileType in :fileTypes and i.isDeleted = false ")
List<Image> findImageByTargetIdsAndFileTypes(@Param("targetIds") List<Long> targetIds, @Param("fileTypes") List<FileType> fileTypes);
쿼리를 수정했다면 Application level(domain-service 모듈)에서의 로직도 손을 봐야겠지요?
public Slice<ProductQueryResponseDto> searchProducts(final ProductSearchConditionRequestDto requestDto, final Pageable pageable) {
// DTO -> 검색 조건 객체 변환
ProductSearchCondition searchCondition = requestDto.toProductSearchCondition();
// 상품 리스트 조회
Slice<ProductDomain> productDomains = productRdbService.getAllProductList(searchCondition, pageable);
List<ProductDomain> contents = productDomains.getContent();
// 상품 ID 목록 추출
List<Long> productIds = contents.stream()
.map(content -> content.getProductId().getValue())
.collect(Collectors.toList());
// 상품 이미지 조회
List<ImageDomain> imageDomains = productImageService.searchProductImages(productIds, requestDto.getFileTypes());
// ProductQueryResponseDto 리스트 변환
List<ProductQueryResponseDto> responseDtos = contents.stream()
.map(content -> mapToProductQueryResponseDto(content, imageDomains))
.collect(Collectors.toList());
return new SliceImpl<>(responseDtos, pageable, productDomains.hasNext());
}
// 변환 메서드 추가
private ProductQueryResponseDto mapToProductQueryResponseDto(ProductDomain product, List<ImageDomain> imageDomains) {
List<ImageDomain> matchedImages = imageDomains.stream()
.filter(image -> image.getTargetId().equals(product.getProductId().getValue()))
.collect(Collectors.toList());
return ProductDtoMapper.toSearchResponseDto(product, ImageDtoMapper.toImageResponseDto(matchedImages));
}
상단의 로직에서 확인되는 것처럼 조회한 상품 Id 값을 모두 넘겨준 이후에 List를 조회 후 조립하는 것을 알 수 있습니다.
자 이제 n+1이 터지지 않는 것을 확인할 수 있습니다.
그렇다면 PostMan으로 실험하여 성능이 얼마나 개선되었는지를 확인해 볼까요?
성능테스트
동일조건으로 위와 같이 로직을 개선한 이후
0.36s로 기존에 비해서 3배 이상 속도가 개선된 것을 확인할 수 있습니다.
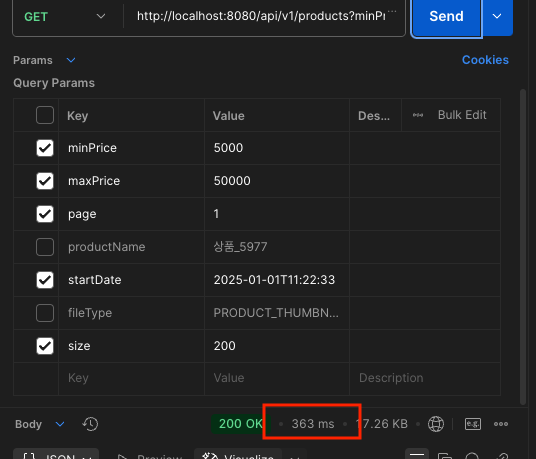
N+1 문제 해결 후 부하테스트 진 행
부하테스트를 진행하면 어떻게 될 지 한 번 확인해보겠습니다.
서두에 언급했던 동일한 조건으로 부하테스트를 실행해보겠습니다.
- Number of Threads(users)
- 100
- Ramp-up period(seconds)
- 50(비교적 짧게 잡음)
- Loop Count
- 10회
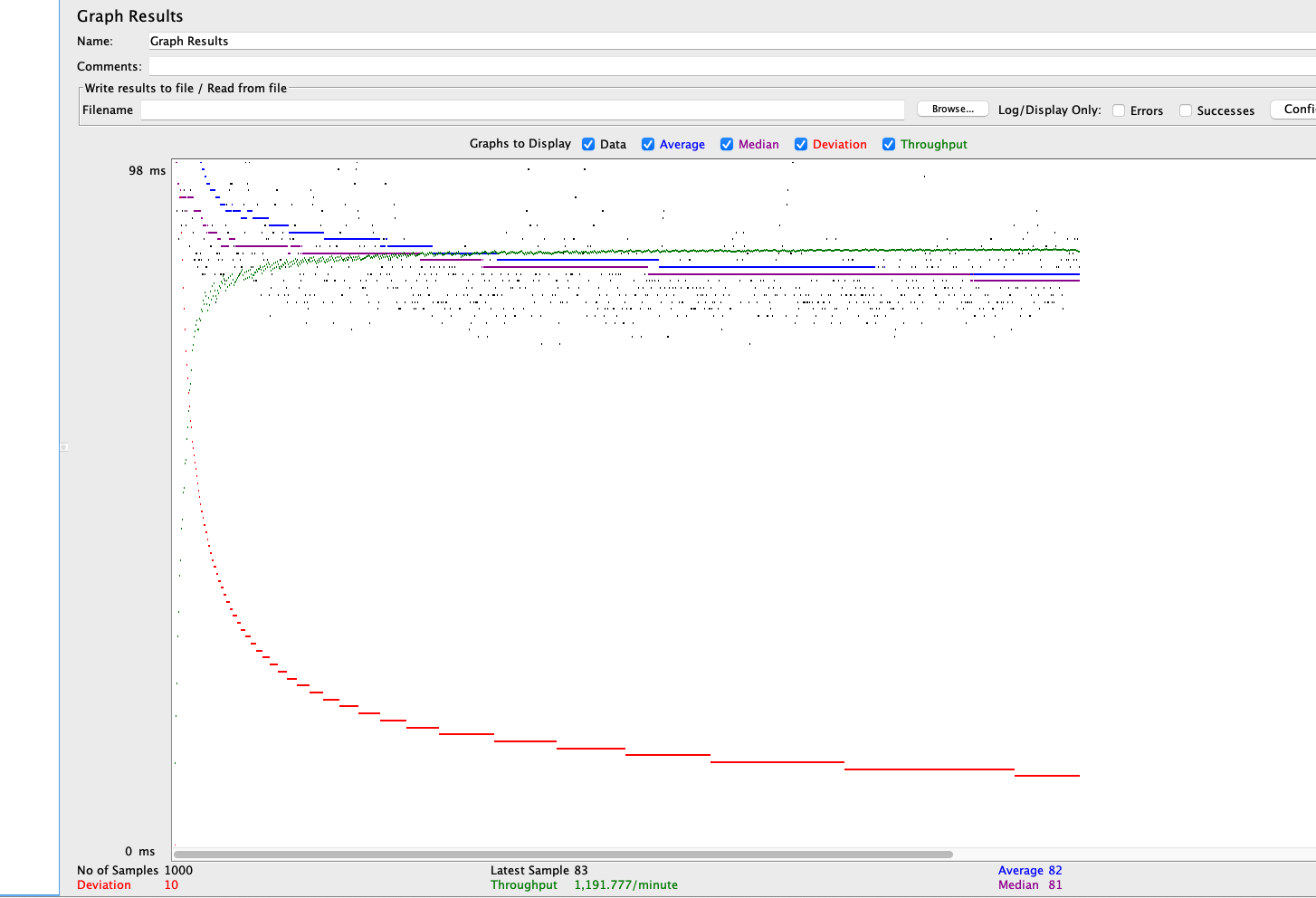
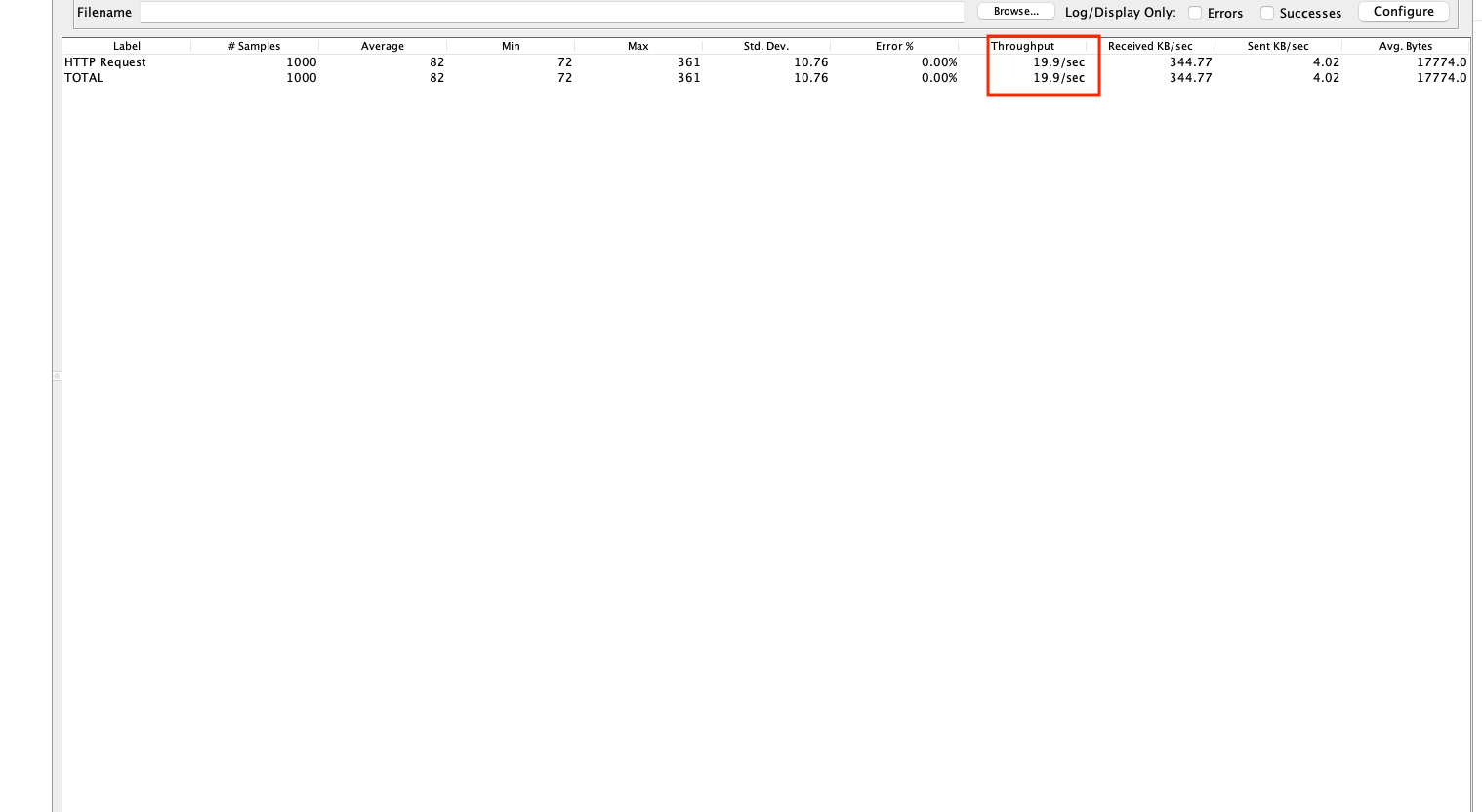
그래프에서 확인할 수 있는 것처럼 TPS가 19.9까지 향상됨을 알 수 있습니다.
쿼리가 200개가 보내지던 것이 1+N(200)이 1+1이 되었으므로 당연한 결과로 보입니다.
N+1해결 전후 부하테스트 결과표
종합적으로 결과를 파악해보자면 아래와 같습니다.
| 테스트 조건 | N+1 문제 미해결 | N+1 문제 해결 후 | 개선율 |
|---|---|---|---|
| TPS (Transactions Per Second) | 9.2 | 19.9 | +116.3% |
| 쿼리 실행 횟수 | 다중 개별 쿼리 (1 + N 개) | 단일 조회 쿼리 | 최적화됨 |
| 소요시간 * PostMan측정시 | 1.36s | 0.363s | 3배 가까이 상승 |
| 네트워크 왕복 횟수 | 많음 (N번 요청) | 적음 (1회 요청) | 최적화됨 |
마무리
이번 글에서는 실제로 N+1 문제가 발생하는 원인을 추적하고, 이를 해결하기 위한 IN 절을 활용한 최적화 방법을 적용한 후 성능을 비교해보았습니다.
그 결과, 기존에 발생하던 다중 개별 쿼리 문제를 단일 조회 쿼리로 개선함으로써 TPS는 9.2 → 19.9로 약 116% 증가하였으며, 응답 속도도 3배 이상 향상되는 효과를 확인할 수 있었습니다.
