04-01. 자료구조 (파이썬) - 2
튜플
20_튜플(Tuple)
튜플(Tuple)이란?
- 리스트(List)와 비슷하지만 아이템 변경/수정이 불가하다.
- [ ]가 아닌 ( ) 사용
튜플 선언
-
'()'를 이용해서 선언하고, 데이터 구분을 ','를 이용한다.
-
숫자, 문자(열), 논리형 등 모든 기본 데이터를 같이 저장할 수 있다.
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은') numbers = (10, 20, 30, 40, 50, 60, 70) strs = (3.14, '십', 20, 'one', '3.141592') -
튜플에 또 다른 컨테이너 자료형 데이터를 저장할 수도 있다.
datas = (10, 20, 30, (40, 50, 60))
-
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
print(type(students))
print(students)
myFamilyNames = ('홍아빠', '홍어마', '홍길동', '홍동생')
print(myFamilyNames)
myFamilyNames[2] = '홍홍홍' # 아이템 수정 불가
21_튜플 아이템 조회
인덱스
- 튜플도 리스트와 마찬가지로 아이템에 자동으로 부여되는 번호표가 있다.
- 잘못된 인덱스를 사용하면 에러 발생
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
print(students)
print(students[0])
print(students[1])
print(students[2])
print(students[3])
print(students[4])
print(students[5]) # 없는 index이기 때문에 오류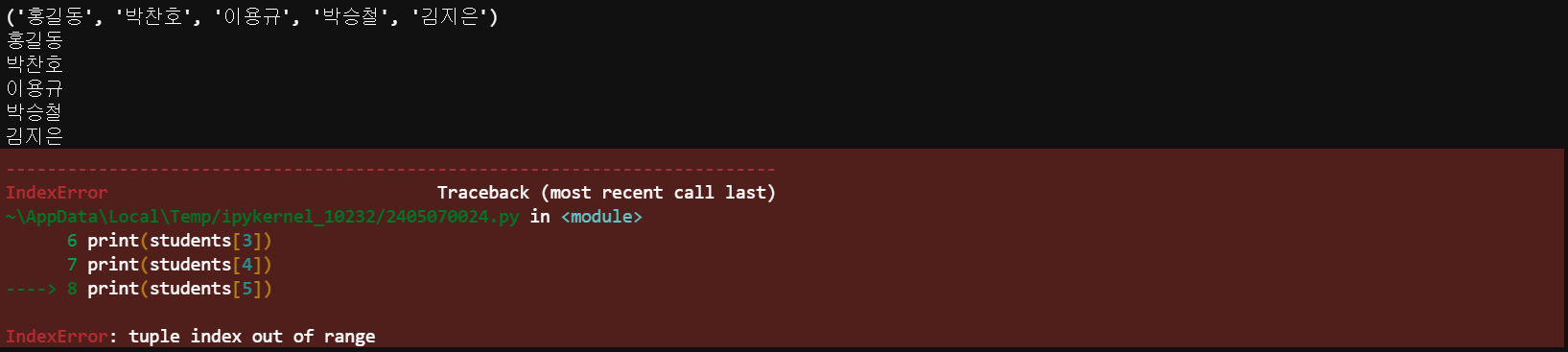
numbers = (10, 20, 30, 40, 50, 60, 70)
print(numbers)
print(numbers[0])
print(numbers[6])
# 5명의 학생 이름을 튜플에 저장하고 인덱스가 홀수인 학생과 짝수(0포함)인 학생을 구분해서 인덱스와 학생 이름을 출력
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
for i in range(5):
if i % 2 == 0:
print('인덱스 짝수:', i, '-', students[i])
else:
print('인덱스 홀수:', i, '-', students[i])
22_in과 not in 키워드
in, not in 키워드
- in, not in 키워드를 이용하면 아이템의 존재 유/무를 알 수 있다.
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
search = input('학생 이름 입력:')
if search in students: # search가 students에 있다면 True
print('{} 학생은 우리반 학생입니다.'.format(search))
else:
print('{} 학생은 우리반 학생이 아닙니다.'.format(search))
- in, not in 키워드는 문자열에서도 사용 가능하다.
pythonStr= "파이썬[3](영어: Python)은 1991년[4] 프로그래머인 귀도 반 로섬[5]이 발표한 고급 프로그래밍 언어로, \
플랫폼에 독립적이며 인터프리터식, 객체지향적, 동적 타이핑(dynamically typed) 대화형 언어이다. \
파이썬이라는 이름은 귀도가 좋아하는 코미디 〈Monty Python's Flying Circus〉에서 따온 것이다."
print('Python:\t', 'Python' in pythonStr)
print('python:\t', 'python' in pythonStr)
print('파이썬:\t', '파이썬' in pythonStr)
print('파이선:\t', '파이선' in pythonStr)
print('귀도:\t', '귀도' in pythonStr)
print('객체지향적:', '객체지향적' in pythonStr)
# 컴퓨터가 1부터 10까지 5개의 난수를 생성한 후, 사용자가 입력한 숫자가 있는지 없는지 출력하는 프로그램 만들기
import random
randomNumbers = random.sample(range(1, 11), 5)
userNumber = int(input('숫자 입력:'))
if userNumber in randomNumbers:
print('빙고!')
else:
print('Wrong!')
print("what we have:", randomNumbers)
print('yours:', userNumber)
# 문장에서 비속어를 출력하는 프로그램 만들기
wrongWord = ['쩔었다', '짭새', '꼽사리', '먹튀', '지린', '쪼개다', '뒷담 까다']
sentence = '짭새 등장에 강도들은 모두 쩔었다. 그리고 강도들은 지린 듯 도암갔다.'
for word in wrongWord:
if word in sentence:
print('비속어: {}'.format(word))
23_튜플 길이
아이템 개수
- 리스트와 마찬가지로, 튜플에 저장된 아이템 개수를 튜플 길이라고 한다.
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
length = len(students)
print('length:', length)
len()을 이용한 조쇠
- len()과 반복문을 이용하면 튜플의 아이템 조회가 가능하다.
- 튜플의 길이만큼 반복문을 실행 할 수 있다.
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
# for문
for i in range(len(students)): # 5번 반복
print('i : {}'.format(i))
print('students[{}] : {}'.format(i, students[i]))
print('-'*30)
# while문
n = 0
length = len(students)
while n < length:
print('n : {}'.format(n))
print('students[{}] : {}'.format(n, students[n]))
n += 1 # n이 4가 될 때까지 = index 4에 도달할 때 까지
students = ('홍길동', '박찬호', '이용규', '박승철', '김지은')
for student in students: # 아이템 하나하나씩 반복문을 돌리는 것도 가능
print('stduent: ', student)
# 좋아하는 운동 종목을 튜플에 저장하고 반복문을 이용해 출력해 보자
my_sports = ('수영', '배구', '야구', '조깅')
for i in range(len(my_sports)):
print('my_favorite_sport:', [i], my_sports[i])
for sport in my_sports:
print('my_favorite_sport:', sport)
24_튜플 결합
튜플 결합
- 두 개의 튜플을 결합하여/합쳐서 새로운 튜플을 만들 수 있다.
students1 = ('홍길동', '박찬호', '이용규')
students2 = ('박승철', '김지은', '강호동')
new_students = students1 + students2
print(new_students)
리스트 vs 튜플
- 리스트에서 사용할 수 있는 extend() 함수를 튜플에서는 사용 할 수 없다.
students1 = ('홍길동', '박찬호', '이용규')
students2 = ('박승철', '김지은', '강호동')
students1.extend(students2) # extend()는 확장, 즉, 변경/수정이 되는 개념이기 때문에 튜플에서는 안 된다
print(students1) # 오류
# 튜플을 이용해 나와 친구가 좋아하는 번호를 합치되 번호가 중복되지 않게 하는 프로그램 만들기
my_num = (1,3,5,6,7)
friend_num = (2,3,5,8,10)
for number in friend_num:
if number not in my_num: # 친구 번호가 내 번호에 없다면
my_num = my_num + (number, ) # 내 번호와 합치기; number자체는 integer(정수)이다; tuple은 tuple과 결합 할 수 있다;
# item이 하나인 tuple로 선언하기 위해선 ','를 뒤에 붙여주면 됨
print(my_num)
25_튜플 슬라이싱
튜플 슬라이싱
- 리스트와 마찬가지로 [n:m]을 이용하면 튜플에서 원하는 아이템만 뽑아낼 수 있다.
- ex) [2:4] --> 2 <= n < 4
students = ('홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은')
print(students)
print(students[2:4])
print(students[3:])
print(students[:5])
print(students[:-2])
print(students[2:-2])
print('-'*30)
numbers = (2, 50, 0.12, 1, 9, 7, 17)
print(numbers)
print(numbers[2:4])
print(numbers[3:])
print(numbers[:5])
print(numbers[:-2])
print(numbers[2:-2])
슬라이싱 단계 설정
- 슬라이싱 할 때 단계를 설정할 수 있다.
numbers = (2, 50, 0.12, 1, 9, 7, 17)
print(numbers)
print(numbers[2:-2])
print(numbers[2:-2:2])
print(numbers[:-2:2])
print(numbers[::2])
슬라이싱을 이용한 아이템 변경
- 튜플은 슬라이싱을 이용해서 아이템을 변경 할 수 없다.
- 리스트에 튜플 아이템으로 변경 가능
students = ('홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은')
students[1:4] = ('park chanho', 'lee younggyu', 'gang hodong')
print(students)
students = ['홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은'] # 리스트에
students[1:4] = ('park chanho', 'lee younggyu', 'gang hodong') # 리스트의 [1:4] 데이터를 튜플의 아이템으로 변경하겠다 라는건 가능하다
print(students)
print(type(students)) # 튜플의 아이템으로 변경했다 하더라도 원래 데이터 타입은 리스트이기 때문에 리스트 그대로
slice() 함수
- slice() 함수를 이용해서 아이템을 슬라이싱 할 수 있다.
students = ('홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은')
print(students[slice(2,4)])
print(students[slice(4)])
print(students[slice(2,len(students))])
print(students[slice(2,len(students)-2)]) #[2:4]
print(students[slice(len(students)-5,len(students)-2)]) # [1:4]
26_리스트와 튜플
리스트와 튜플의 차이점
- 튜플은 리스트와 달리 아이템 추가, 변경, 삭제가 불가하다.
- student.append(), stduent[2] = '유재석', student.pop()
- 튜플은 선언시 괄호 생략이 가능하다.
- stduents = ('홍길동', '박찬호', '이용규', '강호동') --> tuple
- stduents = '홍길동', '박찬호', '이용규', '강호동' --> tuple
- 리스트와 튜플은 자료형 변환이 가능하다.
- tuple(students) <--> list(students)
# 튜플은 이용한 점수표에서 최저, 최고 점수를 삭제한 후 총점과 평균을 출력
scores = (9.5, 8.9, 9.2, 9.8, 8.8, 9.0)
print('scores:', scores)
print(type(scores)) # 튜플
# 최저, 최고 점수 삭제
scores = list(scores) # 우선 리스트로 변환 (그래야 정렬이 가능)
print(type(scores))
scores.sort() # 정렬; 오름차순
print(scores)
scores.pop(0) # 최저 점수 삭제; 첫번째 index
scores.pop(len(scores)-1) # 최고 점수 삭제; 길이-1 = 마지막 index
scores = tuple(scores) # 최저, 최고 점수 삭제한 리스트를 다시 튜플로 변환
print(scores)
print(type(scores))
# 총점고 평균 출력
sum = 0
avg = 0
for score in scores:
sum += score # 총점
avg = sum / len(scores) # 평균
print('총점:', round(sum,2))
print('평균:', round(avg,2))
27_튜플 아이템 정렬
튜플 정렬
- 튜플은 수정이 불가하기 때문에 리스트로 변환 후 정렬하자
- list() - 자료형 변환
- sort() - 오름차순 정렬
- tuple() - 자료형 변환
- sort() 함수를 이용하면 아이템을 정렬 할 수 있다.
- 리스트로 변환 후 sort()
- ex) list() --> sort(reverse=True) --> tuple()
- reverse=True: 내림차순 정렬
- sorted()
- sorted() 함수를 이용하면 튜플도 정렬 할 수 있다.
- sorted() --> 오름차순 정렬
- sorted()는 리스트 자료형을 반환한다.
- 튜플은 아이템이 변경 될 수 없기 때문에, sorted()를 적용하면 데이터는 리스트로 된 새로운 자료형으로 반환된다.
students = ('홍길동', '박찬호', '이용규', '강호동', '박승철', '김지은')
print(students)
print(type(students))
students = list(students) # tuple을 list로 변환
students.sort() # list를 정렬
print(students)
print(type(students))
students = tuple(students) # tuple로 다시 변환
students = sorted(students) # tuple을 바로 정렬
print(students)
print(type(students)) # list로 반환됨
28_튜플과 for문(1)
for문을 이용한 조회
- for문을 이용하면 튜플의 아이템을 자동으로 참조/조회 할 수 있다.
cars = '그랜저','소나타','말리부','카니발','쏘렌토'
for i in range(len(cars)):
print(cars[i])
print('-'*30)
for car in cars:
print(car)
for문을 이용한 내부 튜플 조회
- for문을 이용하면 튜플 내부에 또 다른 튜플의 아이템을 조회할 수도 있다.
sum = 0
avg = 0
class_students = (1,19), (2,20), (3,22), (4,18), (5,21)
for class_no, cnt in class_students: # tuple안의 또 다른 tuple 아이템의 내용을 2개의 변수를 사용/대입하여 자동으로 2개 다 가져올 수 있다
print('{}학급 학생수: {}'.format(class_no, cnt))
sum += cnt
avg = sum / len(class_students)
print('전체 학생 수:', sum)
print('평균 학생 수:', avg)
29_튜플과 for문(2)
for문을 이용한 조회
- for문과 if문을 이용해서 과락 과목 출력하기
# 과락 과목 출력
minScore = 60
scores = (
('국어', 58),
('영어', 77),
('수학', 89),
('과학', 99),
('국사', 50)
)
for item in scores:
if item[1] < minScore: # score tuple아이템 안의 두번째 값(점수)이 minScore보다 작다면
print('과락 과목: {}. 점수: {}'.format(item[0], item[1]))
print('-'*30)
for subject, score in scores:
if score < minScore: # 내부에 있는 tuple로 된 item 하나가 내려오고 그 안의 두번째 값을 score 변수에 대입하고, 그 score와 minScore 비교
print('과락 과목: {}. 점수: {}'.format(subject, score))
print('-'*30)
for subject, score in scores:
if score >= minScore: continue # 바로 위 반복문과 비슷하지만, 이건 반대로 minScore보다 크다면 다음 반복문으로 넘어가라라고 지정
print('과락 과목: {}. 점수: {}'.format(subject, score))
# 학급 학생 수가 가장 작은 학급과 가장 많은 학급 출력
'''
1학급: 18 | 2학급: 19 | 3학급: 23 | 4학급: 21 | 5학급: 20 | 6학급: 22 | 7학급: 17
'''
studentCnts = (1,18),(2,19),(3,23),(4,21),(5,20),(6,22),(7,17)
minClassNo = 0; maxClassNo = 0 # 학급 번호 저장할 변수
minCnt = 0; maxCnt = 0 # 학생 수를 저장할 변수
for classNo, cnt in studentCnts:
if minCnt == 0 or minCnt > cnt: # minCnt == 0: 시작을 해야하니까 0 / minCnt > cnt: 이미 내려와 있던 값이 새로 내려온 cnt보다 큰 경우(=이미 내려와있던 값은 최저값이 아니게 된다)
minClassNo = classNo # 일단 첫번째 tuple item이 저장되는데, 두번째 부턴, 위의 조건이 성립한다면(새로 내려온 cnt가 더 작다면), 그 새 cnt값을 min 변수에 할당
minCnt = cnt # 그렇게 반복문이 진행되면서 그 시점 기준으로 저장되어 있는 학생 수 값(minCnt)과 내려오는 cnt 값 중 더 작은 값을 변수에 할당
# 반복문이 다 돌면, 가장 작은 학생 수 값(최저 값)과 학급 번호가 min 변수에 저장되어 있겠다.
if maxCnt < cnt: # 최초엔 maxCnt=0이니, 첫 index값 cnt(1, 18)이 max변수에 저장되고, 이후 새로운 cnt들이 내려오면서, max변수에 저장된 값과 비교되며
maxClassNo = classNo # 더 큰 것을 max변수에 계속해서 저장해 나간다. 그럼 마지막엔 가장 큰 값이 저장되어 있을 테니 가장 큰 학생 수/학급이 된다.
maxCnt = cnt
print('학생 수가 가장 적은 학급: {}학급, {}명'.format(minClassNo, minCnt))
print('학생 수가 가장 많은 학급: {}학급, {}명'.format(maxClassNo, maxCnt))
30_튜플과 while문(1)
while문을 이용한 조회
- while문을 이용하면 다양한 방법으로 아이템 조회가 가능하다.
cars = ('그랜저','소나타','말리부','카니발','쏘렌토')
n = 0
while n < len(cars):
print(cars[n])
n += 1
print('-'*30)
n = 0
flag = True
while flag:
print(cars[n])
n += 1
if n == len(cars):
flag = False
print('-'*30)
n = 0
while True:
print(cars[n])
n += 1
if n == len(cars):
break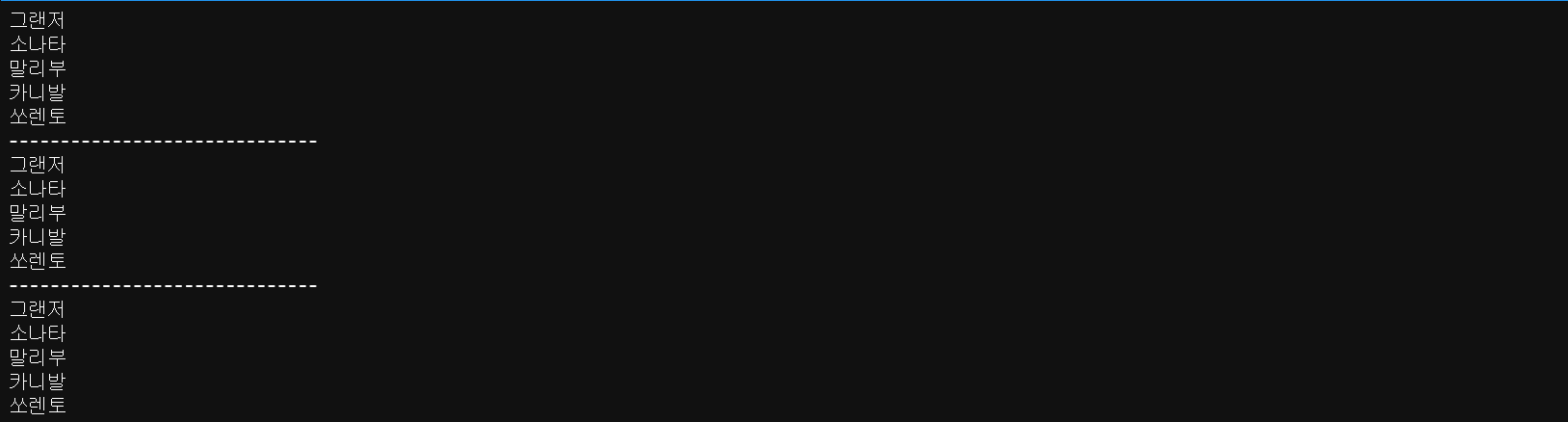
students = (1,18),(2,19),(3,23),(4,21),(5,20),(6,22),(7,17)
n=0
while n < len(students):
print('{}학급 학생수: {}'.format(students[n][0], students[n][1]))
n += 1
# 학급별 학생 수와 전체 학생 수 그리고 평규 학생 수 출력
students = (1,18),(2,19),(3,23),(4,21),(5,20),(6,22),(7,17)
sum = 0
avg = 0
n = 0
while n < len(students):
classNo = students[n][0]
cnt = students[n][1]
print('{}학급 학생수: {}'.format(classNo, cnt))
sum += cnt
n += 1
avg = sum/len(students)
print('전체 학생 수:', sum)
print('평균 학생 수:', avg)
31_튜플과 while문(1)
while문을 이용한 조회
- while문과 if문을 이용해서 과락 과목 출력하기
# 과락 과목 출력
minScore = 60
scores = (
('국어', 58),
('영어', 77),
('수학', 89),
('과학', 99),
('국사', 50)
)
n = 0
while n < len(scores):
if scores[n][1] < minScore:
print('과락 과목: {}, 점수: {}'.format(scores[n][0], scores[n][1]))
n += 1
print('-'*30)
n=0
while n < len(scores):
if scores[n][1] > minScore:
n += 1
continue
print('과락 과목: {}, 점수: {}'.format(scores[n][0], scores[n][1]))
n += 1
# 학급 학생 수가 가장 작은 학급과 가장 많은 학급 출력
'''
1학급: 18 | 2학급: 19 | 3학급: 23 | 4학급: 21 | 5학급: 20 | 6학급: 22 | 7학급: 17
'''
studentCnts = (1,18),(2,19),(3,23),(4,21),(5,20),(6,22),(7,17)
minClassNo = 0; maxClassNo = 0 # 학급 번호 저장할 변수
minCnt = 0; maxCnt = 0 # 학생 수를 저장할 변수
n = 0
while n < len(studentCnts):
if minCnt == 0 or minCnt > studentCnts[n][1]:
minClassNo = studentCnts[n][0]
minCnt = studentCnts[n][1]
if maxCnt < studentCnts[n][1]:
maxClassNo = studentCnts[n][0]
maxCnt = studentCnts[n][1]
n += 1
print('학생 수가 가장 적은 학급: {}학급, {}명'.format(minClassNo, minCnt))
print('학생 수가 가장 많은 학급: {}학급, {}명'.format(maxClassNo, maxCnt))
딕셔너리
32_딕셔너리
딕셔너리(Dictionary)란?
- 키(key)와 값(value)를 이용해서 자료를 관리한다.
- 's1':'홍길동', 's2':'박찬호', 's3':'이용규', ...
- 키 s1에 해댱되는 값은 '홍길동', 키 s2에 해당되는 값은 '박찬호' 등
- key는 유일한, 어떤 데이터를 구분하기 위한 유일한 값이어야 하기에, 중복 되면 안된다.
- 값은 중복이 있어도 된다.
딕셔너리 선언
- '{}'를 이용해서 선언하고, '키:값'의 형태로 아이템을 정의한다.
- key와 value에는 숫자, 문자(열), 논리형 뿐만 아니라 컨테이너 자료형도 올 수 있다.
- 단, key에 immutable 값은 올 수 있지만, mutable 값은 올 수 없다.
- 변경 될 수 있는 값은 key 값으로 올 수 없다.
- 자료구조를 예로 들어, 리스트는 변경 가능하니 딕셔너리의 key값으로 올 수 없다; 반대로 튜플은 올 수 있다
- value는 모든 값을 취할 수 있다
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박승철', 's5':'김지훈'}
- 's5':'김지훈' --> 아이템(요소)students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박승철', 's5':'김지훈'}
memInfo = {'이름':'홍길동', '학년':3, '취미':['농구', '게임']} # 숫자, 컨테이너도 올 수 있음
stduent1 = {'이름':'홍길동', '학년':3}
stduent2 = {'이름':'박찬호', '학년':2}
stduent3 = {'이름':'이용규', '학년':1}
studentInfo = {1:stduent1, 2:stduent2, 3:stduent3} # key값에 숫자도 올 수 있다; 학생 한명한명의 딕셔너리를 값으로 받았다memInfo = {'이름':'홍길동', '학년':3, '취미':['농구', '게임']}
print(memInfo)
33_딕셔너리 조회
딕셔너리 조회
- 딕셔너리는 키(key)를 이용해서 값(value)을 조회한다.
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박승철', 's5':'김지훈'}
print(students['s1'])
print(students['s5'])
students2 = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':['박승철','김지훈']}
print(students2['s4'][0])
print(students2['s4'][1])
- 존재하지 않는 키를 이용한 조회 시 에러(error)가 발생한다.
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박승철', 's5':'김지훈'}
print(students['s1'])
print(students['s6'])
get()을 이용한 조회
- get(key)를 이용해서 값(value)을 조회할 수 있다.
- get()은 key가 없어도 에러가 발생하지 않는다.
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박승철', 's5':'김지훈'}
print(students.get('s5'))
print(students.get('s6')) # 에러 발생 없이, None이 출력됨
34_딕셔너리 추가
딕셔너리 추가
- '딕셔너리이름[키(key)] = 값(value)' 형태로 아이템을 추가한다.
myInfo = {} # 빈 딕셔너리
myInfo['이름'] = '박경진' # key = 값 추가
myInfo['전공'] = 'computer'
myInfo['메일'] = 'abc@abc.com'
myInfo['학년'] = 3
myInfo['취미'] = ['요리', '여행']
print(myInfo)
- 추가하려는 키가 이미 있다면 기존 값이 변경된다.
print(myInfo)
myInfo['메일'] = 'gyeongjin@hello.com'
print(myInfo) # 메일의 값 변경됨
# 0부터 10까지의 각갂의 정수에 대한 팩토리얼을 딕셔너리에 추가
factorialDic = {} # 빅 딕셔너리
for i in range(11): # 0~10까지 반복
if i == 0: # i가 0일 땐
factorialDic[i] = 1 # 팩토리얼[0]의 값은 1로 하자
else: # 이제 i가 1이 되었으니 이 반복문만 실행 될 것이다
for j in range(1, (i+1)): # 1에서부터 본인 자신까지 반복
factorialDic[i] = factorialDic[i-1] * j # 본인의 key값에 전에 해당되는 아이템을 곱한다
# 0:1 , 1:1, 2:2, 3:6, 4:24 <-- 2 = 2x1, 6=3x2, 24=4x6
print(factorialDic) # 팩토리얼의 원리를 이용한 것; 어떤 수/자기자신의 팩토리얼은 결국 전 숫자의 팩토리얼에 자가자신을 곱한 것
35_딕셔너리 수정
딕셔너리 수정
- '디셔너리이름[키(key)] = 값(value)' 형태로 아이템을 수정한다.
myInfo = {} # 빈 딕셔너리
myInfo['이름'] = '박경진'
myInfo['전공'] = 'computer'
myInfo['메일'] = 'abc@abc.com'
myInfo['학년'] = 3
myInfo['취미'] = ['요리', '여행']
print(myInfo)
myInfo['전공'] = 'sports'
myInfo['학년'] = '4'
print(myInfo)
# 학생의 시험 점수가 60점 미만이면 'F(재시험)'으로 값을 변경해라
scores = {'kor':88, 'eng':55, 'mat':85, 'sci':57, 'his':82}
print(scores)
minScore = 60
fStr = 'F(재시험)'
if scores['kor'] < minScore: scores['kor'] = fStr
if scores['eng'] < minScore: scores['eng'] = fStr
if scores['mat'] < minScore: scores['mat'] = fStr
if scores['sci'] < minScore: scores['sci'] = fStr
if scores['his'] < minScore: scores['his'] = fStr
print(scores)
# 하루에 몸무게(kg)와 신장(m)이 각각 -0.3kg, +0.001m씩 변한다고 할 때, 30일 후의 몸무게와 신장의 값을 저장하고 BMI 값도 출력하는 프로그램 만들기
myBody = {'이름':'gildong', '몸무게':83.0, '신장':1.8}
myBMI = myBody['몸무게'] / (myBody['신장'] ** 2)
print('my body:', myBody)
print('my BMI:', myBMI)
# 30일 이후 계산
date = 0
while True:
date += 1
# 몸무게 변화
myBody['몸무게'] = round((myBody['몸무게'] - 0.3), 2)
# print('몸무게:', myBody['몸무게'])
# 신장 변화
myBody['신장'] = round((myBody['신장'] + 0.001), 3)
# print('신장:', myBody['신장'])
myBMI = round((myBody['몸무게'] / (myBody['신장'] ** 2)), 2)
# print('BMI:', myBMI)
if date >= 30: # 일 수가 30일에 도달하면 반복문 중단; 0부터 시작하니까 29일까지가 일 수로 30일이다
break
print('30일 후 몸무게:', myBody['몸무게'])
print('30일 후 신장:', myBody['신장'])
print('30일 후 BMI:', myBMI) 
36_key()와 values()
keys()와 values()
- 전체 키(key)와 값(value)를 조회할 수 있다.
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print(memInfo.keys()) # key만 가져온다
print(type(memInfo.keys()))
print(memInfo.values()) # value만 가져온다
print(type(memInfo.values()))
print(memInfo.items()) # key와 value 모두 가져온다; list안에 tuple로 저장되어 있는 형태로 반환
print(type(memInfo.items()))
- 리스트(list())로 변환하기
- 리스트로 변환해서 완벽한 리스트로 사용하겠다면 변환; 리스트가 더 편하다면
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
ks = memInfo.keys()
ks = list(ks)
print(ks)
print(type(ks))
vs = memInfo.values()
vs = list(vs)
print(vs)
print(type(vs))
items = memInfo.items()
items = list(items)
print(items)
print(type(items))
- for문을 이용한 조회
- dictionary에서 key만 뽑아낼 수 있다면, 그 key로 values를 조회할 수도 있다.
for key in ks:
print(key)
for idx, key in enumerate(ks):
print(idx, key)
print('-'*30)
for value in vs:
print(value)
for idx, value in enumerate(vs):
print(idx, value)
print('-'*30)
for item in items:
print(item)
for idx, item in enumerate(items):
print(idx, item)
for key in memInfo.keys(): # 'dict_keys' --> 리스트는 아니지만 반복성이 있는 객체이다
print(f'{key}:{memInfo[key]}') # key 이름 : value 값
# 짧은 코드이지만 이렇게 딕셔너리의 모든 키와 값을 조회 할 수 있다
# 학생 시험 점수가 60점 미만이면 'F(재시험)'으로 값을 변경하는 코드를 keys()를 이용해서 작성해라
scores = {'kor':88, 'eng':55, 'mat':85, 'sci':57, 'his':82}
print(scores)
minScore = 60
fStr = 'F(재시험)'
fDic = {} # 빅 딕셔너리; F학점 과목만 따로 모아놓을 딕셔너리
# for key in scores: <-- 그냥 이렇게 해도 됨
for key in scores.keys(): # key를 하나 뽑고
if scores[key] < minScore: # 만약 내려온 key의 value 값이 60점 미만이면
scores[key] = fStr # 그 key의 value 값을 'F(재시험)'으로 바꾸고
fDic[key] = fStr # 해당 key값에 'F(재시험)' 값을 가지고 fDic 딕셔너리에 추가
print('scores:', scores)
print('fDic:', fDic)
37_딕셔너리 삭제
del
- del과 key를 이용한 item 삭제
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print(memInfo)
del memInfo['메일']
print(memInfo)
del memInfo['취미']
print(memInfo)
pop()
- pop()과 key를 이용한 item 삭제
- pop()는 함수여서 데이터를 반환해 줄 수 있다. 반환을 하면 삭제된 값이 나온다.
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print(memInfo)
returnValue = memInfo.pop('이름') # pop() 안에 key값을 넣어주면 삭제
print(memInfo)
print('returnValue:', returnValue)
print(type(returnValue))
# 딕셔너리에 저장된 점수 중 최저 및 최고 점수를 삭제하는 프로그래 만들기
scores = {'score1':8.9, 'score2':8.1, 'score3':8.5, 'score4':9.8, 'score5':8.8}
minScore = 10; minScoreKey = '' # minScore에일단 10점을 준다; 그리고 키 값을 저장할 변수
maxScore = 0; maxScoreKey = '' # maxSCore는 일단 0점; 그리고 키 값을 저장할 변수
for key in scores.keys(): # key 하나씩
if scores[key] < minScore: # 모든 점수가 10점보다 아래이니, 일단 첫 key 값이 min 변수에 저장된다; 그리고 내려오는 value 값이 minSCore보다 작다면
minScore = scores[key] # 즉, 더 작은 점수의 값이 내려오면, 그 값이 이젠 min 변수에 저장된다
minScoreKey = key # key도 저장된다
if scores[key] > maxScore: # 모든 점수가 0점보다 크니, 일단 첫 key 값이 max 변수에 저장; 그리고 내려 오는 다른 점수 값과 비교되며,
maxScore = scores[key] # 새로 내려온 값이 더 높으면 max 변수에 저장; 이렇게 반복되며 가장 큰 점수 값이 저장 될 것이다 마지막엔
maxScoreKey = key # key도 저장
del scores[minScoreKey] # minScore key값으로 가장 낮은 점수를 조회하여 삭제
del scores[maxScoreKey] # maxScore key값으로 가장 높은 점수를 조회하여 삭제
print(scores)
38_딕셔너리 유용한 기능
in, not in
- 키(key) 존재 유/무 판단을 한다.
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print('이름' in memInfo) # key가 있다면 True
print('학년' in memInfo)
print('name' not in memInfo) # not in이기 때문에 없다면 True
print('hobby' not in memInfo)
len()
- 딕셔너리 길이(아이템 개수)를 알 수 있다.
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print(len(memInfo))
clear()
- 모든 아이템을 삭제한다.
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
print(memInfo)
memInfo.clear() # 모든 아이템 삭제
print(memInfo)
# 개인 정보에서 지우고자 하는 정보가 있다면 삭제하는 코드를 작성해보자
memInfo = {'이름':'홍길동', '메일':'gildong@ab.com', '학년':3, '취미':['농구', '게임']}
deleteItems = ['이름', '메일']
for item in deleteItems: # 삭제 항목이 하나씩 내려오고
if (item in memInfo): # 만약 개인정보에 그 항목/key가 있다면
del memInfo[item] # 그 key값으로 개인정보에서 조회해서 삭제
print(memInfo)
