
문제를 처음 본 순간 떠올린 생각
1.알고리즘 수업 시간에 배운 근사문자열매칭과 거리함수겠구나
2.DP로 해결할 수 있는 문제겠구나
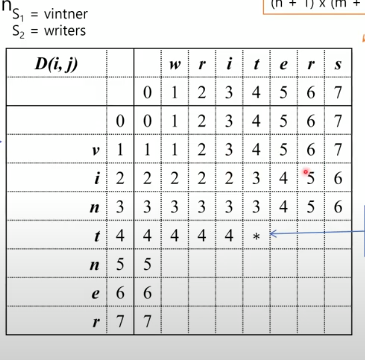
근사문자열매칭을 이해하는 데에는 화려한 미사여구 따위는 필요없이, 이 표 하나로 충분하다고 생각한다.
문자열을 비교해나가며 cost가 증가하는 조건은 3가지가 있다.
1.삽입: 문자 하나를 추가.
2.삭제: 문자 하나를 삭제.
3.교체: 문자 하나를 다른 문자로 교체.
우선 (N+1)*(M+1)의 테이블을 그린 뒤, D(1,0)~D(1,N)과 D(0,1)~D(0,M)을 각각 1씩 증가시키며 표시한다.
(아무것도 비교할 수가 없을 때에는 해당 문자열의 문자를 하나씩 추가하면 되므로)
이후 테이블을 채워나갈 때에는 다음의 2가지 경우를 확인한다.
case1) 현재 비교하는 두 수가 같은가?
-이 경우에는 D(i,j-1)과 D(i-1,j)과 D(i-1,j-1) 세 가지 index의 값을 확인 한 뒤, 가장 작은 값으로 현재의 index값을 업데이트한다.
Why?
D(i,j)를 위 테이블에서의 D(4,4)라고 생각하고 경우를 나눠보자.
i) D(i,j-1)와 비교하는 경우
s2은 현재 "wri" 까지 비교된 상태이고, s1는 "vint"까지 비교된 상태이다.
이 때, s1에서 t를 추가한다면 현재 상태에서 마지막 index가 't'로 동일하므로, cost가 발생하지 않는다.
ii)D(i-1,j)와 비교하는 경우
s2은 현재 "writ" 까지 비교된 상태이고, s1는 "vin"까지 비교된 상태이다.
이 때, s2에서 t를 추가한다면 현재 상태에서 마지막 index가 't'로 동일하므로, cost가 발생하지 않는다.
iii)D(i-1,j-1)와 비교하는 경우
s2은 현재 "wri" 까지 비교된 상태이고, s1는 "vin"까지 비교된 상태이다.
이 때, s1과 s2에 동일한 문자 't'를 마지막 index로 추가하므로, cost가 발생하지 않는다.
case2) 현재 비교하는 두 수가 다른가?
-이 경우에는 D(i,j-1)과 D(i-1,j)과 D(i-1,j-1) 세 가지 index의 값을 확인 한 뒤, 가장 작은 값+1로 현재의 index값을 업데이트한다.
Why?
D(i,j)를 위 테이블에서의 D(4,2)라고 생각하고 경우를 나눠보자.
i) D(i,j-1)와 비교하는 경우
s2은 현재 "writ" 까지 비교된 상태이고, s1는 "v"까지 비교된 상태이다.
해당 index의 cost는 4이고, s1에서 i를 추가하는 경우 cost는 1 증가해 현재 index에서의 총 cost는 5가 된다.
ii)D(i-1,j)와 비교하는 경우
s2은 현재 "wri" 까지 비교된 상태이고, s1는 "vi"까지 비교된 상태이다.
해당 index의 cost는 2이고, s2에서 t를 추가하는 경우 cost는 1 증가해 현재 index에서의 총 cost는 3이 된다.
iii)D(i-1,j-1)와 비교하는 경우
s2은 현재 "wri" 까지 비교된 상태이고, s1는 "v"까지 비교된 상태이다.
해당 index의 cost는 3이고, s1에서 'i'를 추가하는 경우 case1)에 해당하므로 cost가 증가하지 않는다. 이후 s2에서 't'를 추가하는 경우, cost가 1 증가해 현재 index에서의 총 cost는 4가 된다.
우리는 현재 '최소 비용'을 찾고 있고, 이전의 상태는 중요하지 않다.
우리가 찾고자 하는 것은 '현재 상태를 만들기 위한 최소 비용' 이므로, 세 가지 경우 중 가장 작은 최소 비용을 선택한다.
위와 같은 알고리즘으로 테이블을 채워나가다보면, D((N+1),(M+1))에서 두 문자열간의 최소 편집 비용을 구할 수 있다.
code
#include<iostream> #include<vector> using namespace std; int min(int a,int b,int c) { int temp; temp = a; if (temp > b) temp = b; if (temp > c) temp = c; return temp; } int main() { string A; string B; int n = 0; cin >> A; cin >> B; int collen, lowlen; collen = A.length()+1; //cause case = col[0][0] , length+1 lowlen = B.length()+1; vector<vector<int>>col(collen,vector<int>(lowlen,0)); //create 2D vector => col[collen][lowlen] for (int i = 0; i < lowlen; i++) { col[0][i] = n; n++; } n = 0; for (int i = 0; i < collen; i++) { col[i][0] = n; n++; } for (int i = 1; i < lowlen; i++) { for (int j = 1; j < collen; j++) { int compare; if (A[j-1] == B[i-1]) compare = 0; else compare = 1; col[j][i] = min(col[j - 1][i - 1] + compare, col[j - 1][i] + 1, col[j][i - 1]+1); } } cout << col[collen-1][lowlen-1]; }
알고리즘 분류
다이나믹 프로그래밍
