2022-2 운영체제 과목을 수강하면서 작성한 자료입니다.
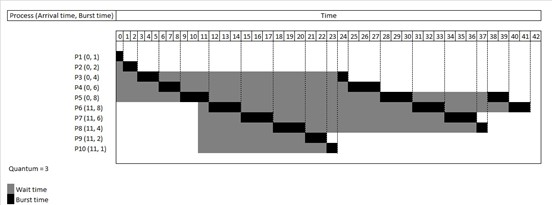
본 과제에서는 Linux의 Round Robin 스케줄링 환경에서, time-slice를 1ms, 10ms, 100ms 로 변화시켜가며 time-slice에 따른 문맥전환(Context switching) 오버헤드를 측정하고 분석한다.
1. 개발 환경
VirtualBox 6.0.4, Ubuntu 18.04.2, linux-4.20.11
2. 과제 개요 및 Round Robin 스케줄링에서 time-slice의 영향 설명
Image source: https://en.wikipedia.org/wiki/Round-robin_scheduling본 과제에서는 리눅스의 Round Robin(RR) 프로세스 스케줄링 환경에서, time-slice를 1ms, 10ms, 100ms 로 변경시키며 이에 따른 Context switching 오버헤드를 측정하고 분석한다. Round Robin은 프로세스 스케줄러가 사용하는 대표적인 알고리즘 중 하나로, 각 process는 time slice에 따라 일정한 시간을 부여받고 그때까지 완료되지 않으면 작업이 중단된다. Round Robin 스케줄링은 비교적 간단하고 구현이 쉬우며 starvation이 일어나지 않는다는 장점이 있다. 여기에서는 time-slice의 역할이 큰데, time-slice가 필요 이상으로 작을 경우 process간의 작업을 자주 전환하기 때문에 Context switching이 많이 발생하며 상당한 오버헤드를 일으킨다. 반대로 time-slice가 클 경우, response time이 느려지게 되고 Interactive process를 만족시킬 수 없다. 따라서 Round Robin에서 적절한 time-slice를 설정하는 것은 매우 중요한 과제이다.
3. time-slice의 변화에 따른 성능을 관찰한 표 및 결과 분석
과제 수행에 있어서 프로세스 개수는 2개, 수행 시간은 10초로 설정했다. 아래는 실행 결과 터미널 스냅샷과 time slice별 성능 변화를 정리한 표이다.
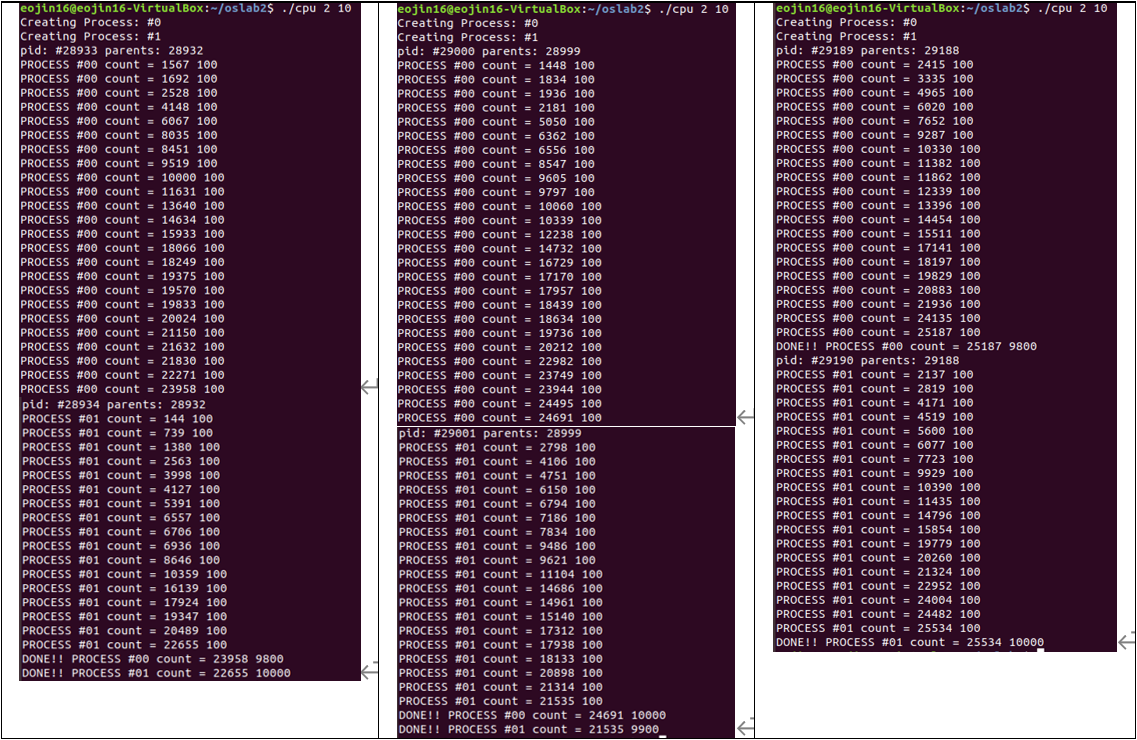
[표 1] process, time slice별 # of calc, time| RR time slice | 1ms # of calc. | 1ms Time (s) | 10ms # of calc. | 10ms Time (s) | 100ms # of calc. | 100ms Time (s) |
|---|---|---|---|---|---|---|
| Process #0 | 23958 | 09.800 | 24691 | 10.000 | 25187 | 09.800 |
| Process #1 | 22655 | 10.000 | 21535 | 09.900 | 25534 | 10.000 |
| Total | 46613 | 19.800 | 46226 | 19.900 | 50721 | 19.800 |
[표 2] baseline을 사용한 time slice에 따른 성능 변화 비교| RR time slice | 1ms | 10ms | 100ms |
|---|---|---|---|
| Calculations per minute | 2354.19191919 | 2322.91457286 | 2561.66666667 |
| Baseline=1ms | 100.00% | 98.67% | 108.81% |
| Baseline=10ms | 101.35% | 100.00% | 110.28% |
| Baseline=100ms | 91.90% | 90.68% | 100.00% |
[그래프 1] time slice에 따른 calculations per minute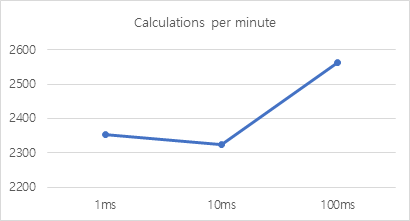
표를 이용해 분석한 결과 전체적인 관점에서 time-slice가 1ms, 10ms, 100ms로 커질수록 성능이 좋아지는 경향이 있다는 것을 알 수 있었다. 특히 time slice가 제일 작은 1ms일 때와 제일 큰 100ms일 때를 기준으로 비교해 보면 최대 약 8.81%의 차이를 보였다. 본 실험을 통해 Round Robin scheduling에서 time-slice가 작을 경우 (context switching에 따른 오버헤드가 커지기 때문에) 수행 시간이 늘어난다는 것을 눈으로 확인할 수 있었다. 그러나 time-slice를 10ms로 설정했을 때, Process #1에서 calculation 숫자가 21535로 다소 작아지면서 평균 성능에 있어서 time slice기준이 1ms일 때보다 오히려 성능이 떨어지는 결과가 있었다. Process #0을 기준으로는 예상과 비슷한, time slice가 커질수록 성능이 좋아지는 결과가 나왔기 때문에 이것은 프로세스 수행 및 계산 과정에서 다소의 오차가 발생한 것으로 생각된다.
4. 작성한 모든 소스코드 및 작업 내용에 대한 설명
A. cpu.c 유저 어플리케이션 구현
#include <sched.h>
#include <stdint.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <time.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/shm.h>
#define ROW (100)
#define COL ROW
#define SLICE_TIME 10000
// gcc -pthread -o cpu cpu.c
struct sched_attr {
uint32_t size; /* Size of this structure */
uint32_t sched_policy; /* Policy (SCHED_*) */
uint64_t sched_flags; /* Flags */
int32_t sched_nice; /* Nice value (SCHED_OTHER, SCHED_BATCH) */
uint32_t sched_priority; /* Static priority (SCHED_FIFO, SCHED_RR) */
/* Remaining fields are for SCHED_DEADLINE */
uint64_t sched_runtime;
uint64_t sched_deadline;
uint64_t sched_period;
};
static int sched_setattr(pid_t pid, const struct sched_attr *attr, unsigned int flags) {
return syscall(SYS_sched_setattr, pid, attr, flags);
}
int main(int argc, char* argv[]){
int r;
int i, j, k;
int num_of_processes, time_to_execute;
struct timespec begin, end;
int matrixA[ROW][COL];
int matrixB[ROW][COL];
int matrixC[ROW][COL];
pid_t process[10000];
int count;
int final_count;
long final_time;
long print_final_time;
int result;
int childStatus;
struct sched_attr attr;
memset(&attr, 0, sizeof(attr)); //
attr.size = sizeof(struct sched_attr);
attr.sched_priority = 10;
attr.sched_policy = SCHED_RR; // SCHED_FIFO
// input argument error
if (argc != 3) {
fprintf( stderr, "Usage: %s <num of processes> <time to execute>\n", argv[0]);
exit(1);
}
num_of_processes = atoi(argv[1]);
time_to_execute = atoi(argv[2]);
for(r = 0; r < num_of_processes; r++) {
printf( "Creating Process: #%d \n", r);
}
for(r = 0; r < num_of_processes; r++) {
result = sched_setattr(getpid(), &attr, 0);
if (result == -1) {
perror("Error: calling sched_setattr.\n");
}
process[r] = fork();
//printf( "~~Creating Process: #%d \n", r);
clock_gettime(CLOCK_MONOTONIC, &begin);
if(process[r] == 0) {
printf( "pid: #%ld parents: %ld \n", (long)getpid(), (long)getppid());
for(i = 0; i < ROW; i++) {
for(j = 0; j < COL; j++) {
for(k = 0; k < COL; k++) {
matrixC[i][j] += matrixA[i][k] * matrixB[k][j];
count++;
clock_gettime(CLOCK_MONOTONIC, &end);
final_time = ((end.tv_sec - begin.tv_sec) + (end.tv_nsec - begin.tv_nsec));
if ( (final_time%SLICE_TIME)==0 && final_time <= time_to_execute*100000) {
printf("PROCESS #%02d count = %d %d\n", r, count, SLICE_TIME/100);
final_count = count;
print_final_time = final_time;
}
}
}
}
//syscall(SYS_sched_info_depart, pid, attr, flags);
printf("DONE!! PROCESS #%02d count = %02d %02ld \n", r, final_count, print_final_time/100);
exit(100+r);
}
}
for(r = 0; r < num_of_processes; r++) {
pid_t terminatedChild = waitpid(process[r], NULL, 0);
}
return 0;
}
cpu.c의 구현 사항은 다음과 같다. 사용자는 이 프로그램을 실행하면서 적절한 인자를 2개를 입력해 주어야 한다. 따라서 입력받은 인자가 3개가 아니면 에러 메시지를 띄우며 올바른 사용 방법을 출력하도록 했다. 사용자로부터 두 숫자를 입력받으면 이들은 각각 num_of_processes, time_to_execute에 정수로 저장되게 된다. 이제 이들을 가지고 프로세스를 생성해야 한다. 먼저, num_of_process회 반복하는 반복문을 통해 입력한 횟수만큼 프로세스가 생성됨을 알려주는 문장들을 출력했다. 수행 시간 측정을 위해 clock_gettime 또한 미리 실행했다. 이것으로 시작 시간을 구해 미리 선언해 두었던 timespec 구조체의 begin변수에 넣어주었다. num_of_process회 반복하는 두 번째 반복문 내부에는 fork를 사용해 새로운 프로세스를 생성했다. 새 프로세스가 생성되면 그것의 pid와 ppid(부모 프로세스의 id)를 출력했다. 프로세스 생성 후에는 주어진 코드를 이용해 행렬 연산을 진행했다. 행렬 연산 1회가 끝나면 count 변수를 1 증가시키고 clock_gettime을 이용해 종료 시간을 구해 timespec 구조체의 end 변수에 넣어 주었다. end – begin을 통해 수행 시간을 구했고 이것을 final_time변수에 저장했다. 총 수행 시간을 넘지 않는 조건이라면 100ms마다 프로세스 번호, 연산 횟수, time slice 기준(100ms)를 출력했다. 연산이 모두 끝나면 DONE!!이라는 메시지와 함께 프로세스 번호, 최종 연산 횟수, 최종 연산 시간을 출력했다. 프로세스 생성 과정이 모두 완료되면 마지막으로 waitpid를 이용해 자식 프로세스들의 프로세스의 종료 상태가 리턴되게 했다.
B. 스케줄링 클래스를 RT-RR로 변경
스케줄링 클래스의 변경은 cpu.c 유저 어플리케이션 내부에서 수행했다. 이를 위해 sched_attr 구조체와 sched_setattr 함수를 만들었다. sched_attr 구조체를 선언한 후 sched_policy 등 필요한 구조체 변수를 삽입했으며 sched_setattr 함수를 선언하고 SYS_sched_setattr을 호출하는 syscall을 리턴하게 했다. main 함수에서는 attr이라는 이름의 sched_attr 타입 구조체를 생성했고 attr의 sched_policy를 SCHED_RR로 설정했다. 마지막으로 sched_setattr 함수를 호출하면서 attr 구조체를 파라미터로 넘겨주어 스케줄링 클래스가 변경되도록 했다.
C. 커널 레벨에서 CPU Burst 측정
static inline void sched_info_depart(struct rq *rq, struct task_struct *t)
{
unsigned long long delta = rq_clock(rq) - t->sched_info.last_arrival;
rq_sched_info_depart(rq, delta);
if (t->state == TASK_RUNNING)
sched_info_queued(rq, t);
// 수정한 부분 시작
if (t->rt_priority == 10)
{
printk("[Pid: %d], CPUburst: %lld, rt_priority:%u \n", t->pid, delta, t->rt_priority);
}
// 수정한 부분 끝커널 레벨에서의 CPU Burst 측정을 위해 B의 구현에 사용했던 코드를 일부 이용했다. B의 attr 구조체의 내부에 sched_priority 변수를 구현했고 이것을 10으로 설정하여 커널에서 priority = 10을 갖는 프로세스에 대해서만 출력되도록 했다. 커널 레벨에서는, sched_info_depart를 변경하기 위해 stats.h를 수정했다. (stats.h파일은 /usr/src/linux-4.20.11/kernel/sched/stats.h의 경로에 존재한다.) if문과 printk 함수를 이용해 priority가 10이 되는 경우의 pid, CPU burst, priority를 출력하도록 하는 코드를 sched_info_depart 내부에 추가했다.
5. 과제 수행 시의 문제점과 해결 과정 또는 의문 사항
A. 행렬 연산 함수의 구현에 관한 문제
과제 수행 초기에는 calc 함수를 main 함수 외부에 만들어서 따로 호출하는 방식을 채택했다. 그러나 이 방식으로 구현하다 보니 과제 tutorial에서 요구하는 fork 함수 대신 pthread_create를 사용하게 되었고 clock_gettime을 이용한 시간 측정에도 원인을 정확히 파악하기 힘든 오류가 발생했다. 이것을 나름대로 해결하기 위해 행렬 연산 과정을 별도의 함수 대신 main함수 내부에 삽입하는 것으로 구현을 다소 수정했다.
B. 커널 레벨에서의 측정에 관한 문제
위의 서술대로 4-B의 과정을 거쳐 dmesg에서 프로세스 id별로 정확한 cpu burst 출력을 시도했으나 dmesg의 결과에는 전혀 출력되지 않았다. 이 문제를 해결하기 위해 priority값을 바꾸어 보거나 수동으로 sched_info_depart함수를 출력하려고 하는 등 여러 방면으로 노력해 보았으나 주어진 시간 내에 이 문제는 완벽하게 해결하지 못했다. 따라서 과제 수행에 있어서 커널에서의 정밀한 시간 단위를 사용하지 못하고 터미널의 출력을 토대로 해석하게 되었다.
C. time-slice에 따른 성능에 관한 문제
time-slice를 10ms로 설정했을 때, Process #1에서 calculation 숫자가 21535로 다소 작아지면서 발생하면서 약간의 오차가 있었다. 여기에 관련한 문제도 5-B에서의 문제와 연관성이 있다고 생각한다. 시간 단위에 있어서 정확한 계산을 할 수 없었기 때문에 완벽히 정확한 결과가 나오지 못한 것으로 추측된다.
