자료구조의 이해
자료구조 : 데이터의 특징을 고려하여 저장하는 방법
스택과 큐
스택 자료구조(stack data structure): 4, 10과 같은 데이터를 저장하는 공
간, 리스트와 비슷하지만 저장 순서가 바뀌는 형태
푸시(push): 스택에 데이터를 저장하는 것
팝(pop): 데이터를 추출하는 것
스택(stack): 입력한 텍스트를 역순으로 추출하는 프로그램
파이썬에서는 리스트를 사용하여 스택을 구현합니다. 리스트라는 저장 공간을 만든 후 append( ) 함수로 데이터를 저장(push)하고 pop( ) 함수로 데이터를 추출(pop)합니다.
>>> a = [1, 2, 3, 4, 5]
>>> a.append(10)
>>> a
[1, 2, 3, 4, 5, 10]
>>> a.append(20)
>>> a
[1, 2, 3, 4, 5, 10, 20]
>>> a.pop()
20
>>> a.pop()
10<입력한 텍스트를 역순으로 추출하는 프로그램>
word = input("Input a word: ")
world_list = list(word)
print(world_list)
result = [ ]
for _ in range(len(world_list)):
result.append(world_list.pop())
print(result)
print(word[::-1])결과 : Input a word: PYTHON
['P', 'Y', 'T', 'H', 'O', 'N']
['N', 'O', 'H', 'T', 'Y', 'P']
NOHTYP
큐 : 스택과 다르게 먼저 들어간 데이터가 먼저 나오는 메모리 구조를 가지는 자료구조
>>> a = [1, 2, 3, 4, 5]
>>> a.append(10) # a = [1, 2, 3, 4, 5, 10]
>>> a.append(20) # a = [1, 2, 3, 4, 5, 10, 20]
>>> a.pop(0)
1
>>> a.pop(0)
2기본적으로 스택의 구현과 같은데, pop( ) 함수를 사용할 때 인덱스가 0번째인 값을
쓴다는 의미로 pop(0)을 사용하면 됩니다.
pop( ) 함수가 리스트의 마지막 값을 가져온다고 했을 때 pop(0)은 맨 처음 값을 가
져옵니다.
튜플과 세트
튜플 : 리스트와 같은 개념이지 만 값을 변경하는 것이 불가능한 리스트로의 자료구조
>>> t = (1, 2, 3)
>>> print(t + t , t * 2)
(1, 2, 3, 1, 2, 3) (1, 2, 3, 1, 2, 3)
>>> len(t)
3만약 튜플의 값을 변경하고자 한다면 오류가 발생합니다.
세트 : 값을 순서 없이 저장하되 중복을 불허하는 자료형
>>> s = set([1, 2, 3, 1, 2, 3]) # set() 함수를 사용하여 1, 2, 3을 세트 객체로 생성
>>> s
{1, 2, 3}세트는 튜플과 다르게 삭제나 변경이 가능합니다. 또한 세트를 지원하는 함수에는 add(), remove(), discard(), update(), clear() 등이 있습니다.
파이썬은 교집합, 합집합, 차집합 연산을 모두 지원합니다.
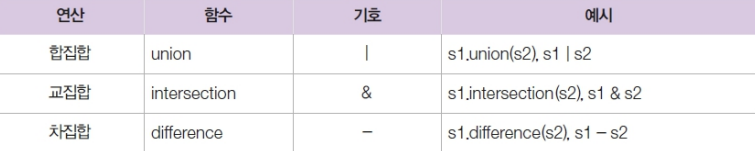
>>> s1 = set([1, 2, 3, 4, 5])
>>> s2 = set([3, 4, 5, 6 ,7])
>>>
>>> s1.union(s2) # s1과 s2의 합집합
{1, 2, 3, 4, 5, 6, 7}
>>> s1 | s2 # set([1, 2, 3, 4, 5, 6, 7])
{1, 2, 3, 4, 5, 6, 7}
>>> s1.intersection(s2) # s1과 s2의 교집합
{3, 4, 5}
>>> s1 & s2 # set([3, 4, 5])
{3, 4, 5}
>>> s1.difference(s2) # s1과 s2의 차집합
{1, 2}
>>> s1 - s2 # set([1, 2])
{1, 2}딕셔너리
파이썬에서 가장 많이 사용하는 자료구조입니다.
영어사전에서 검색을 위해 영어 단어들을 저장해 놓은 방식과 비슷하고, 영어사전에서 각 단어를 검색할 수 있도록 색인(index)을 만들어 놓고 색인을 통해 그 단어를 찾아 의미를 파악합니다.
파이썬의 딕셔너리 구조에서는 데이터의 유일한 구분자인 키(key)라는 이름으로 검색할 수 있게 하고, 실제 데이터를 값(value)이라는 이름과 쌍으로 저장하여 프로그래머가 데이터를 쉽게 찾을 수 있도록 합니다.
딕셔너리의 선언 : 중괄호 {}를 사용하여 키와 값을 쌍으로 구성
딕셔너리 변수 = {키1:값1, 키2:값2, 키3:값3, .....}특정 값을 호출하기, 재할당화 데이터 추가하기
>>> student_info = {20140012:'Sungchul', 20140059:'Jiyong’, 20140058:'Jaehong'}
>>> student_info[20140012] #특정 값을 호출하는 방법
'Sungchul'
>>> student_info[20140012] = 'Sungchul' #재활당과 데이터 추가
>>> student_info[20140012]
'Sungchul'
>>> student_info[20140039] = 'Wonchul'
>>> student_info
{20140012:'Sungchul',20140059:'Jiyong',20140058:'Jaehong',20140039:'Won
chul'}딕셔너리 함수 사용 예시
국가명과 국과 전화번호를 묶어 보여주는 코드 작성
>>> country_code = { } # 딕셔너리 생성
>>> country_code = {"America": 1, "Korea": 82, "China": 86, "Japan": 81}
>>> country_code
{'America': 1, 'Korea': 82, 'China': 86, 'Japan': 81}딕셔너리 변수 안의 키와 값을 출력하는 함수
>>> country_code.keys() # 딕셔너리의 키만 출력
dict_keys(['America', 'Korea', 'China', 'Japan'])값을 출력하기 위해서 values( ) 함수 사용
>>> country_code["German"] = 49 # 딕셔너리 추가
>>> country_code
{'America': 1, 'Korea': 82, 'China': 86, 'Japan': 81, 'German': 49}
>>> country_code.values() # 딕셔너리의 값만 출력
dict_values([1, 82, 86, 81, 49])키-값 쌍을 모두 보여주기 위해서 items( ) 함수 사용
>>> country_code.items() # 딕셔너리 데이터 출력
dict_items([('America',1),('Korea',82),('China',86),('Japan',81),
('German',49)])