지난 글에서 Point, H3 index를 통해 주변의 글들과 여러 구역의 글들을 조회하는 로직을 작성했습니다.
이번에는 여러 구역의 데이터들을 조화롭게 가져오는 방법을 고민하고, QueryDSL에서 Window Function을 통해 구현한 과정을 말씀드릴까 합니다.
조회 방법
나누어진 구역
예시를 위해 H3 index 3개에 속한 데이터가 있다고 가정하겠습니다.
편한 이해를 위해 A, B, C 구역으로 작성했습니다.
A 구역: 5개 (A1, A2, A3, A4, A5)
B 구역: 4개 (B1, B2, B3, B4)
C 구역: 5개 (C1, C2, C3, C4, C5)
해당하는 데이터들은 임의의 순서를 지니고 있습니다.
이 때, 조화로운 데이터 편향을 위해 각 구역마다 최대 3개씩의 데이터를 가져오겠습니다.
1차 조회는
A1, A2, A3, B1, B2, B3, C1, C2, C3
를 반환하여 한쪽으로 치우치지 않고 일정하게 분포된 데이터를 얻을 수 있습니다.
2차 조회는 앞선 데이터들을 제외하고
A4, A5, B4, C4, C5
를 반환할 수 있습니다.
한 구역의 데이터가 부족하다면
C 구역의 데이터가 부족하다고 가정하겠습니다.
A 구역: 5개 (A1, A2, A3, A4, A5)
B 구역: 4개 (B1, B2, B3, B4)
C 구역: 1개 (C1)
1차 조회는
A1, A2, A3, B1, B2, B3, C1, (나머지 2개를 채워야 하므로) A4, B4
가 반환됩니다.
2차 조회는
A5
만 반환됩니다.
어떤 로직을 사용해야 할 것인가?
데이터를 골고루 가져오던 중, 부족한 데이터의 수만큼 파악하여 다시 조회하는 방법은 쉽지 않을 것입니다. 조회 쿼리가 여러 번 날아갈 수도 있고, 1차에서 조회되지 않은 데이터들을 제외한 나머지 데이터를 대상으로 2차 조회가 이루어져야 하니 굉장히 복잡한 로직이 구성될 수 있습니다.
그러니 우리는 특정 구역의 데이터를 골고루 N개 가져오는 것이 아닌, 각 구역의 데이터를 1개씩 여러 번 조회하는 방식을 생각해봅시다.
각 구역의 데이터에게 임의의 순서를 부여
이해를 돕기 위해 데이터들은 {구역명}{임의의 순서명}으로 작성했습니다.
이처럼 조회 시 각 데이터마다 구역을 기준으로 한 임의의 순서를 제공하고, 해당 순서를 기준으로 정렬하여 조회한다면 부족한 데이터 수만큼 파악한다거나, 앞선 조회가 어디까지 이루어졌는지를 따로 구현하지 않아도 됩니다.
앞선 데이터들을 임의의 순서를 기준으로 정리해보겠습니다.
전체 데이터는
A1, B1, C1, A2, B2, A3, B3, A4, B4, A5
가 될 것입니다.
이 때 9개의 데이터를 반환하는 1차 조회는
A1, B1, C1, A2, B2, A3, B3, A4, B4
일 것입니다.
2차 조회는 10번째 데이터부터이므로
A5
가 조회될 것입니다.
즉, 특정 구역 기준으로 순서를 마련하고, 해당 순서값을 기준으로 하나씩 가져오면 충분히 구현할 수 있겠습니다.
쿼리로는 어떻게 표현해야 할까
Window Function
- 특정 데이터를 기준으로
- 임의의 순서를 부여
하는 방법으로는 Window Function이 있겠습니다.
그 중 row_number()를 이용하면 손쉽게 임의의 순서를 부여할 수 있겠습니다.
row_number()
row_number()는 지정한 필드를 기반으로 한 순번을 정하는 Window Function입니다.
위의 예시를 사용하여 예를 들자면
SELECT *, ROW_NUMBER() OVER(PARTITION BY 구역) AS rn ORDER BY rn;으로 표현할 수 있겠습니다.
OVER는 앞선 함수가 Window Function으로 동작함을 나타냅니다.
PARTITION BY는 해당 Window Function이 어떠한 column을 기준으로 동작할 것인지를 나타냅니다.
즉, 위의 쿼리는 구역 필드를 기준으로 순번을 정해주는 형태입니다.
또한 ORDER BY를 사용하여, 해당 순번을 통해 정렬하여 값을 조회할 수 있습니다.
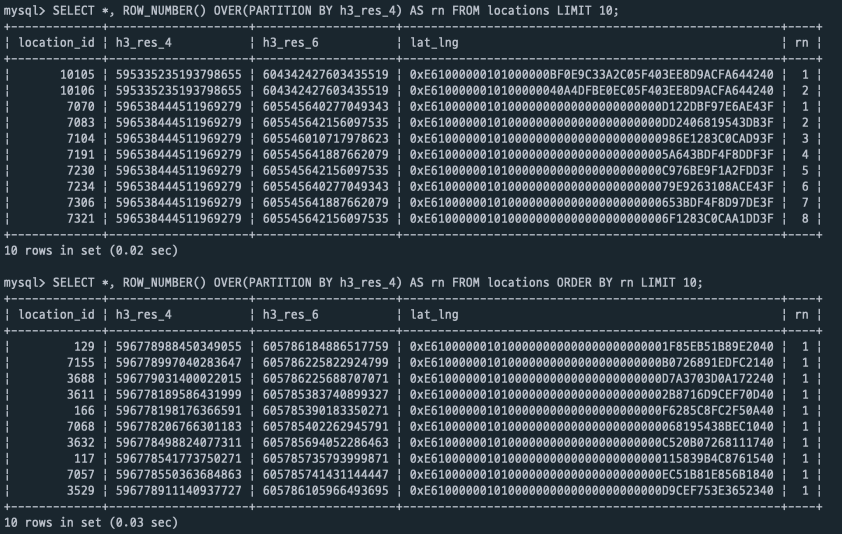
ORDER BY를 사용하지 않은 위의 값을 보면, 해당하는 h3_res_4마다 임의의 순번이 rn 필드로 주어진 것을 볼 수 있습니다.
이 때 rn 필드를 기준으로 ORDER BY를 사용하면 여러 구역의 데이터를 조화롭게 가져올 수 있는, 의도에 맞는 조회가 가능합니다.
QueryDSL로는 어떻게 작성해야 할까
QueryDSL은 Window Function을 지원해줄 수 있습니다. 다만 JPQL 기반으로 동작되는 만큼, JPQL에서 지원해주지 않는다면 사용할 수 없습니다.
Hibernate는 6버전부터 Window Function을 지원해주므로, 6버전 이상을 사용하신다면 QueryDSL로도 Window Function을 사용할 수 있습니다.
단, QueryDSL의 기본 설정만으로는 부족하므로, 먼저 연산에 필요한 Ops와 Templates에 대해 알아봅시다.
Ops
QueryDSL에는 특정 연산들을 미리 정의해 둔 enum이 있습니다.
com.querydsl.core.types.Ops를 보면 EQ, NE, IS_NULL 등이 정의되어 있고, 어떠한 반환값을 가지는지 지정되어 있습니다.
QClass.isNull()같은 메서드를 보면 내부적으로 Expressions.booleanOperation(Ops.IS_NULL, mixin);와 같은 값이 반환되는 것을 확인할 수 있습니다.
즉 내부 연산들은 대부분 Expression을 사용하게 되는데, 이 때 Ops의 연산자를 통해 어떠한 연산을 수행할 지 선택할 수 있습니다. 지난 시간에 Expressions.booleanOperation(SpatialOps.WITHIN, location.point, ...을 사용한 것도 이러한 이유입니다.
JPQLTemplates
Ops에 작성된 연산자를 어떠한 쿼리로 변경시킬 것인가는 JPQLTemplates를 통해 대부분 기입되어 있습니다.
JPQLTemplates은 Templates를 extend하고 있으며, 여기에는 IdentityHashMap<Operator, Template>이 존재합니다. JPQLTemplates는 해당 HashMap에 add(Ops.IS_NULL, "{0} is null");처럼 연산자와 해당 템플릿을 기입해 둡니다.
따라서 우리가 QueryDSL을 통해 isNull()을 호출하는 경우 내부적으로 Expression을 사용하며 Ops.IS_NULL 연산을 시도하고, 이는 {0} is null과 같은 템플릿으로 쿼리를 작성하게 됩니다.
Window Function Ops
Window Function이 기입되어 있는 Ops는 SQLOps가 있습니다. 이제부터 사용할 row_number()도 SQLOps.ROWNUMBER(Long.class)로 정의되어 있습니다.
해당하는 Expression들은 SQLExpressions를 통해 쉽게 사용할 수 있습니다. 저 역시 SQLExpressions.rowNumber()를 적용하겠습니다.
Custom Templates(extends JPQLTemplates)
아쉽게도 그냥 SQLExpressions.rowNumber()를 사용했다간 예외가 발생합니다. SQLTemplates와 짝을 이루는 Ops를 사용하기 때문이죠.
코드로 확인해 보겠습니다.
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(entityManager);
}entityManager만 인수로 넘기면, JPAQueryFactory는 JPQLTemplates.DEFAULT를 사용하게 됩니다.
JPQLTemplates.DEFAULT에는 아쉽게도 row_number()에 대한 정의가 존재하지 않고 Ops, JPQLOps의 값들에 대해서만 add가 이루어져 있습니다.
@Test
void jpqlTemplatesTest() throws Exception {
List<Tuple> tuples = queryFactory.select(location,
SQLExpressions.rowNumber().over().partitionBy(location.h3Res4).as("rn"))
.from(location)
.orderBy(Expressions.stringPath("rn").asc())
.limit(10)
.fetch();
for (Tuple tuple : tuples) {
System.out.println(tuple);
}
}실행을 해 보아도
java.lang.IllegalArgumentException: SQL Expressions like ROWNUMBER are not supported in JPQL - the query language for JPA. SQLExpressions.* can only be used in JPQL queries when these functions are registered as custom function in your ORM.
To fix this issue, you have three options:
1) If you do want to use advanced, dialect specific, SQL functions within JPQL, make sure to make these functions available to your ORM through custom functions and register these with your JPATemplates instance.
2) Use JPASQLQuery instead. This allows you to generate a pure SQL query based on your JPA metamodel.
3) Consider using the Blaze-Persistence QueryDSL integration. Blaze-Persistence is an extension on top of JPA that makes various SQL specific functions like window functions available to JPQL.라는 예외가 발생합니다.
예외 메시지대로 JPATemplates에 연산을 추가하거나, JPASQLQuery를 사용하거나, Blaze-Persistence를 사용하는 방법이 있습니다. JPASQLQuery는 QClass 내의 테이블명, 필드명 등을 모두 DB ERD에 맞도록 변경해야 제대로 된 쿼리를 출력할 수 있으므로 JPATemplates를 커스텀하거나 Blaze-Persistence를 사용하는 방법에 대해 알아보겠습니다.
커스텀은 간단합니다. JPATemplates를 상속받고 원하는 연산자에 대한 패턴을 작성해주면 됩니다.
static class CustomJPQLTemplates extends JPQLTemplates {
public CustomJPQLTemplates() {
add(SQLOps.ROWNUMBER, "row_number()");
}
}
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(new CustomJPQLTemplates(), entityManager);
}SQLOps.ROWNUMBER에 대한 패턴으로 row_number()를 입력했습니다. 이제 앞서 작성한 쿼리를 다시 동작시켜보면..
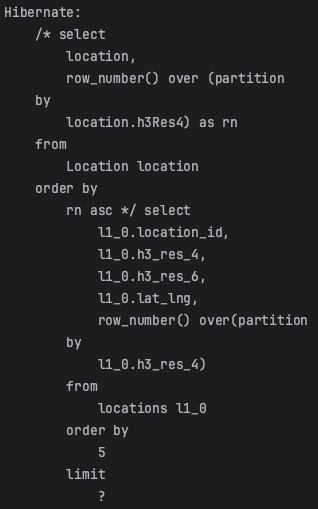
쿼리가 잘 나가는 것을 확인할 수 있습니다.
Blaze-Persistence expressions
이러한 템플릿을 하나하나 직접 작성하는 건 조금 피곤한 일입니다. 따라서 Blaze-Persistence의 템플릿과 expressions을 사용해 보는 것으로 합시다.
implementation 'com.blazebit:blaze-persistence-integration-querydsl-expressions-jakarta:1.6.11'@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(JPQLNextTemplates.DEFAULT, entityManager);
}List<Tuple> tuples = queryFactory.select(location,
JPQLNextExpressions.rowNumber().over().partitionBy(location.h3Res4).as("rn"))
.from(location)
.orderBy(Expressions.stringPath("rn").asc())
.limit(10)
.fetch();PQLNextTemplates.DEFAULT에는 날짜 관련 연산, Window Function을 비롯한 다수의 패턴들이 작성되어 있습니다. 만약 여러 고급 쿼리들을 사용한다면 하나씩 커스텀하는 것보다 이 쪽을 사용하는 것이 훨씬 더 효율적일 것입니다.
Custom Templates(extends Hibernate5Templates)
만약 querydsl-spatial 등을 사용중이시라면 JPQLTemplates를 확장하여 사용할 시 적용이 되지 않습니다. 이런 경우에는 Hibernate5Templates를 extend 및 사용하실 Ops에 대한 패턴을 add하여 사용하시면 되겠습니다. Hibernate5Templates 역시 JPQLTemplates를 확장한 템플릿이므로 사용 가능합니다.
만약 그럼에도 불구하고 동작하지 않는다면, 기존에 정상적으로 사용되던 템플릿이 무엇인지 확인해봐야 합니다. AbstractJPAQuery 생성자 부분에 중단점을 걸고, 어떠한 템플릿이 전달되는지 체크해보세요.
부록: ORDER BY에만 적용하는 법
아쉽게도, 제가 이미 작성해 놓은 QueryDSL은 @QueryProjection을 사용하여 QClass로 데이터를 반환해주고 있었습니다. 해당 클래스의 생성자 파라미터에 row_number()를 위한 Long 값을 넣어도 되겠지만, 단순 정렬을 위한 데이터이기에 굳이 넣고 싶진 않더라구요.
따라서 ORDER BY에만 적용하는 법을 알아보겠습니다.
.orderBy에는 OrderSpecifier이 필요합니다. 그렇다면 row_number() 연산을 OrderSpecifier로 만들어주면 잘 동작될 것입니다.
OrderSpecifier는 생성자로 정렬 방법과 Expression이 필요합니다.
정렬 방법은 Order.ASC, Order.DESC의 enum 값입니다.
WindowFunction 역시 Expression에 속합니다.
따라서 정렬 방법 및 WindowFunction으로 OrderSpecifier를 생성 가능합니다.
OrderSpecifier<Long> orderSpecifier = new OrderSpecifier<>(Order.ASC,
JPQLNextExpressions.rowNumber().over().partitionBy(location.h3Res4));
List<Location> locations = queryFactory.selectFrom(location)
.orderBy(orderSpecifier)
.limit(10)
.fetch();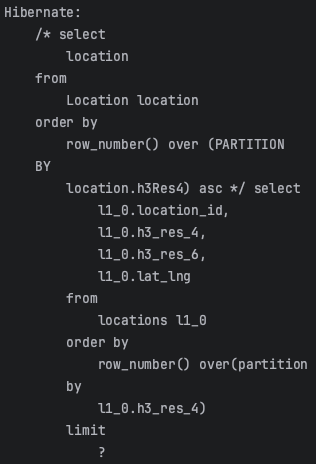
row_number()만을 위한 필드값을 선언하지 않고도 원하는 쿼리를 생성할 수 있었습니다.
부록: Window Function 내에서 OrderBy가 먹히지 않을 때
기존에 작성했던 쿼리에는 문제가 있습니다. 로직 상 여러 영역의 전반적인 값을 가져올 수 있는 것은 맞지만, 새로 작성된 글(post.id가 높은 글)을 우선적으로 가져오려면 partition by에 더해 order by가 추가되어야 합니다.
| post.id | location.h3Res4 | row_number() |
|---|---|---|
| 1 | 100 | 1 |
| 2 | 100 | 2 |
| 3 | 100 | 3 |
| 4 | 100 | 4 |
| 5 | 100 | 5 |
| 6 | 200 | 1 |
| 7 | 200 | 2 |
| 8 | 200 | 3 |
| 9 | 300 | 1 |
위와 같은 결과에서 row_number()를 기준으로 정렬한다면
| post.id | location.h3Res4 | row_number() |
|---|---|---|
| 1 | 100 | 1 |
| 6 | 200 | 1 |
| 9 | 300 | 1 |
| 2 | 100 | 2 |
| 7 | 200 | 2 |
| 3 | 100 | 3 |
| 8 | 200 | 3 |
| 4 | 100 | 4 |
| 5 | 100 | 5 |
이처럼 정렬될 것입니다.
글 3개만 조회할 경우 {100, 200, 300} 구역의 글을 하나씩 가져올 것입니다.
헌데 만약, 새로 작성된 글들을 우선적으로 조회한다면 어떻게 될까요?
OrderSpecifier<Long> orderSpecifier = new OrderSpecifier<>(Order.DESC,
JPQLNextExpressions.rowNumber().over().partitionBy(location.h3Res4));기존 쿼리에서 정렬 순서를 DESC로 변경해보면
| post.id | location.h3Res4 | row_number() |
|---|---|---|
| 5 | 100 | 5 |
| 4 | 100 | 4 |
| 8 | 200 | 3 |
| 3 | 100 | 3 |
| 7 | 200 | 2 |
| 2 | 100 | 2 |
| 9 | 300 | 1 |
| 6 | 200 | 1 |
| 1 | 100 | 1 |
위와 같은 결과가 도출됩니다.
글 3개만 조회할 경우 {100, 200, 300} 구역의 글을 하나씩 가져올 것이라 예상했지만, {100, 200}의 값만 가져오게 됩니다.
만약 100 구역에 글이 많이 쓰여졌다면 100 구역의 글만 가져왔을 것입니다.
이는 초반에 수립한 계획과는 많이 동떨어져 있습니다.
즉 partition by()가 동작할 때 어떠한 순서로 row number()를 부여해 줄 지도 선언해야 합니다.
order by(post.id.desc())를 선언한다면
| post.id | location.h3Res4 | row_number() |
|---|---|---|
| 1 | 100 | 5 |
| 2 | 100 | 4 |
| 3 | 100 | 3 |
| 4 | 100 | 2 |
| 5 | 100 | 1 |
| 6 | 200 | 3 |
| 7 | 200 | 2 |
| 8 | 200 | 1 |
| 9 | 300 | 1 |
로 row_number()가 지정될 것이고, 이를 최종적으로 row_number()에 대해 정렬한다면
| post.id | location.h3Res4 | row_number() |
|---|---|---|
| 5 | 100 | 1 |
| 8 | 200 | 1 |
| 9 | 300 | 1 |
| 4 | 100 | 2 |
| 7 | 200 | 2 |
| 3 | 100 | 3 |
| 6 | 200 | 3 |
| 2 | 100 | 4 |
| 1 | 100 | 5 |
처럼 변경되어 최신 글을 기준으로 하여도 전체적으로 분포된 값을 얻어올 수 있게 될 것입니다.
따라서, partition by()에 정렬계획도 같이 넣어주도록 하겠습니다.
OrderSpecifier<Long> orderSpecifier = new OrderSpecifier<>(Order.ASC,
JPQLNextExpressions.rowNumber().over().partitionBy(location.h3Res4).groupBy(post.id.desc()));쿼리를 실행시키니
rg.springframework.dao.InvalidDataAccessResourceUsageException:
... order by row_number() over(partition by l1_0.h3_res_4 order by order()) ...order by 부분에 order()가 작성되고, 실질적으로 연산되지 않는 쿼리가 발생합니다.
... order by row_number() over(partition by l1_0.h3_res_4 order by [*]order()) ...querydsl이 생성하는 jpql에 문제가 생기는 듯 합니다.
SQLQueryFactory를 사용해보니
order by row_number() over (partition by location.h3Res4 order by post.id desc) asc문제 없이 잘 생성되는 모습을 볼 수 있습니다.
아마 JPAQueryFactory와 SQLQueryFactory의 쿼리 빌더 해석에 차이가 있는 듯 합니다.
이를 해결하기 위해 위에 소개한 Blaze-Persistence를 사용해 보도록 하겠습니다.
private static class CustomTemplates extends Hibernate5Templates {
public CustomTemplates() {
add(JPQLNextOps.ROW_NUMBER, "row_number()");
add(JPQLNextOps.WINDOW_ORDER_BY, "ORDER BY {0}");
add(JPQLNextOps.WINDOW_PARTITION_BY, "PARTITION BY {0}");
add(JPQLNextOps.WINDOW_DEFINITION_1, "{0}");
add(JPQLNextOps.WINDOW_DEFINITION_2, "{0} {1}");
add(JPQLNextOps.WINDOW_DEFINITION_3, "{0} {1} {2}");
add(JPQLNextOps.WINDOW_DEFINITION_4, "{0} {1} {2} {3}");
}
}Hibernate5Templates를 extend하여 GIS 쿼리를 허용함과 동시에, 연산에 필요한 row number(), partion by(), order by()에 대한 템플릿을 추가하겠습니다.
또한 WINDOW_DEFINITION 관련 연산도 추가하는데, 이는 window function을 돌릴 때 각각의 템플릿을 연결해주는 역할입니다.
OrderSpecifier<Long> orderSpecifier = new OrderSpecifier<>(Order.ASC,
JPQLNextExpressions.rowNumber().over().partitionBy(resPath).orderBy(post.id.desc()));unknown operation with operator ROW_NUMBER and args [] over (unknown operation with operator WINDOW_DEFINITION_2 and args [unknown operation with operator WINDOW_PARTITION_BY and args [location.h3Res4], unknown operation with operator WINDOW_ORDER_BY and args [post.id DESC ]]) ASCorderSpecifier의 target을 보면 ROW_NUMBER에 대해 WINDOW_DEFINITION_2으로 2개의 연산이 존재하고, 이는 각각
WINDOW_PARTITION_BY와 WINDOW_ORDER_BY인 것을 확인할 수 있습니다.
이제 QueryDSL을 통해 GIS 쿼리 및 WINDOW 쿼리를 모두 안전하게 동작시킬 수 있게 되었습니다.
