KOCW.이화여자대학교.반효경.운영체제
위 강의를 바탕으로 학습 및 정리했습니다
메모리 관리
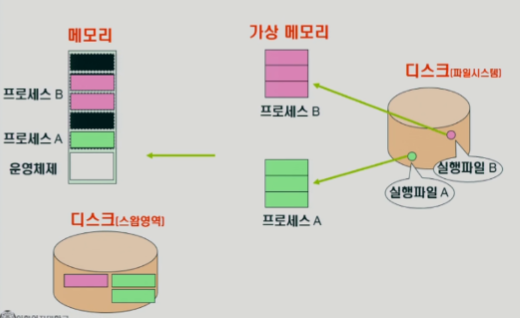
Logical vs Physical Address

-
메모리는 주소를 통해서 접근하는 장치
-> 메모리 주소는 크게 2가지 -
프로그래머가 바라볼 때 -> 심볼릭 주소(변수이름, 함수이름 등)
-
컴파일 후 실행파일 등이 되었을 때 -> 로지컬 주소
-
실행될 때 -> 물리적 주소
-
논리 주소 -> 물리 주소 변환(주소 바인딩)은 누가 해줌?
-> 운영체제 x ,하드웨어가 해줌
Logical 메모리 관리
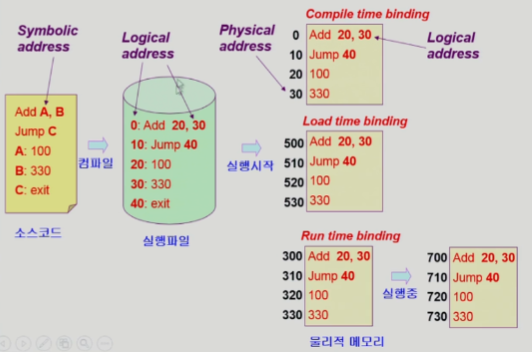
주소 바인딩 (Address Binding)

- 주소 바인딩 되는 시점
- Compile time
- 컴파일 될 때 주소 결정 (absolute)
- 전용 컴퓨터(Special purpose)에서 사용
- Load time
- 물리적 주소가 실행(시작 되는 시점)될 때 결정 (relocatable)
- 현대 운영체제
- Run time
- 프로그램이 실행되는 도중에 바인딩이 바뀔 수 있음 (재배치 가능)
- 메모리 접근할 때 마다 매번 주소 전환이 필요해서 하드웨어적인 지원 필요
- Compile time
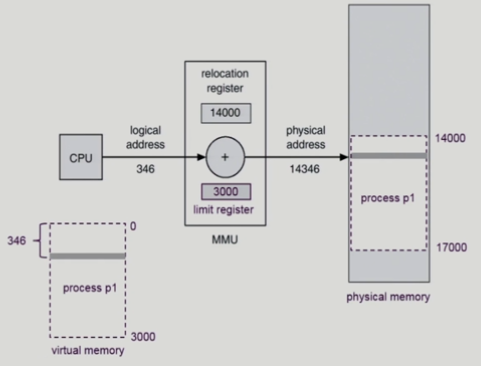
Memory-Management Unit

Dynamic Relocation
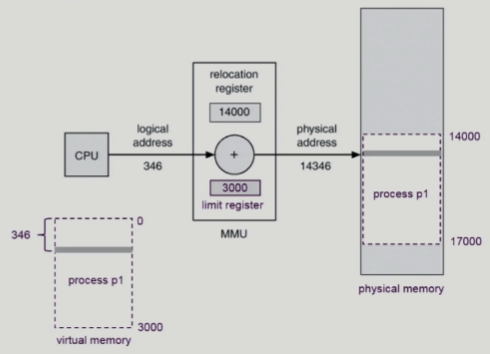
- CPU가 논리적 주소 확인
- MMU 하드웨어로 메모리 주소 변환
Hardware Support for Address Translation
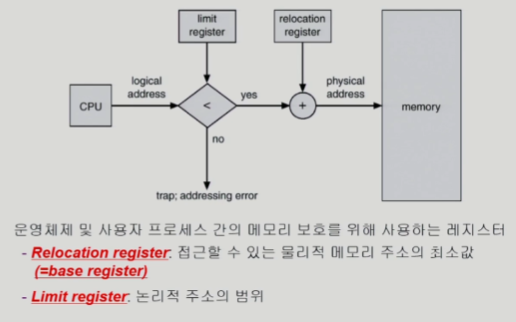
- limit register : 논리적 주소 범위
- 메모리 주소가 리미트 레지스터 바깥이면 다른 프로세스의 메모리를 보려는 악의 적인 시도 일 수 있음
Some Terminologies

Dynamic Loading

- 실행되는 부분만 메모리에 올림 -> 메모리 낭비 감소
- 오리지날 다이나믹 로딩은 라이브러리를 통해 구현
- 현대 운영체제에서 채택한 방법은 아님
-> 지금 운영체제가 필요한 부분만 메모리에 올리기는 하는데 오리지날 아님
Overlays

- 옛날엔 물리적 메모리 크기가 작아서 프로그램 하나를 메모리에 올리는게 불가 했었음
-> 프로그래머가 수작업으로 필요한 부분만 메모리에 올라가게 코딩함
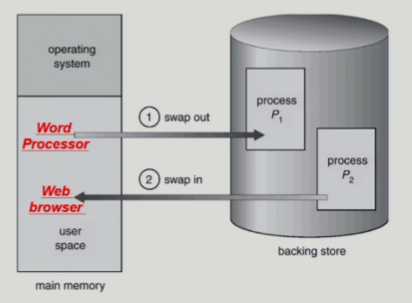
Swapping

-
오리지널 의미는 메모리에서 프로세스를 통채로 쫒아내는거
-
중기 스케줄러
- 메모리에 너무 많은 프로그램이 동시에 올라가 있으면 일부 프로세스 골라내서 통채로 쫒아냄
-
스와핑엔 runtime 바인딩이 좋음
Dynamic Linking

-
linking 하면 실행파일 코드에 라이브러리 코드가 포함이됨
-> Static Linking- 단점
- 동일 라이브러리가 각각 프로세스 메모리에 올라가서 메모리 낭비됨
- 단점
-
라이브러리가 별도의 파일로 존재
-> 라이브러리 필요할 때 파일형태로 찾아서 메모리에 올림 (stub이라는 라이브러리 위치 찾기 코드가 있음)
-> 연결
-> Dynamic Linking (== Shared library / .so, . dll) -
Dynamic 장점
- 공유 개념이니까
Allocation of Physical Memory

- 연속할당
- 프로그램이 쪼개지지 않고 통채로 메모리에 올라감
-> 주소변환이 비교적 간단 (시작위치만 알아내고 더해주면 됨)
- 프로그램이 쪼개지지 않고 통채로 메모리에 올라감
- 불연속 할당
- 프로그램 주소공간이 분산되어 올라감
- 어느 부분은 메모리에 있고 어느 부분은 스토리지에 쫒겨나있을 수 있음
Contiguous Allocation

-
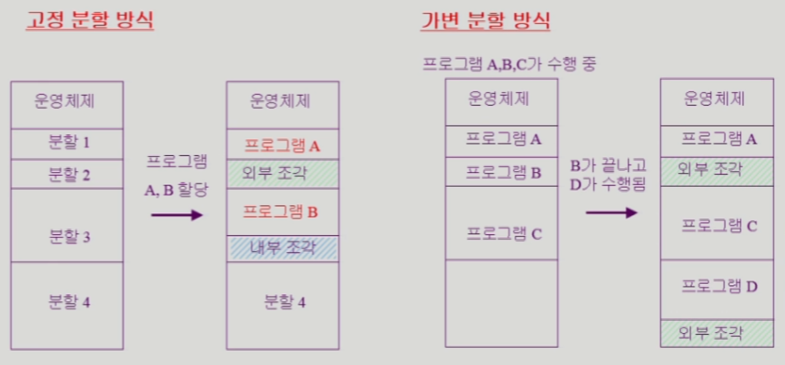
고정 분할
- 분할 크기는 정해져 있음
-> 프로그램을 할당하게 됐을 때
분할 크기보다 프로세스 크기가 더 작으면
활용 안되는 짜투리 공간이 생길 수 있음
== 내부 조각 == 비효율
- 분할 크기는 정해져 있음
-
가변 분할
- 미리 메모리 영역을 나누어 놓지 않는 방법
- 연속할당 함
-> B가 끝났을 때 B만큼 남는 공간이 생김
-> 그 크기 이하의 프로세스만 들어올 수 있음
-> 낭비 == 외부조각
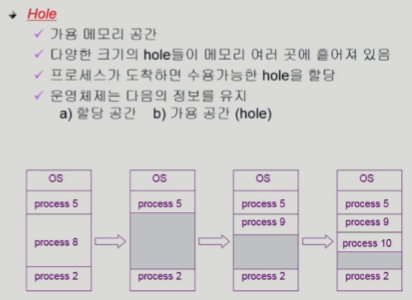
- 조각들은 사실 가용 메모리 공간
- 프로그램 실행 종료를 반복하면 공간이 여기저기 흩어져 있음 (hole)
-> 현재 사용되는 공간과 비어있는 공간 정보 갖고 있음
-> 새로운 프로세스 실행될 때 어느 hole에 올릴 것이냐 결정 해야함 (아래가 그 해결책 3가지)
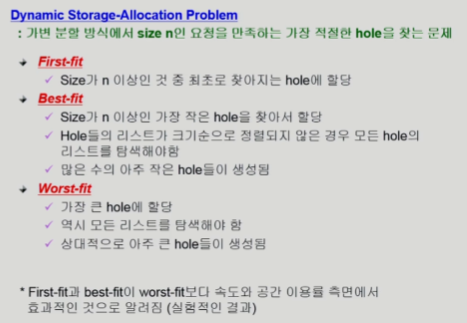
-
가장 처음 찾아지는데에 할당
-
프로그램 사이즈보다 큰 거중에 가장 작은거에 할당 (best fit)
- 탐색의 overhead 발생
- 이 프로그램 할당하면 또 더 작은 hole 발생 할 수도 있음
-
제일 큰 hole에 할당 (worst)
- 당장 큰 hole을 소진해버리는게 문제
- 그 뒤에 더 큰 프로세스가 오면?
- 당장 큰 hole을 소진해버리는게 문제

-
빈공간들을 한데 모아서 큰 hole로 만드는 방법
-
비용이 많이 듬
- 메모리에 올라가 있는 모든 프로세스가 이동해야 할 수도 있음
-
runtime 바인딩에서만 컴팩션 가능
Noncontiguous Allocation
-
불연속할당은 위처럼 레지스터 2개 만으로 주소 할당하기 힘듬
-> 프로그램 주소공간이 여러개로 짤려서 각각이 다른 부분에 올라가기 때문에 어려움 -
페이징 기법
-> 보통 사용하는 페이지 크기는 4KB
-> 프로세스가 4GB라고 했을 때 페이지 약 100만개 생김
-> 페이지테이블 100만개 필요
Paging

- 외부조각 발생안함
- 모든 페이지의 크기를 같은 크기로 딱 맞게 자르기 때문에
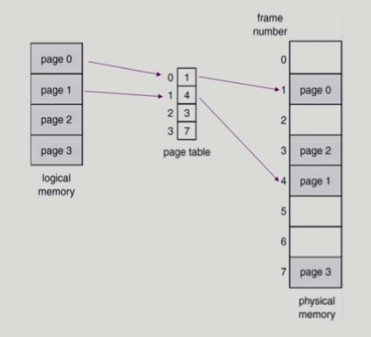
- 페이지 테이블을 통해 주소 배분함
- 페이지 테이블을 통해 물리적은 주소로 변환
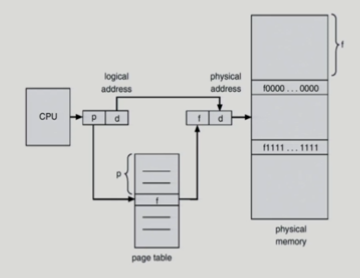
- physical address는 변하지 않음
Implementation of Page Table

- 페이지의 개수가 프로세스마다 100만개 이상
-> 레지스터에 페이지 테이블 못 넣음
-> 메인 메모리에 레지스터 넣음
-> 메모리 접근하려면 주소 변환을 위해 1번, 데이터 접근을 위해 1번
-> 성능 저하 우려됨
-> 주소 변환 전담하는 Cache를 두게 됨 Called TLB
Paging Hardware with TLB
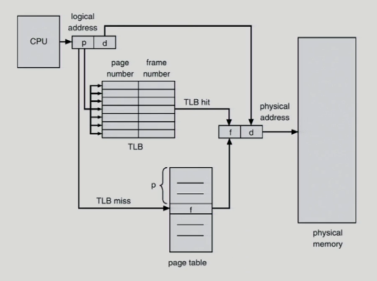
- TLB에 p 주소변환 정보 있는지 다 탐색해야함
-> overhead 큼
-> 하드웨어를 통해 병렬적으로 탐색
-> 그 하드웨어 == associative register
Associative register

- 다른 프로세스 실행되면 TLB 싹 지워야함
Effective Access Time

- 접근 시간을 계산한 것
Two-Level Page Table

- 페이지 테이블을 위한 공간이 너무 큼
-> 너무 낭비
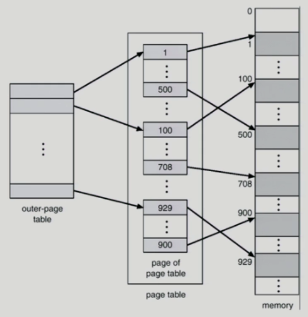
-
주소 접근 + 데이터 접근 -> 시간 너무 오래 걸림
-
안쪽 페이지 테이블 = 4KB
Two-Level Page Example

Address-Translation Scheme
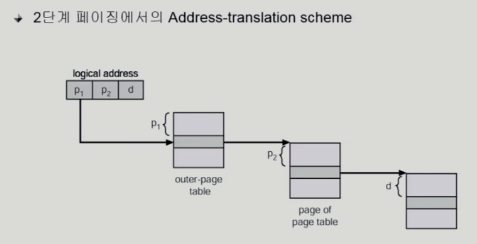
Multilevel paging and Performance

- 최외각 페이지만 있고 안쓰는건 다 null
-> 공간 줄일 수 있음 But, 시간이 오래걸림(다단계로 접근해야하니까)
-> TLB를 통해 시간 줄이기
valid / Invalid Bit in a Page Table
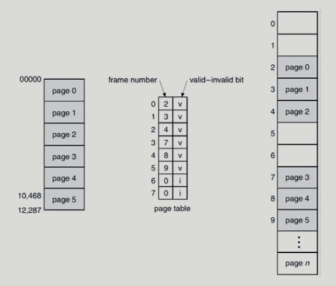
- 메모리에서 사용안하고 있으면 I
Memory Protection

- 뿐만아니라 디스크에 내려가 있는 경우도 I
- Protection bit : 읽기/쓰기 가능한지 둘 중 하나만 가능한지 기록
Inverted page table

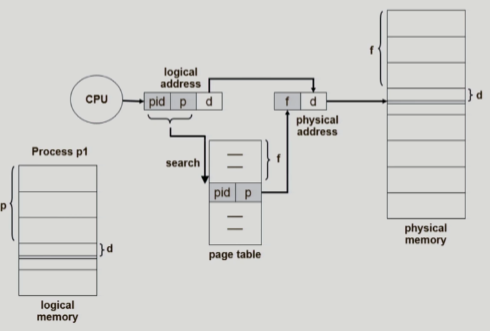
-
물리적인 주소를 가지고 논리적 주소를 얻어내기 쉬운 구조
-> 하지만 그 역은 페이지 테이블을 싹 검색해봐야 하는 구조 -
원래 page table의 장점은 논리적 주소를 가지고 물리적 주소를 금방 얻어낼 수 있는 구조인데 이는 그닥 효율적인 구조가 아님
+여러 프로세스가 p번째 페이지를 모두 갖고 있을 텐데 어느 프로세스의 p번째 테이블인지도 pid를 통해 따로 기록해놔야함
-> 병행 search가 가능한 associative resiater 사용 (근데 비싸다)
Shared Page

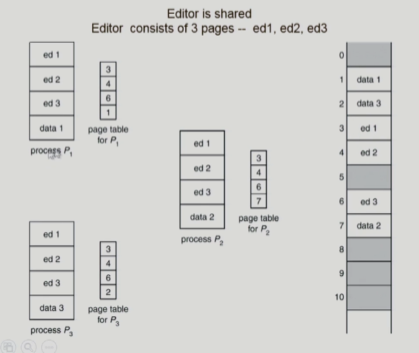
-
같은 프로그램이 프로세스 3개 생성하면
-> 사용하는 코드는 같고 데이터 부분만 다름
-> 다 따로 올리면 메모리 낭비
-> 따라서 shared code들은 한 copy만 메모리에 올리고 공유함 -
제약조건
- read only 만
- 논리적 주소가 같아야 함
(페이지 번호가 같아야 한다)
(Shared memory는 서로 다른 프로세스가 커뮤니케이션을 위해 공유하는 것(읽기/쓰기 다 가능)이므로 차이가 있음)
Segmentation

- 동일 크기가 아닌 의미 단위로 잘라서 물리적 메모리에 올림
- 연속할당에서 PTBR, PTLR로 시작위치, 길이를 알수있었음
이처럼 segment에서도 STBR, STLR로 시작위치, 길이를 알수있음
Segmentation Architecture

- offset : segment내에서 얼마나 떨어져 있는가 (31분부터)
Segmentation Hardware
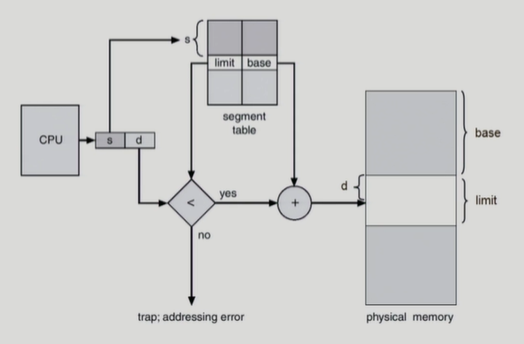
-
CPU가 논리주소를 줌(s/d)
- s : segement-number
- d : offset
-
주소를 찾아갔을 때 segment 길이(limit)보다 긴 부분을 d(offset)이 지정하고 있으면 주소 변환해주면 안됨(자기 범위가 아닌 부분을 접근하려는 불순한 요청임)
-
STLR = 3인데 s = 5 라면 위와 같이 비슷한 상황(불순한 접근)
Segmentation의 예
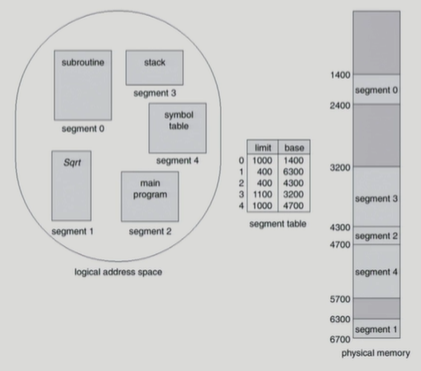
-
외부조각 발생
-> 외부조각 중에 어떤 부분에 세그먼트를 할당해야하냐의 문제 발생 -
현실적인 구현을 생각하면 Segmentation이 편함
- Paging에서 Table이 100만개 이상있던걸 생각하면 비교적 세그먼트의 개수(엔트리 개수)는 훨씬 적다
Segmentation Architecture (Continue)

-
연속할당에서 발생한 문제와 해결방법 비슷
-
Protection / Sharing의 관점에선 Paging보다 효과적
- paging 기법에서도 읽기/쓰기 가능여부 표현 가능은 했음
-> 근데 같은 사이즈로 자르다보니 코드인 부분과 데이터 부분을 정확히 나누기가 어렵다
-> 겹치는 부분은 Protection 정하는게 어려움 - 반면에 세그먼트는 의미 단위기 때문에 코드/데이터 부분 확실히 나뉨
-> Share / Protection 하고 싶은 부분을 쉽게 정할 수 있음
- paging 기법에서도 읽기/쓰기 가능여부 표현 가능은 했음
-
Allocation은 크기 기준으로 나눠서 세그먼트 기법과 잘 안맞음
Segmentation with Paging
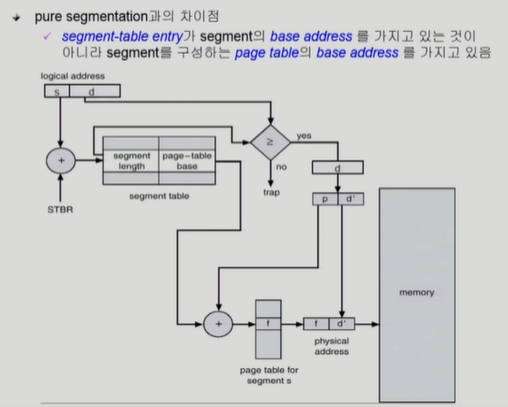
-
pure한 segmentation을 실제로 시스템에서 사용하지 않음 (메모리 관련 이슈)
-> paging 기법을 근간으로 사용
-> 실제 시스템에서 사용하는 방법 -
segment 크기가 page 크기의 배수가 되게함
- ex) 1번 세그먼트 : 3page / 2번 세그먼트 : 5page ,,,
-
물리적 메모리는 page 단위로 잘라놓고 관리
-
대신 의미 단위로 관리하는 것들은 segment table을 통해 관리
