파일시스템
파일과 파일시스템

- 파일 대표 연산 : 생성 - 삭제, 읽기 - 쓰기
- 파일 읽기 위한 포인터가 존재함
- lseek 연산
- 필요에 따라 현재 포인터의 위치를 수정해주는 연산
- open-close 연산
- open
- 파일의 meta data를 메모리에 올려 놓는 연산
- open
- 파일은 파일 자체내용 말고도 관리를 위한 data가 있음
-> 이를 meta data라고 함
디렉토리와 Logical Disk

-
traverse the file system
- 파일 시스템 전체를 탐색
-
하드디스크 파티션
-> 각각이 논리적 디스크가 됨 -
하드디스크 여러개 합침
-> 논리적 디스크 1개가 됨 -
하드디스크 용도
- 파일 시스템용
- swap area용
open()
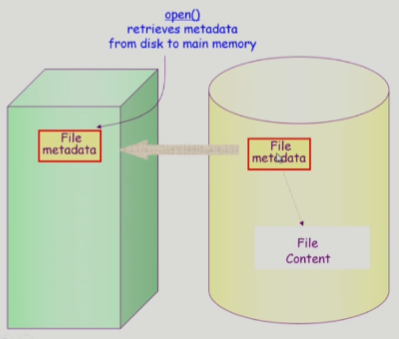
- opne()하면 meta data가 메모리로 올라옴

- root 디렉토리부터 따라내려가면서 C를 찾아내는 것임
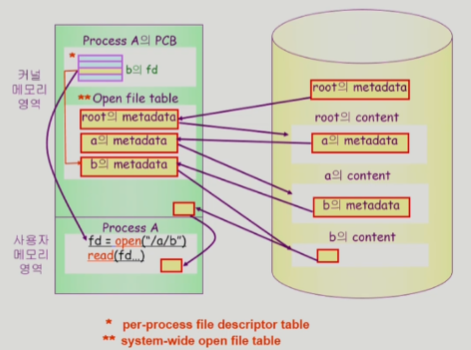
-
사용자 프로그램이 시스템 콜 (open도)
-> CPU 제어권 운영체제로
-> 운영체제가 root 디렉토리의 메타데이터를 메모리로
-> root의 metadata에서 root의 실제 위치를 찾아서 감
-> root 디렉토리의 내용을 보고 a라는 파일의 metadata를 메모리로
-> a의 위치정보로 실제 위치로 감
-> a 디렉토리에서 b의 metadata 찾아서 메모리로
-> open() 끝
-> read() 반환 -
read() 결과를 바로 사용자에게 전달하지 않고
자신의 메모리에 올려두고 카피해서 사용자에게 줌- 이렇게 하면 사용자가 읽기 요청을 할때마다 다시 디스크까지 가지 않아도 운영체제가 읽어놓은걸 다시 보여주면 됨
= 버퍼 캐시
- 이렇게 하면 사용자가 읽기 요청을 할때마다 다시 디스크까지 가지 않아도 운영체제가 읽어놓은걸 다시 보여주면 됨
-
프로그램마다 오프셋같은 정보를 따로 가지고 있음
- 프로그램마다 읽으려는 부분이 다를 수 있기 때문
파일 보호
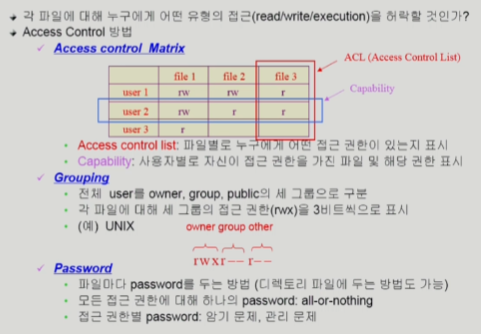
-
Access control Matrix
- 권한이 없는 user의 칸까지 다 만들어야함
-> 비효율적 - 각 파일을 주체로 user를 linked list로 생성
= Access control list - 반대로 user를 주체로 linked list로 생성
= Capability
근데, 이래도 오버헤드 너무 큼
- 권한이 없는 user의 칸까지 다 만들어야함
-
Grouping
- 그룹별로 권한 부여
- 권한이 있으면 1 없으면 0
일반적으로 Grouping 씀
파일 시스템의 Mounting
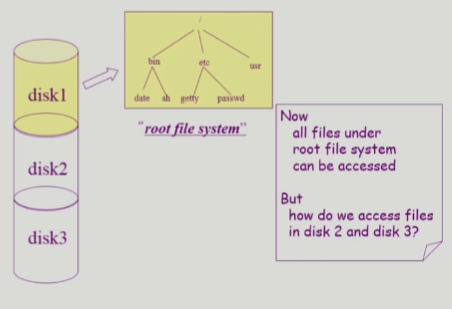
-
각각의 논리적 디스크에 각각의 파일 시스템 둘 수 있음 = root file system
-
다른 디스크의 파일 시스템 접근할 때는 ?
-> mounting
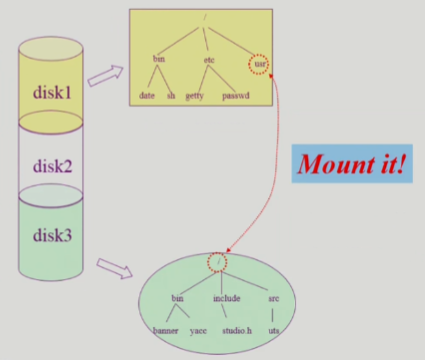
- 다른 디스크의 파일 시스템이 자식 노드가 되는 형태
파일 접근 방법

- 직접 접근
- 특정 위치에서 다른 위치 접근이 가능
(매체에 따라 다르지만)
- 특정 위치에서 다른 위치 접근이 가능
Allocation of File Data in Disk
- Contiguous Allocation
- Linked Allocation
- Indexed Allocation
Contiguous Allocation
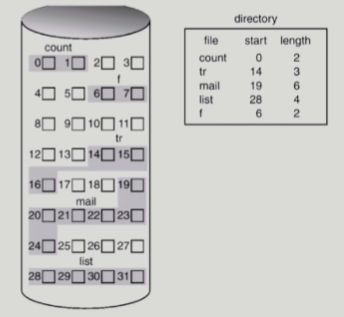
- 메모리관리의 페이징 기법과 비슷함
- 블럭이 균일한 크기로 나뉨
- 파일의 크기 만큼 연속된 블럭에 담는 방법
- start : 시작 블록 번호

-
단점
- 각 파일의 크기가 다름
-> 외부조각 발생 - 파일 수정에(크기를 키우는데에) 한계가 있음
- 각 파일의 크기가 다름
-
장점
- 많은 양의 데이터를 빠르게 읽어오기 가능
- 프로세스의 swap area용도로 씀
- 빠르게 내쫒고 올려놓고 하게 해줌
- realtime file에서도 사용
- 데드라인 -> 빠른 I/O필요하기 때문
- 그냥 start에서 원하는 만큼 더하면 주소 바로 나오니까 직접 접근이 쉬움
Linked Allocation
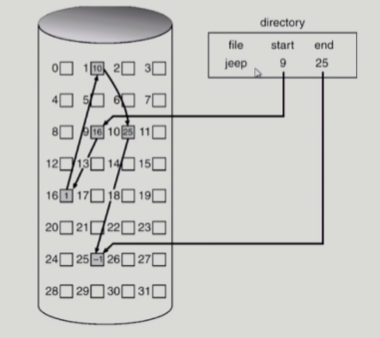

-
파일의 데이터를 디스크에 연속적으로 배치하지 않고 빈 블록에 바로 배치
- 각 블록이 다음 위치를 기록하고 있음
= 순차접근
-> 직접 접근 불가
- 각 블록이 다음 위치를 기록하고 있음
-
하나의 sector가 bad sector가 되면 그 다음위치 다 못 찾아감
-
블럭의 용량 크기는 무조건 512byte의 배수
-> 공간 효율성 떨어짐 -
변형해서 단점 완화
-> FAT
Indexed Allocation
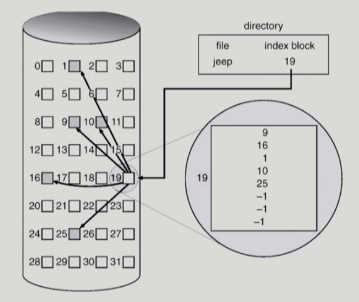
- 위치정보를 담은 블록을 따로 둠 (인덱스 블럭)
-> 직접 접근 가능

- 아무리 작은 경우라도 최소 2개 블럭 사용
-> 공간 낭비 - 매우 용량이 큰 파일은 인덱스블럭 1개로 불충분
-> 다 커버 못하면 다른 인덱스 블럭을 linked list로 엮음
실제 파일 시스템에선 어떤 할당 방법을 사용하는가?
UNIX 파일 시스템의 구조
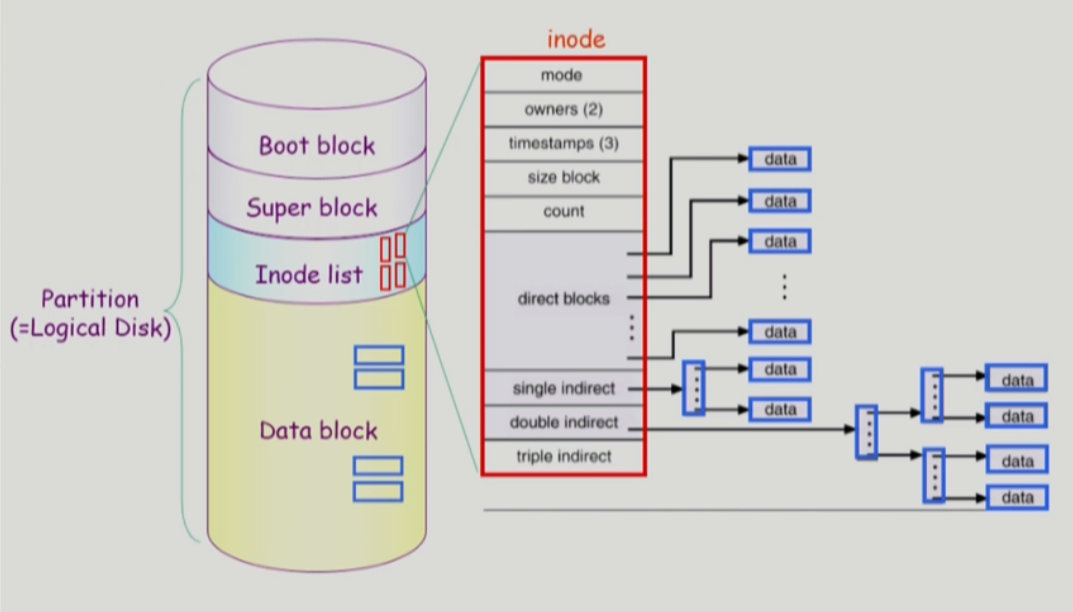
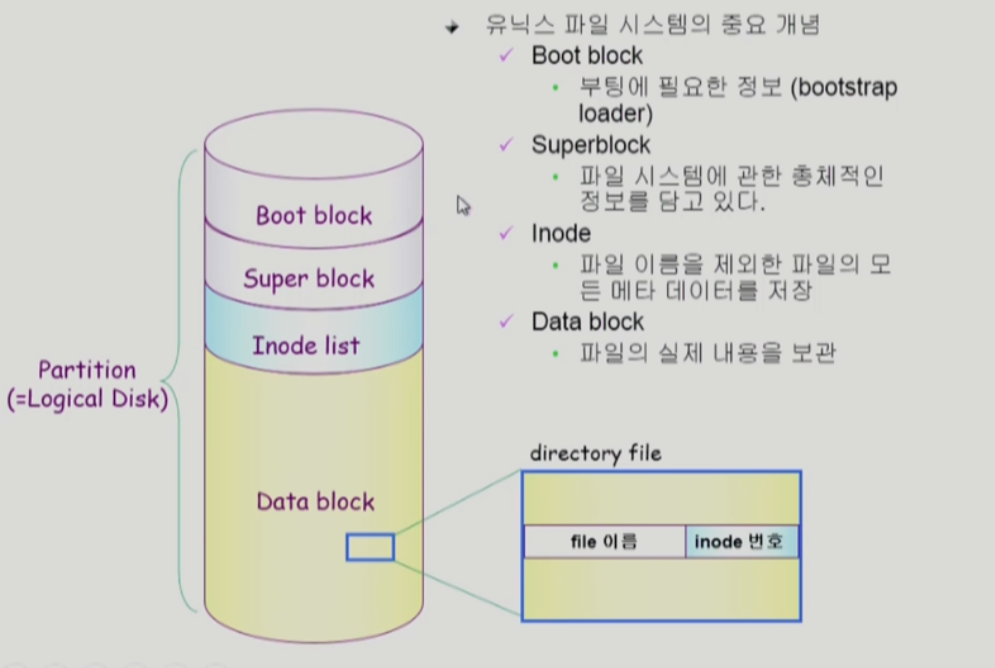
-
어떤 파일 시스템이던 boot block이 첫번째 블럭
-> 부팅을 위해서 -
indexed 할당 기반
-
실제 파일 시스템에서 디렉토리가 모든 meta data를 가지고 있진 않음
- 특히 unix는 극히 일부(파일이름, inode 번호)만 디렉토리에 넣고 나머지는 Inode list에 넣음
- 파일 하나 당 inode 하나
- inode 크기 정해져 있음
-> pointer 개수 유한함
/ 작은 파일은 그냥 direct block 하나로 표현 가능
-> 근데 큰 파일 표현어캐함?
-> direct, indirect 4가지로 위치정보 기록
FAT File System
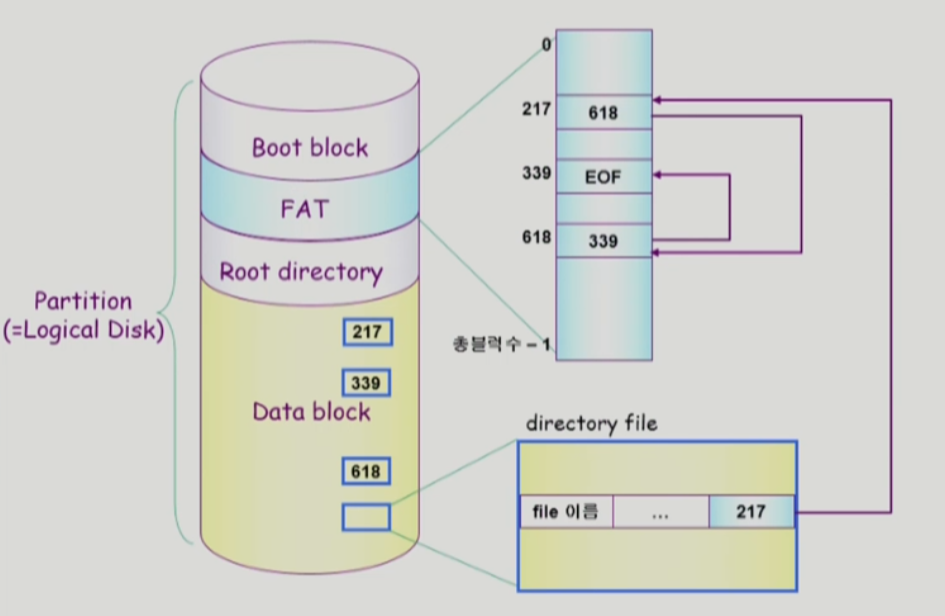
-
윈도우시스템이나 모바일 시스템에서 사용하는 경우가 있음
-
윈도우에서 이 파일 시스템의 발전된 버전 사용
-
모든 meta data를 디렉토리가 갖고 있음
-
linked 기반
-> 순차 접근이라서 bad file뜨면 뒤에꺼 사용못하는 문제가 있음
-> 다음 블럭의 위치 정보를 FAT에 따로 저장해서 해결 -
FAT
- 크기가 데이터 블럭 개수만큼인 배열
- FAT을 메모리에 한번 올려놓으면 직접접근 가능
- 매우 중요한 파일이기 때문에 여러개 FAT을 복제해놓음
-> 신뢰성
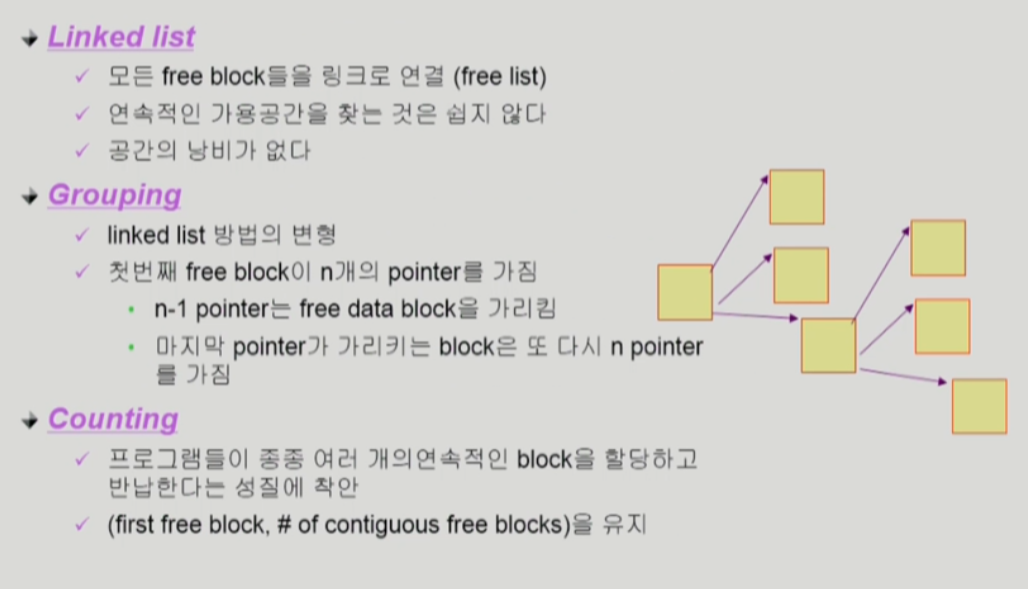
Free-Space Management
비어있는 블럭 관리하는 법
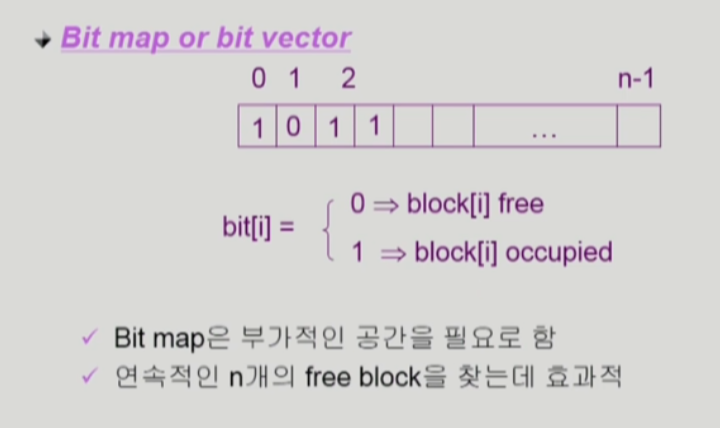
- 각 블럭에 bit를 둬서 사용중인지 아닌지 표현
- 데이터 할당할때 0인 블럭을 골라서 할당
- 1bit 밖에 안쓰기 때문에 부가적인 공간을 필요한다는 단점이 심각하진 않음
- 연속적인 free block 찾기 쉬움
- 연속된 0을 찾기만 하면됨
-
Linked
- bad 발생하면 다음꺼 모르는 문제 발생
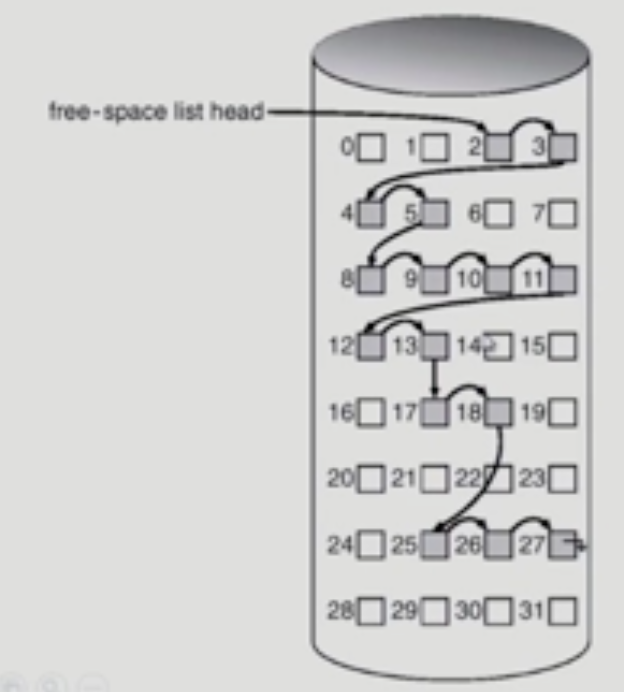
- bad 발생하면 다음꺼 모르는 문제 발생
-
Grouping
- indexed 할당의 변형
- linked보다는 효율적이지만 그래도 아직 연속적인 빈 블럭 찾기 어려움
-
Counting
- 어디부터 연속적으로 몇개가 비어있는지 정보가 있어서 연속적인 빈블럭 찾기 쉬움
Directory Implementation
디렉토리 어떻게 구현하는지
- 디렉토리
디렉토리 밑의 파일들의 meta data를 관리하는 특별한 파일

- Linear
- 특정 파일을 검색할 때 일일히 검색해봐야함
-> 시간 오래걸림
- 특정 파일을 검색할 때 일일히 검색해봐야함
- Hash
- 특정 파일을 검색할 때 해쉬함수를 적용해 특정 엔트리만 검색하면 됨
-> 효율적 탐색 - collision문제가 있음
- 특정 파일을 검색할 때 해쉬함수를 적용해 특정 엔트리만 검색하면 됨
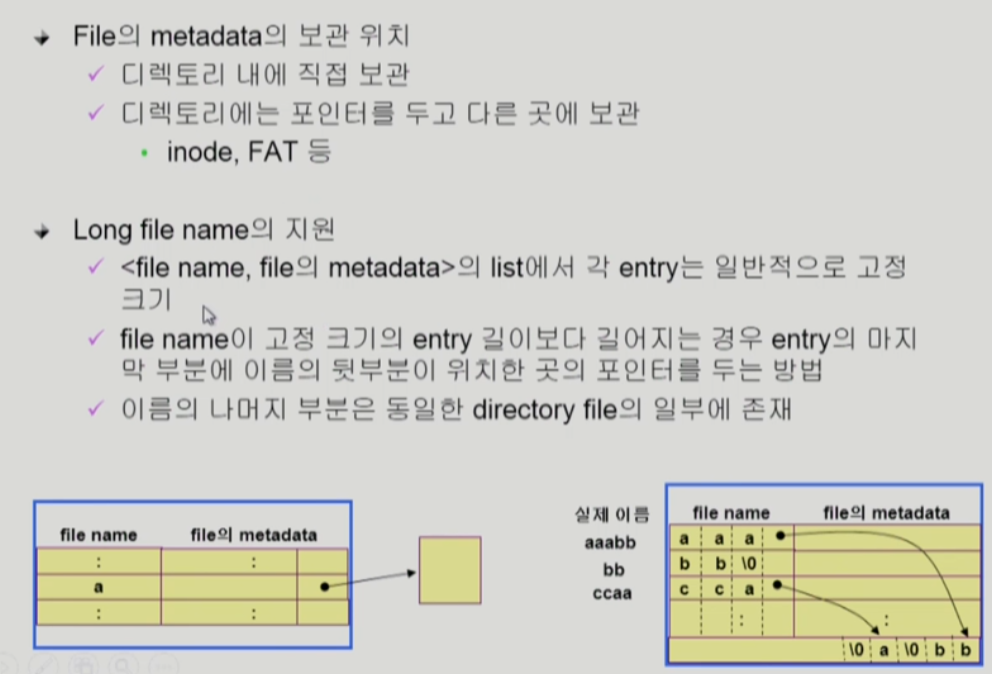
- 파일이름은 고정 크기보다 길어질 수 있음
- 길어진 파일 이름은 포인터로 빼서 가지고 있음
VFS and NFS
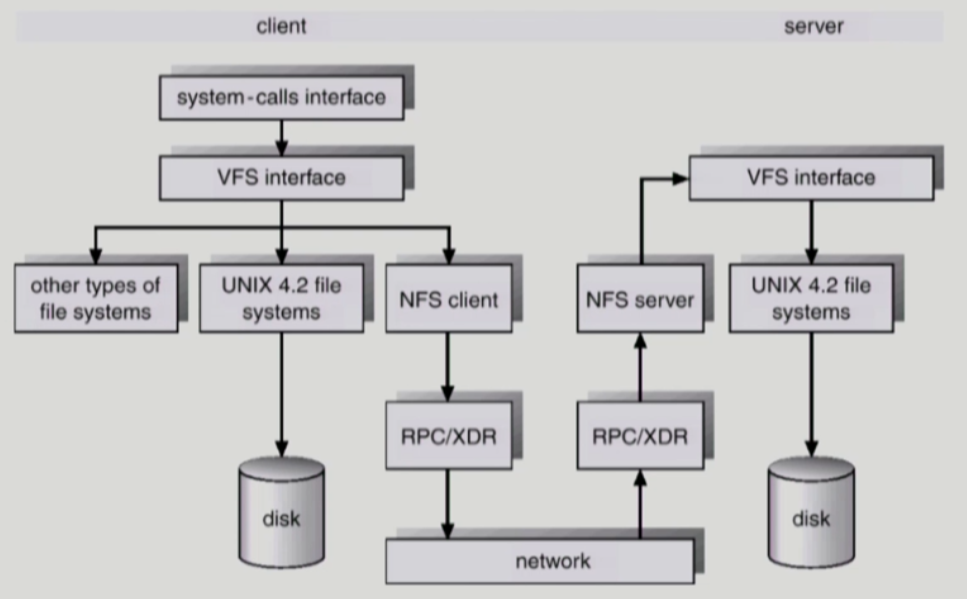
- 2대의 컴퓨터가 네트워크로 이어진 그림

- 파일 시스템마다 다른 인터페이스를 가지고 있을 수 있음
- VFS로 해결
- NFS
- 원격에 있는 파일을 다룰 수 있도록 도와줌
- 서버, 로컬 둘다 NFS모듈이 있어야함
페이지 캐쉬와 버퍼 캐쉬

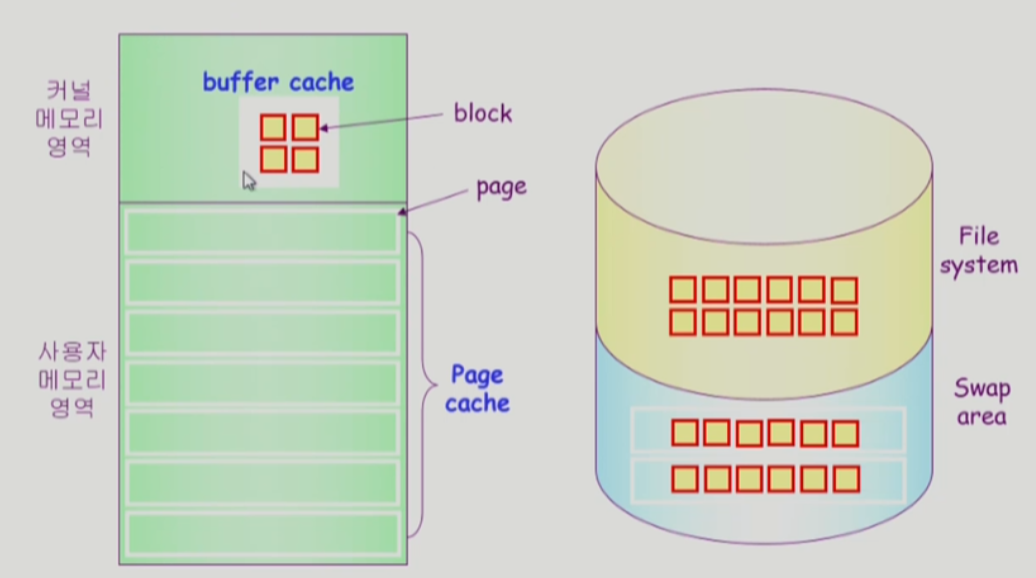
-
버퍼 캐쉬
- os가 읽어온 데이터를 자신의 영역 중 일부에 저장해서
요청이 들어올 때마다 디스크까지 안가고 저장한거를 보내줌
- os가 읽어온 데이터를 자신의 영역 중 일부에 저장해서
-
파일의 관점 - 버퍼케시
-
버츄얼메모리 관점 - 페이지 캐시
-
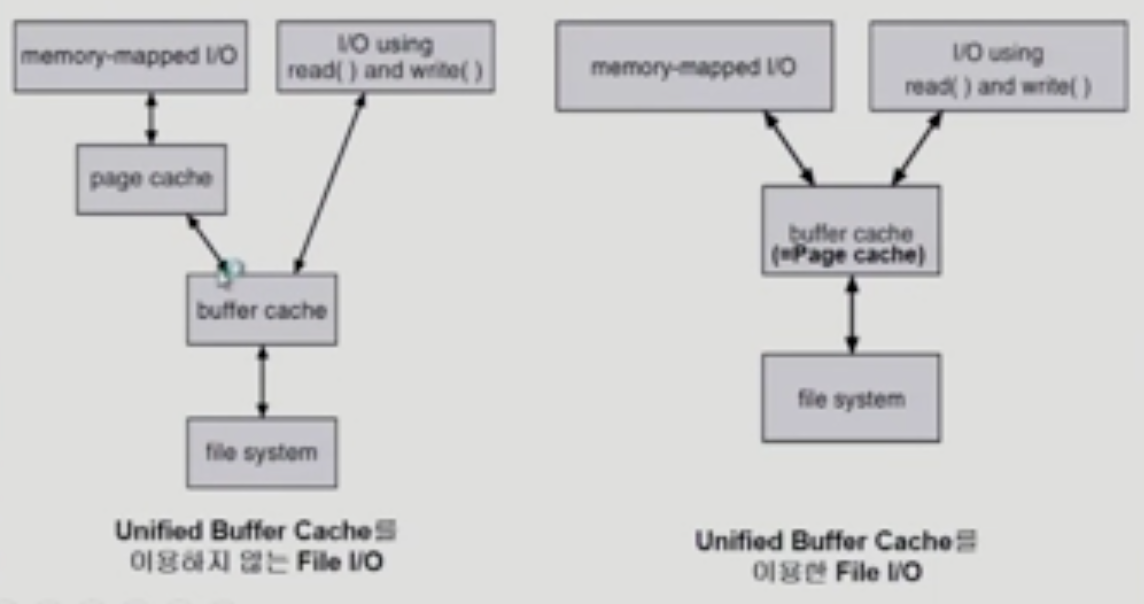
최근에는 페이지캐쉬, 버퍼케시 한번에 묶어서 관리하는 운영체제가 많음
-
버퍼캐시 따로 안두고 페이지 캐쉬로 통합
-> unified buffer cache -
unified buffer cache
- 페이지 -4kb
- 블럭 - 512byte
- 최근엔 버퍼 캐쉬와 페이지 캐쉬 합쳐짐
-> 블럭 - 4kb 단위로 관리
-
memory mapped i/o
- 파일의 일부분을 메모리에 mapping 해놓으면 시스템콜 없이 접근 가능
- 메모리를 접근하면 파일 입출력을 할 수 있게 함
프로그램의 실행
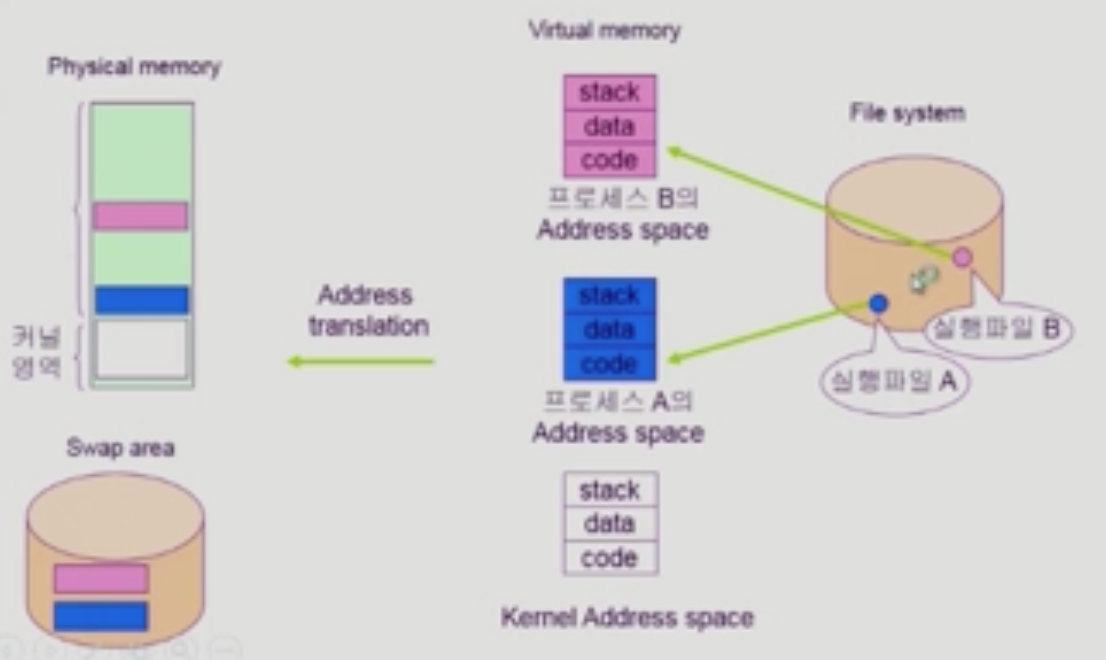
- 프로그램 실행될 때 스택, 데이터는 메모리로 올라가서 안사용하면 swap area로 감
- 근데 code부분은 실행 파일 자체이기 때문에 사용할 때 메모리에 매핑시켜서 사용
- 따라서, 사용되지 않을 때 swap area로 내리는 게 아님
- 필요할 때 메모리 가면 페이지 fault 발생
-> 코드 부분은 매핑되어있기에 swap area에서 찾는게 아니고
매핑되어있는 부분을 파일입출력함
