
저자 github
2회독이라 이번에는 동영상 시청을 병행하고 있는데,
깃허브 팔로우 좀.. (실제 강의 중에 얘기하심) 🤣
텍스트로만 읽다가 소리와 영상으로 시청하니까 느낌이 또 다르다.
책에 없는 내용을 추가적으로 설명하기도 한다.
이렇게 전체적인 그림을 그릴 수 있으려면 얼마나 많이 보고 생각해야 하는 걸까?
1주차
- Chapter 01 ~ 03
- 기본숙제: p. 51의 확인 문제 3번, p. 65의 확인 문제 3번 풀고 인증하기
- 추가숙제: p. 100의 스택과 큐의 개념을 정리하기
chapter 01 컴퓨터 구조 시작하기
1-1 컴퓨터 구조를 알아야 하는 이유
프로그래밍 언어의 문법과 함께 컴퓨터의 근간을 알아야 한다.
1) 문제 해결 능력: 문제가 발생했을 때 컴퓨터 내부를 거리낌 없이 들여다 보는 사람!
- 미지의 대상에서 분석의 대상으로
2) 성능, 용량, 비용을 고려한 개발을 할 수 있기 때문
1-2 컴퓨터 구조의 큰 그림
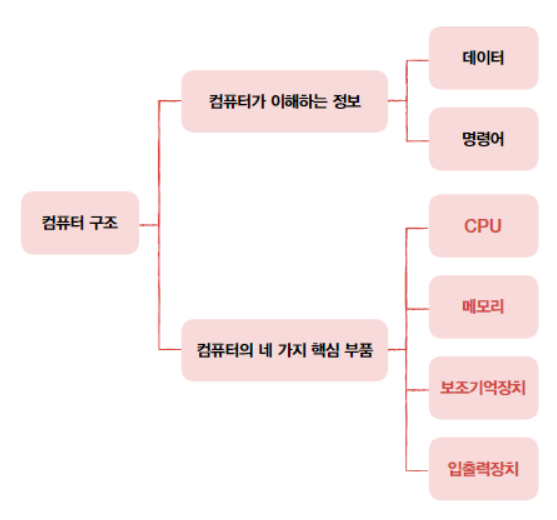
컴퓨터가 이해하는 정보
1. 데이터
- 숫자, 문자, 이미지, 동영상과 같은 정적인 정보
- 컴퓨터가 주고 받는/내부에 저장된 정보를 데이터라 통칭
- 0과 1을 숫자/문자로 표현하는 방법
2. 명령어
- 컴퓨터는 명령어를 처리하는 기계다
- 명령어
- 컴퓨터를 실질적으로 움직이는 정보
- 데이터는 명령어를 위한 일종의 재료
컴퓨터의 네 가지 핵심 부품
1. 메모리(주기억장치):
현재 실행되는 프로그램(프로세스)의 명령어와 데이터를 저장하는 부품. 메모리의 저장된 값의 위치는 주소로 알 수 있다.
2. CPU:
컴퓨터의 두뇌. 메모리에 저장된 명령어를 읽어 들이고, 읽어 드린 명령어를 해석하고, 실행함.
-
내부 구성 요소
3. 보조기억장치
- 하드디스크, SSD, USB 메모리, CD-ROM
- 전원이 꺼져도 저장된 내용을 잃지 않음
4. 입출력장치
- 마이크, 스피커, 프린터, 마우스, 키보드 등
- 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치
💡 보조기억장치는 관점에 따라 입출력장치의 일종으로 볼 수 있다.
5. 메인 보드와 시스템 버스
- 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결 단자 있음
- 버스: 메인보드 내부 버스를 통해 메인보드에 연결된 부품들은 서로 정보를 주고받을 수 있음.
- 시스템버스: CPU, 메모리, 보조기억장치, 입출력 장치를 연결하는 가장 중요한 버스
- 주소 버스: 주소를 주고받는 통로
- 데이터 버스: 명령어와 데이터를 주고받는 통로
- 제어 버스: 제어 신호를 주고받는 통로
chapter 02 데이터
2-1 0과 1로 숫자를 표현하는 방법
✔️ [참고] Word란?
→ 64비트 워드 CPU
- CPU가 한 번에 처리할 수 있는 데이터 크기
- WORD에 대해 (CPU가 한번에 다루는 데이터의 단위란?)
- 비트의 묶음을 부르는 이름
| 이름 | 비트 개수 |
|---|---|
| nibble | 4 |
| byte | 8 |
| half word | 16 |
| word | 32 |
| double word | 64 |
2의 보수(two's complement)
- 사전적인 의미: 어떤 수를 그보다 큰 에서 뺀 값
- 모든 이진수의 0과 1을 뒤집는다 → 거기에 1을 더한다.
- flag: 이진수만 봐서는 이게 음수인지 양수인지 구분하기가 어렵다. 그걸 컴퓨터가 이해하기 위한 부가 정보. 플래그 레지스터.
16진수
모두를 위한 컴퓨터 과학(CS50 2019) [5.메모리] 참고
- 이진법으로는 숫자의 길이가 너무 길어진다
- 그래서 컴퓨터의 데이터를 표현할 때 많이 사용
- 이진수 <-> 십육진수 변환이 무척 쉽다.
2-2 0과 1로 문자를 표현하는 방법
character set
- 컴퓨터가 이해할 수 있는 문자 모음encoding
- 코드화하는 과정 - 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정decoding
- 코드를 해석하는 과정 - 0과 1로 표현된 문자 코드를 문자로 변환하는 과정
1. 아스키 코드
- ASCII(American Standard Code for Information Interchange)
- 초창기 문자 집합, 영어알파벳/아라비아 숫자/일부 특수 문자
- 7bit → , 128개의 문자
- 하나의 아스키 문자를 나타내기 위해 8비트를 사용합니다. 여기서 1비트는 parity bit. 오류 검출을 위해 사용되는 비트(실제 문자 표현에는 사용되지 않음)
2. EUC-KR(한글 인코딩)
- 완성형 인코딩: 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 방식
- 한글 한 글자를 표현하려면 16bit가 필요
- 네 자리 십육진수로 나타낼 수 있다.
- 2300여개 한글 표현 가능
- 쀍, 쀓, 믜는 표현할 수 없다. → 모든 한글을 표현할 수 없다는 것 때문에 문제가 발생함. → 이 문제를 해결하려고 CP949(Code Page 949). 하지만, 한글을 모두 표현하지 못함.
모든 언어, 특수문자까지 통일된 문자 집합 & 인코딩 방식이 있다면?
3. 유니코드와 UTF-8
- 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식
- 한글, 영어, 화살표 같은 특수 문자, 이모티콘 모두
- 현재 제일 많이 사용함
- UTF = Unicode Trasformation Format
- UTF-8: 통상 1바이트부터 4바이트까지의 인코딩 결과
- 직접 인코딩 해보기: https://onlinetools.com/utf8/convert-utf8-to-binary
chapter 03 명령어
3-1 소스 코드와 명령어
- 참고: 모두를 위한 컴퓨터 과학(CS50 2019) [3.배열]
💡 저급 언어로 개발할 일이 없지 않나요?
하드웨어와 밀접하게 맞닿아 있는 프로그램을 개발하는 임베디드 개발자, 게임 개발자, 정보보안 분야는 어셈블리어를 많이 이용한다.
컴파일 언어
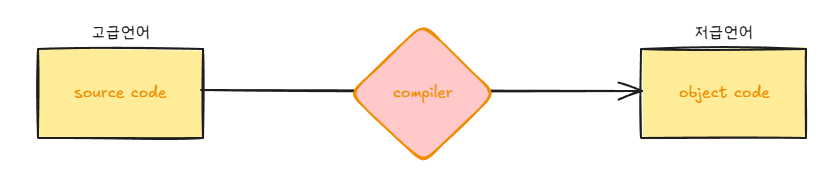
- 소스 코드에 오류가 하나라도 있으면 코드 전체가 실행되지 않는다.
인터프리터 언어
- 인터프리터에 의해 한 줄씩 실행
- 소스 코드 전체가 저급 언어로 변환되기까지 기다릴 필요 없음
- 소스 코드에 오류가 발생하면 오류 발생 전까지의 코드는 실행된다.
참고 사이트
https://godbolt.org/
소스 코드로 어셈블리어를 볼 수 있는 사이트다. WOW
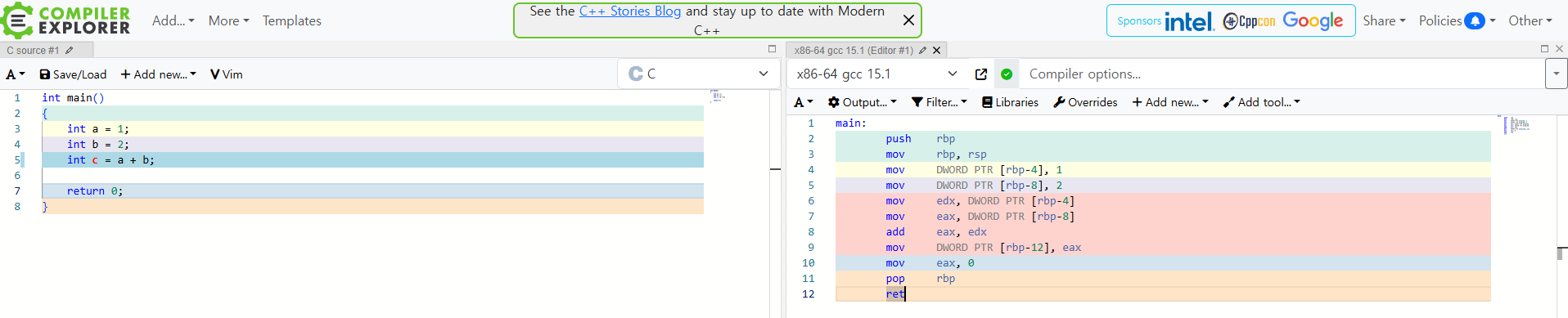
3-2 명령어의 구조
무엇을 대상으로, 무엇을 수행하라
연산 코드와 오퍼랜드
- 명령어: 연산코드와 오퍼랜드로 구성

| 연산 코드(operation code) | 오퍼랜드(operand) |
|---|---|
| 연산 코드 필드 명령어가 수행할 연산 연산자 | 오퍼랜드 필드 연산에 사용할 데이터가 저장된 위치 피연산자 |
오퍼랜드(주소 필드)
- 연산에 사용할 데이터
- 연산에 사용할 데이터가 저장된 위치 → 데이터보다 위치를 훨씬 많이 담는다. (그래서 주소 필드라고도 부름)
- why? 주소 명령어에서 표현할 수 있는 데이터 크기가 제한되기 때문. 데이터 자체를 명령어로 담는 것보다 주소를 통해 참조하는 것이 훨씬 유연하고 재사용하기 좋다.
- 숫자, 문자(연산에 사용할 데이터), 메모리, 레지스터 주소
| 연산 코드(operation code) | 오퍼랜드 | 오퍼랜드 | 설명 |
|---|---|---|---|
| mov | eax | 0 | 오퍼랜드가 2개, 2-주소 명령어 |
| pop | rbq | 오퍼랜드 1개, 1-주소 명령어 | |
| ret | 오퍼랜드 하나도 없음, 0-주소 명령어 |
연산코드 (유형정도만 파악하자)
유형(CPU마다 종류와 생김새가 다름)
-
데이터 전송
- MOVE
- STORE
- LOAD(FETCH): 메모리에서 CPU로 데이터를 가져와라
- PUSH: 스택에 데이터를 저장해라
- POP: 스택의 최상단 데이터를 가져와라
-
산술/논리 연산
- ADD/SUBTRACT/MULTIPLY/DIVIDE
- INCREMENT/DECREMENT: 오퍼랜드에 1 더하라/빼라
- AND/OR/NOT
- COMPARE
-
제어 흐름 변경
- JUMP: 특정 주소로 실행 순서를 옮겨라
- CONDITIONAL JUMP: 조건이 부합할 때(if 문과 같이) 특정 순서로 실행 순서를 옮겨라
- HALT: 프로그램의 실행을 멈춰라
- CALL: 되돌아올 주소를 저장한 채 특정 주소로 실행 순서를 옮겨라
- RETURN: CALL 을 호출할 때 저장했던 주소로 돌아가라
-
입출력 제어
- READ(INPUT)
- WRITE(OUTPUT)
- START IO
- TEST IO
주소 지정 방식(addressing modes)
연산에 사용할 데이터가 저장된 위치를 찾는 방법
유효 주소를 찾는 방법
- 유효주소(effective address): 연산의 대상이 되는 데이터가 저장된 위치
- 즉시 주소 지정 방식(immadiate addressing mode): 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식. 표현할 수 있는 데이터의 크기가 작아지지만 이하 주소 지정 방식들보다 빠르다.
- 직접 주소 지정 방식(direct addressing mode): 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
- 간접 주소 지정 방식(indirect addressing mode): 유효 주소의 주소를 오퍼랜드 필드에 명시하는 방식. 두 번의 메모리 접근이 필요하므로 일반적으로 느림.
- 레지스터 주소 지정 방식(register addressing mode): 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방식. CPU 외부에 있는 메모리보다 내부에 있는 레지스터에 접근하는 게 더 빠르다. 다만, 직접 주소 지정방식처럼 표현할 수 있는 크기의 제한이 생긴다.
- 레지스터 간접 주소 지정 방식(register indirect addressing mode): 연산에 사용할 데이터를 메모리에 저장하고 그 유효 주소를 저장한 레지스터를 오퍼랜드에 명시하는 방식. 간접 주소 지정 방식보다 빠르다.
숙제
1. 기본 숙제
확인문제 (p51)
- 프로그램이 실행되려면 반드시 (메모리)에 저장되어 있어야 합니다.
확인문제 (p65)
- 1101(2) 의 음수를 2의 보수로 표현하면, 0011(2)
2. 추가 숙제
p. 100의 스택과 큐의 개념을 정리하기
- 스택: 한 쪽 끝이 막혀있는 통과 같은 구조
- 후입선출(LIFO: Last In First Out)
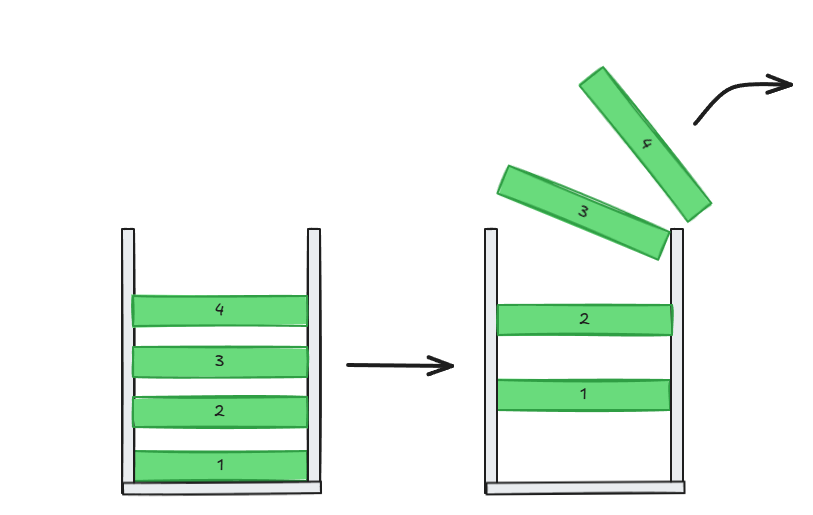
- 큐: 양 쪽 끝이 뚫려있는 통과 같은 구조
- 선입선출(FIFO: First In, First Out)
[미리보기]운영체제의 메모리 관리
물리적인 메모리 크기보다 큰 프로그램을 어떻게 실행할 수 있을까?
- 후에 운영체제에서 만나게 될 내용들이다. 지금은 느낌만.
- 페이징 기법: 컴퓨터가 메인 메모리에서 사용하기 위해 2차 기억 장치로부터 데이터를 저장하고 검색하는 메모리 관리 기법
- 스와핑(swapping)
03 추가: c 언어의 컴파일 과정
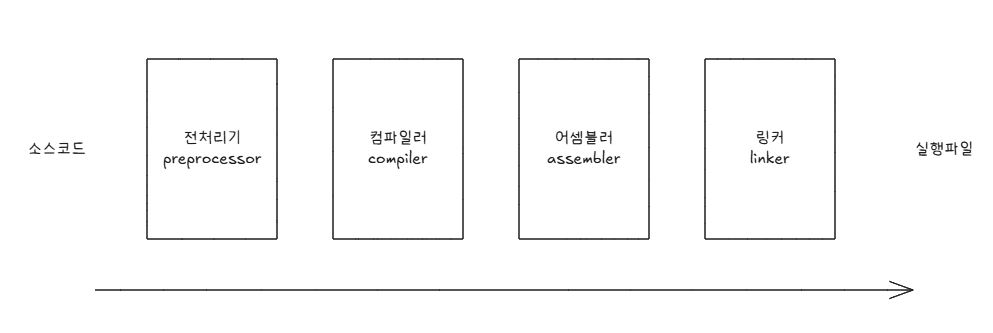
전처리과정
- 본격적으로 컴파일하기 전에 처리할 작업들
- 외부에 선언된 다양한 소스 코드, 라이브러리 포함(ex.#include)
- 프로그래밍의 편의를 위해 작성된 매크로 변환(ex.#define)
- 컴파일할 영역 명시(ex. #if, #ifndef)
gcc -E 소스코드명 -o 파일명.i🤭 신기컴파일러
- 전처리가 완료되어도 여전히 소스 코드
- 전처리가 완료된 소스 코드를 저급 언어(어셈블리 언어)로 변환
gcc -S 소스코드명 -o 파일명.s어셈블(assembling)
gcc -o object.o 파일명.s- 어셈블리어를 기계어로 변환
- 목적 코드를 포함하는 목적 파일이 됨
- 오브젝트 파일 보는 법
xxd 오브젝트파일.o
xxd 오브젝트파일.o | less #(한 화면씩 보게 하는 명령어)
- less: 파일이 크거나 내용을 천천히 분석하고 싶을 때 써보자.
- 목적 파일과 실행 파일은 둘 다 기계어로 이루어진 파일이지만, 다른 것이다.
- 목적 파일이 링킹 과정을 거쳐야만 실행 파일이 된다.
linking
- 각기 다른 목적 코드들을 하나의 코드로 연결해주는 작업
