
💻 스레드, 코루틴, 동기/비동기, 블로킹/논블로킹 추후에 꼭 마저 채우기
- 슬쩍 읽고 넘어감 (5.5)
- 스레드 정리 중 (5.13 머리에서 김이 난다)
🧐 분명히 그림으로 쉽게 설명하고 있기는 한데.. 지식이 얕아서 소화가 잘 안되는 느낌.
널찍하게 읽고 한 번 더 보면서 추가 정리를 해야 할 것 같다.
1장 프로그래밍 언어부터 프로그램 실행까지, 이렇게 진행된다
1.2 컴파일러는 어떻게 작동하는 것일까?
컴파일러: 고수준 언어를 저수준 언어로 번역하는 프로그램
1.2.1 컴파일러는 그저 일반적인 프로그램일 뿐, 대단하지 않다
1.2.2 각각의 토큰 추출하기
- 컴파일러는 먼저 각 항목을 잘게 쪼갠다.
- token: 이렇게 각 항목에 추가로 정보를 결합한 것
컴파일러의 어휘 분석(Lexical Analysis)
int a = 1;
int b = 2;
while ( a < b )
{
b = b - 1;
}| 순서 | 어휘(lexeme) | 토큰(token) | 토큰 종류(category) |
|---|---|---|---|
| 1 | int | INT_KEYWORD | 키워드 |
| 2 | a | IDENTIFIER(a) | 식별자 |
| 3 | = | ASSIGN_OP | 연산자(대입) |
| 4 | 1 | INTEGER_LITERAL | 정수 리터럴 |
| 5 | ; | SEMICOLON | 구분자 |
| 6 | int | INT_KEYWORD | 키워드 |
| 7 | b | IDENTIFIER(b) | 식별자 |
| 8 | = | ASSIGN_OP | 연산자(대입) |
| 9 | 2 | INTEGER_LITERAL | 정수 리터럴 |
| 10 | ; | SEMICOLON | 구분자 |
| 11 | while | WHILE_KEYWORD | 키워드 |
| 12 | ( | LPAREN | 구분자(왼쪽 소괄호) |
| 13 | a | IDENTIFIER(a) | 식별자 |
| 14 | < | LT_OP | 연산자(비교: less than) |
| 15 | b | IDENTIFIER(b) | 식별자 |
| 16 | ) | RPAREN | 구분자(오른쪽 소괄호) |
| 17 | { | LBRACE | 구분자(왼쪽 중괄호) |
| 18 | b | IDENTIFIER(b) | 식별자 |
| 19 | = | ASSIGN_OP | 연산자(대입) |
| 20 | b | IDENTIFIER(b) | 식별자 |
| 21 | - | SUB_OP | 연산자(뺄셈) |
| 22 | 1 | INTEGER_LITERAL | 정수 리터럴 |
| 23 | ; | SEMICOLON | 구분자 |
| 24 | } | RBRACE | 구분자(오른쪽 중괄호) |
1.2.3 토큰이 표현하고자 하는 의미
- parsing(해석): 어휘 분석을 통해 생성된 토큰들의 나열을 받아들여, 언어의 문법 규칙에 따라 구조를 분석한다. 구문 트리(parse tree) 또는 추상 구문 트리(AST: Abstract Syntax Tree)를 만드는 과정이다.
1.2.4 생성된 구문 트리에 이상은 없을까?
- sementic analysis(의미 분석): 파싱(구문 분석) 단계에서 만든 AST에 "실제 의미가 올바른지" 검증/보강하는 단계
1.2.5 구문 트리를 기반으로 중간 코드 생성하기
- Intermediate Representation Code, IR code(중간 코드) 생성
a = 1
b = 2
goto B
A: b = b - 1
B: if a < b goto A1.2.6 코드 생성
- 컴파일러가 앞 중간 코드를 어셈블리어 코드로 변환
.text
.globl _start
_start:
# a = 1
movl $1, %eax
# b = 2
movl $2, %ebx
# goto B
jmp B
A:
# b = b - 1
decl %ebx
B:
# if (a < b) goto A
cmpl %ebx, %eax # compare %eax and %ebx (a - b)
jl A # jump if less (signed)
# exit(0)
movl $60, %eax # syscall: sys_exit
xorl %edi, %edi # status = 0
syscall
1.3 링커의 말할 수 없는 비밀
1.3.1 링커는 이렇게 일한다
컴파일러가 생성한 대상 파일 여러 개를 하나로 묶어 하나의 최종 실행 파일 생성
- 책으로 예를 들자면, 저자 여러 명이 각각 특정 부분을 맡아 chapter별로 따로 집필하고 개별 장을 묶어 책 한 권으로 출판하는 것과 비슷하다.
1.3.2 심벌 해석: 수요와 공급
- 심벌: 전역 변수와 함수의 이름을 포함하는 모든 변수 이름. (지역 변수는 관심 대상 아님)
- 링커는 대상 파일에서 참조하고 있는 각각의 모든 외부 심벌마다 대상의 정의가 반드시 존재하는지, 단 하나만 존재하는지 확인
1.3.3 정적 라이브러리, 동적 라이브러리, 실행 파일
- static library: 리눅스에서 확장자 .a, 윈도우에서는 .lib
- 실행 파일에 라이브러리 내용을 모두 복사
- dynamic library = shared library = dynamic linked library: 리눅스에서는 확장자 .so, 접두사는 lib. 윈도우에서는 DLL파일.
- 참조된 동적 라이브러리 이름, 심벌 테이블, 재배치 정보 등 필수 정보만 실행 파일에 포함
1.4 컴퓨터 과학에서 추상화가 중요한 이유
추상화의 목적
1. 세부 구현은 숨기고 "무엇을 하는가(what)"만 드러내어 이해와 설계를 단순화
2. 모듈화 & 재사용성: 서로 독립적인 모듈로 나눠서 설계/개발/테스트
3. Encapsulation: 내부 구현을 바꾸더라도 외부 영향 최소화
1.4.1 프로그래밍과 추상화
- 예컨대, 객체 지향 언어의 주요 장점: 다형성(polymorphism), 추상 클래스(abstract class) -> 프로그래머가 손쉽게 추상화 할 수 있음
1.4.2 시스템 설계와 추상화
- 컴퓨터 시스템은 기본적으로 추상화라는 기반 위에 구축
- 입출력 장치는 file로 추상화되어 있다.
- 실행 중인 프로그램은 프로세스로 추상화
- 물리 메모리와 파일은 가상 메모리로 추상화
- 네트워크 프로그래밍은 socket으로 추상화
2장 프로그램이 실행되었지만, 뭐가 뭔지 하나도 모르겠다
2.1.1 모든 것은 CPU에서 시작된다.
- 메모리에서 명령어(instruction)을 하나 가져온다(dispatch)
- 이 명령어를 실행(execute)한 후 1.로 돌아간다.
2.1.2 CPU에서 운영 체제까지
- CPU는 한 번에 한 가지 일만 할 수 있다.
- 프로그램 B를 실행했다가 이를 잠시 중지하고 다시 프로그램 A의 실행으로 돌아갈 수 있다. 이 때 CPU의 전환 빈도가 충분히 빠르다면 프로그램 A와 프로그램 B가 동시에 실행되는 것처럼 보일 수 있음!
- 상황정보(context): 프로세스(또는 스레드)가 CPU에서 실행되는 시점의 모든 상태(Execution State)
- context switch: 마치 여러 프로세스가 동시에 실행되는 것처럼 보임
1) 현재 context 저장
2) 다음 process context load
3) 실행 재개: 복원된 프로그램 카운터(PC or Instrction Pointer) 위치부터 해당 프로세스 실행 이어감
프로세스 구조체?
운영체제가 한 프로그램의 실행 상태와 자원 사용 정보를 추적/관리하기 위해 쓰는 자료 구조. Process Control Block(PCB), 리눅스 커널은 task_struct와 같은 프로세스 구조체
- process: 운영체제가 관리하는 실행 단위
- PCB: 그 실행 단위에 대한 모든 상태/자원 정보를 담은 조직적인 레코드
- 이 구조체를 이용해 os가 프로그램들을 동시에 관리하고 안전하게 context switching하여 자원을 일관되게 배분/회수 할 수 있음
2.1.3 프로세스는 매우 훌륭하지만, 아직 불편하다
다중 프로세스 프로그래밍(multi-process programming)
- 하나의 애플리케이션을 여러 개의 독립된 프로세스로 나누어 동시에 병렬로 실행되도록 설계/구현하는 기법.
- 진정한 병렬성
- 높은 격리성
- 생성/통신 오버헤드가 크다
- CPU 집약적이고 안정성이 중요한 작업에서 활용
2.1.4 프로세스에서 스레드로 진화
이하 프로세스/ 스레드에 대한 내용은 철학자 문제를 해결할 때 채우는 걸로!! (지금 말고.....)
- 프로세스의 단점: 진입함수(entry function)가 main 함수 하나밖에 없어 프로세스의 기계 명령어를 한 번에 하나의 cpu에서만 실행할 수 있다.
- 공유 프로세스 주소 공간에서 동일한 프로세스에 속한 명령어를 동시에 실행할 수 있다. (하나의 프로세스 안에 여러 실행 흐름이 존재할 수 있음)
- 이 실행 흐름이 -> thread
- 스레드는 프로세스 주소 공간을 공유하므로 프로세스보다 훨씬 가볍고 생성 속도가 빠르다 -> 경량 프로세스(light weight process)
- 스레드가 고성능과 높은 동시성의 기초
2.1.6 스레드 활용 예
thread-per-request
- 요청이 들어올 떄마다 매번 스레드가 생성된다.
- 긴 작업 대상으로 매우 잘 동작
하지만...
1) 스레드의 생성과 종료에 많은 시간을 허비한다
2) 스레드마다 각자 독립된 스택 영역이 필요한데, 많은 수의 스레드를 생성하면 메모리와 기타 시스템 리소스를 너무 많이 소비하게 된다.
3) 스레드 수가 많으면 스레드 간 전환에 따른 부담이 증가한다.
2.1.7 스레드 풀의 동작 방식
- 스레드 여러 개를 미리 생성해 두고, 스레드가 처리할 작업이 생기면 해당 스레드에 처리를 요청한다.
producer consumer pattern
- 추후 추가 정리
2.1.8 스레드 풀이 스레드 수
cpu intensive task
- 과학 연산, 행렬 연산 등 작업을 처리할 때 외부 입출력에 의존할 필요가 없이 처리할 수 있는 작업
input/output intensive task
- 연산 부분이 차지하는 시간은 많지 않지만 디스크/네트워크 입출력 등에 소비하는 작업
2.2 스레드 간 공유되는 프로세스 리소스
프로세스와 스레드의 차이점은 무엇일까?
프로세스는 운영 체제가 리소스를 할당하는 기본 단위,
스레드는 스케쥴링의 기본 단위 라고 유창하게 외우고 있을 것이다.
그런데, 스레드 간에 어떤 프로세스 리소스를 공유하고 있을까?
공유 리소스는 무엇을 의미하는가?
공유 리소스는 어떤 방식으로 작동할까?
스레드 전용 리소스는 어떤 것이 있을까?
2.2.1 스레드 전용 리소스
1) 스레드는 자신만 사용할 수 있는 스택 영역을 가진다. -> 스레드가 여러 개 있을 때는 여러 스택 존재
2) PC 레지스터: 실행될 명령어 주소를 저장
3) 스택 포인터:스택영역에서 스택 상단 위치 저장
4) CPU가 기계 명령어를 실행할 때의 내부 레지스터의 값
- 위 스레드 전용 리소스를 제외한 나머지는 스레드 간 공유되는 리소스다.
- 스택 영역을 제외한 나머지 영역을 모두 공유
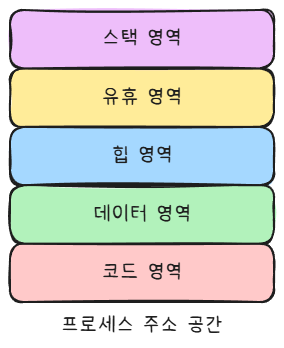
2.2.2 코드 영역: 모든 함수를 스레드에 배치하여 실행할 수 있다.
- 코드영역에는 컴파일 후 생성된 실행 파일의 기계 명령어가 저장된다.
2.2.3 데이터 영역: 모든 스레드가 데이터 영역의 변수에 접근할 수 있다.
- 전역 변수가 저장되는 곳
2.2.4 힙 영역: 포인터가 핵심이다
- malloc과 new 예약어로 요청하는 메모리가 이 영역에 할당
- 모든 스레드는 포인터 s(예시)를 획득하면 해당 포인터가 가리키는 데이터에 접근할 수 있다
2.2.5 스택 영역: 공유 공간 내 전용 데이터
- 실제 구현 측면에서 스택 영역은 엄밀하게 격리된 스레드 전용 공간이 아니다.
- 하나의 스레드가 다른 스레드의 스택 프레임에서 포인터를 가져올 수 있다면 해당 스레드는 다른 스레드의 스택 영역을 직접 읽고 쓸 수 있다.
- 스택영역에는 별도의 보호를 위한 작동 방식이 존재하지 않으므로(프로세스랑 다름)
- 이로 인해, 의도치 않게 다른 스레드에 속한 전용 데이터를 수정해 버그가 발생할 수 있다.(디버깅이 매우 어려움)
2.2.6 동적 링크 라이브러리와 파일
2.2.7 스레드 전용 저장소
- thread local storage
- 각각의 스레드에서 독점점으로 변수를 사용할 수 있다.
- 이 변수들은 모든 스레드에서 접근 가능하지만, 해당 변수는 초기화 후 각각의 스레드가 복사본을 가지게 된다. 고로, 하나의 스레드에서 변수 값을 변경하더라도 다른 스레드에는 영향을 미치지 않는다.
2.3 스레드 안전 코드는 도대체 어떻게 작성해야 할까?
2.3.2 스레드 안전이란?
어떤 코드가 주어졌을 때, 그 코드가 스레드 몇 개에서 호출되든 이 스레드들이 어떤 순서로 호출되든 간에 상관없이 올바른 결과가 나온다면, 이 코드를 스레드 안전이라고 한다.
2.3.3 스레드 전용 리소스와 공유 리소스
[다시 정리]
- 스레드 저장 리소스: 함수의 지역 변수, 스레드의 스택 영역, 스레드 전용 저장소
- 공유 리소스: 그 외 영역(주로 힙 영역, 데이터 영역)
- 공유 리소스를 사용하는 스레드는 반드시 순서를 따라야 하며, 핵심은 공유 리소스를 사용하는 작업이 다른 스레드를 방해할 수 없다.
- 이를 위해 lock, semaphore 등을 사용할 수 있음.
- 공유 리소스 순서를 어떻게 유지할 수 있을까?🧐
2.3.6 전역 변수 사용
- 전역 변수를 사용하는 코드는 반드시 스레드 안전 코드라고는 할 수 없다.
- 하지만, 처음 프로그램이 실행될 때 한 번 초기화되고 나서 모든 코드가 이 변수를 읽기만 한다면(일종에 contant상수처럼 사용) 안전 코드.
2.3.7 스레드 전용 저장소
int global_num = 100;
int func()
{
++global_num;
return global_num;
}위 코드는 스레드 안전이 아니다.
__thread int global_num = 100;
int func()
{
++global_num;
return global_num;
}- __thread: 수식어가 붙으면 스레드 전용 저장소에 배치됨(wow)
- 추가 읽어볼 자료: 블로그
2.3.10 스레드 안전 코드는 어떻게 구현할까?⭐⭐⭐
- 스레드 사이에서 어떤 종류의 리소스를 공유해야 한다면, 반드시 코드의 스레드 안전에 주의를 기울여야 한다.
- 스레드 전용 리소스와 스레드 공유 리소스를 먼저 구분할 필요가 있음.
(반복) 스레드 안전 구현은 스레드 전용 리소스와 스레드 공유 리소스를 중심으로 진행됩니다. 먼저 어떤 것이 스레드 전용 리소스고 어떤 것이 스레드 공유 리소스인지 파악하고, 이어 각 증상에 맞는 약을 처방하면 됩니다.
1) 스레드 전용 저장소(thread local storage): 전역 리소스를 사용해야 하는 경우 스레드 전용 저장소로 선언할 수 있는지 확인. 이런 종류의 변수는 모든 스레드에서 사용할 수 있지만 각 스레드마다 자체 복사본이 있으며, 이를 변경하더라도 다른 스레드에는 영향을 미치지 않는다.
2) 읽기 전용(read-only): 전역 리소스를 반드시 사용해야 한다면 해당 전역 리소스를 읽기 전용으로 사용해도 되는지 확인. 다중 스레드에서는 읽기 전용 전역 리소스를 사용하더라도 스레드 안전 문제가 발생하지 않는다.
3) 원자성 연산(atomic operation): C++ std::atomic 형식의 변수처럼 원자성 연산은 도중에 중단되지 않는다. 따라서 이런 변수에 대한 연산에는 전통적인 방식의 잠금으로 보호가 필요하지 않는다.
4) 동기화 시 상호 배제(mutual exclusion in synchronization): 한 번에 하나의 스레드만 공유 리소스에 접근할 수 있도록 스레드가 접근하는 공유 리소스 순서를 프로그래머가 직접 유지해야 한다? 이 경우 mutex, spin lock, semaphore 등이 사용될 수 있다.
최종 질문
위 스레드는 기본적으로 kernel thread를 의미한다. 스레드의 생성, 스케줄링, 종료를 모두 운영 체제가 수행.
-> 운영 체제에 의존하지 않는 상황에서 직접 스레드를 구현하려면?
스레드보다 더 가벼운 실행 흐름인 코루틴으로 구현할 수 있다.
2.4 프로그래머는 코루틴을 어떻게 이해해야 할까?
coroutine
2.4.4 함수는 그저 코루틴의 특별한 예에 불과하다
- 일반 함수와 다른 점은 자신이 이전에 마지막으로 실행된 위치를 알 수 있다는 점
- 자신이 일시 중지될 때 실행 중인 상태를 저장했다가 저장되었던 상태에서 다시 시작하여 계속 실행
2.4.6 코루틴은 어떻게 구현될까?
코루틴은 왜 필요할까?
-> 프로그래머가 동기 방식 또는 비동기 방식의 프로그래밍을 할 수 있게 한다.
2.8 높은 동시성과 고성능을 갖춘 서버 구현
2.8.1 다중 프로세스
2.5 콜백 함수를 철저하게 이해한다
callback function
