
3주차
- Chapter 06 ~ 08
- p. 185의 확인 문제 3번, p. 205의 확인 문제 1번 풀고 인증하기
- Ch.07(07-2) RAID의 정의와 종류를 간단히 정리해 보기
06 메모리와 캐시 메모리
6-1 RAM의 특징과 종류
RAM의 하드웨어적 특성과 종류
RAM의 특징
- 휘발성 저장장치(volatile memory)
- 일반적으로 실행할 대상을 저장함
cf) 보조기억장치: 비휘발성 저장장치(non-volatile memory), 일반적으로 보관할 대상을 저장함.
RAM의 용량과 성능
- RAM의 용량이 적다면, 보조 기억 장치에서 실행할 프로그램을 가져오는 일이 잦아지면서 실행시간이 길어진다.
- RAM 용량이 크면 많은 프로그램들을 동시에 빠르게 실행하는 데 유리하다. 단, 용량이 필요 이상일 때, 속도가 그에 비례하여 무조건 증가하지는 않는다.
RAM의 종류
DRAM(Dynamic RAM)

- 시간이 지나면 저장된 데이터가 점차 사라지는 RAM
- 일반적으로 사용하는 메모리
- 주기억장치(RAM)
- 소비전력이 낮고, 저렴, 집적도가 높아 대용량 설계에 유리함.
집적도: 모아 쌓음, 압축률
SRAM(Static RAM)

- 시간이 지나도 저장된 데이터가 사라지지 않는다.(전원이 공급되는 동안, 비휘발성 메모리는 아니다.)
- 주기적으로 데이터 재활성화 필요 없음
- 캐시 메모리
- 일반적으로 DRAM보다 속도가 더 빠르다.
SDRAM(Synchronous Dynamic RAM)

- 클럭 신호와 동기화된 램
- 클럭에 맞춰 동작하며 클럭마다 CPU와 정보를 주고 받을 수 있는 DRAM
DDRRAM(Double Data Rate SDRAM)
- 최근 흔히 사용되는 RAM → DDR4 SDRAM
- 대역폭(data rate)을 넓혀 속도를 빠르게 만드는 SDRAM
- 대역폭: 데이터를 주고받는 길의 너비
- DDR SDRAM은 SDRAM의 대역폭의 2배
- DDR2 SDRAM은 SDRAM의 대역폭의 4배
- DDR3 SDRAM은 SDRAM의 대역폭의 8배
- DDR4 SDRAM은 SDRAM의 대역폭의 16배
참고: DDR5 기존의 DDR보다 용량과 대역폭 향상, 전압은 낯춤. 본격적 보급은 21년도
6-2 메모리의 주소 공간
물리 주소, 논리 주소
이 두 주소의 개념과 차이, 두 주소 간의 변환 방법
물리 주소와 논리 주소
물리 주소(physical address)
- 정보가 실제로 저장된 하드웨어상의 실제 주소
논리 주소(logical address)
- 실행 중인 프로그램 각각에게 부여된 0번지부터 시작되는 주소
물리 주소와 논리 주소의 변환
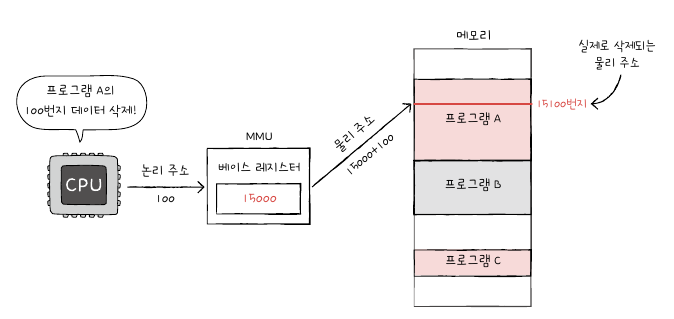
- 메모리 관리 장치(MMU: Memory Management Unit)
- CPU와 주소 버스 사이에 위치함
메모리 보호 기법
- 한계 레지스터(limit register):
- 논리 주소 범위를 벗어나는 명령어 실행을 방지하고 실행 중인 프로그램이 다른 프로그램에 영향을 받지 않도록 보호하는 방법
- 논리 주소의 최대 크기 저장
- 베이스 레지스터 값 프로그램 물리 주소 베이스 레지스터 값 + 한계 레지스터 값
- 만약, CPU가 한계 레지스터보다 높은 논리 주소에 접근하려고 하면,
인터럽트(트랩)를 발생시켜 실행을 중단한다.
6-3 캐시 메모리
저장 장치 계층 구조를 통해 저장 장치의 큰 그림 그리기, 캐시 메모리
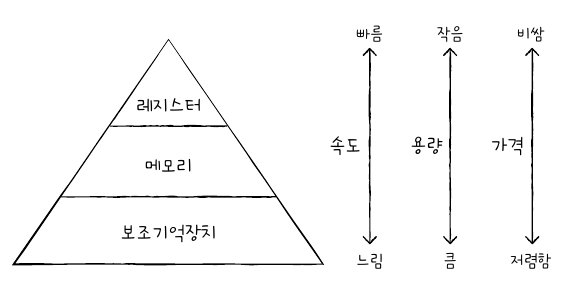
저장 장치 계층 구조(memory hierarchy)
캐시 메모리(cache memory)
- CPU와 메모리 사이에 위치하고, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치
- L1, L2, L3 캐시
- 일반적으로 L1, L2 캐시는 코어 내부, L3은 코어 외부에 위치
- → 이 순으로 용량은 커지고 속도는 느려진다.
참조 지역성 원리
-
캐시 히트: 자주 사용될 것으로 예측한 데이터가 실제로 들어맞아 캐시 메모리 내 데이터가 CPU에서 활용될 경우
-
캐시 미스: 예측이 틀려 메모리에서 필요한 데이터를 직접 가져와야 하는 경우
-
캐시 적중률
캐시 히트 개수 / (캐시 히트 개수 + 캐시 미스 개수) -
CPU가 사용할 법한 데이터는 어떻게 알 수 있을까?
-
참조 지역성의 원리(locality of referencem principle of locality)
1.CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향(temporal locality).예를 들어 변수.
2.CPU는 접근한 메모리 공간 근처를 접근하려는 경향(spatial locality)
07 보조기억장치
7-1 다양한 보조기억장치
하드 디스크, 플래시 메모리
하드 디스크(HDD: Hard Disk Drive)
자기 디스크(magnetic disk)

출처: hard disk 영어 위키
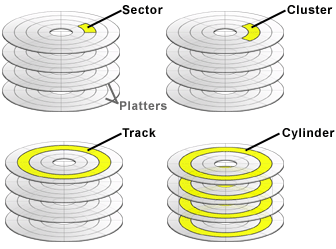
출처: 블로그
- 하드디스크가 저장된 데이터에 접근하는 시간
- 탐색 시간(seek time) 접근하려는 데이터가 저장된 트랙까지 헤드를 이동시키는 시간
- 회전 지연(rotational time) 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간(transfer time): 하드디스크와 컴퓨터 간에 데이터를 전송하는 시간
탐색 시간과 회전 지연을 단축시키기 위해 플래터를 빨리 돌려 RPM을 높이는 것도 중요하지만, 참조 지역성 즉, 접근하려는 데이터가 플래터 혹은 헤드를 조금만 옮겨도 접근할 수 있는 곳에 위치해 있는 것도 중요하다.
How do Hard Disk Drives Work? 💻💿🛠
플래시 메모리(flash memory)
- USB 메모리, SD 카드, SSD 모두 플래시 메모리 기반의 보조기억장치
- 전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반의 저장장치
플래시 메모리의 종류
- 하나의 셀에 몇 비트를 저장할 수 있느냐에 따라 종류가 나뉜다.
- SLC 타입: 하나의 셀에 1비트
- 한 셀로 두 개의 정보(0,1) 표현
- 빠른 입출력
- 수명이 긴 편
- 용량 대비 가격이 높다.
- 기업에서 데이터를 읽고 쓰기가 매우 많을 때, 고성능 빠른 저장 장치가 필요한 경우 사용
- MLC 타입: 하나의 셀에 2비트
- 한 셀로 4 개의 정보 표현
- TLC 타입: 하나의 셀에 3비트
- 한 셀로 8개의 정보 표현
- 수명과 속도가 떨어지지만, 용량 대비 가격이 저렴하다.
- 시중에서 많이 사용되는 플래시 메모리 저장 장치들은 MLC, TLC 타입이다.
| 구분 | SLC | MLC | TLC |
|---|---|---|---|
| 셀당 bit | 1bit | 2bit | 3bit |
| 수명 | 길다 | 보통 | 짧다 |
| 읽기/쓰기 속도 | 빠르다 | 보통 | 느리다 |
| 용량 대비 가격 | 높다 | 보통 | 낮다 |
가비지 컬렉션(garbage colleciton) ❓
- 플래시 메모리의 단위
셀(cell) ⊂ 페이지(page) ⊂ 블록(block) ⊂ 플레인(plane) ⊂ 다이(die) - 페이지의 상태
- Free
- Valid: 유효한 데이터를 저장하고 있는 상태
- Invalid: 유효하지 않은 데이터(쓰레기값)을 저장하고 있는 상태
- 플래시 메모리는 덮어쓰기가 불가능, valid 상태에서 새 데이터 저장 x
- 가비지 컬렉션: 유효한 페이지들만을 새로운 블록으로 복사, 기존의 블록을 삭제하는 가능
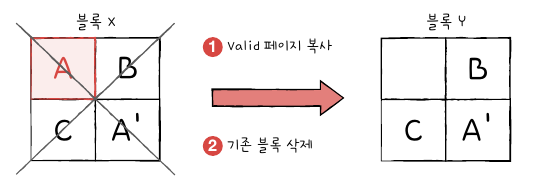
⬆️ 좀 더 알아보기
7-2 RAID의 정의와 종류 ❓
보조기억장치를 더욱 안전하고 빠르게 활용하는 방법, RAID
RAID의 정의
- Redundant Array of Independent Disks
- 데이터의 안정성 혹은 높은 성능을 위해 여러 개의 물리적 보조 기억장치를 마치 하나의 논리적 보조 기억장치처럼 사용하는 기술
- 여러 개의 하드 디스크나 SSD를 마치 하나의 장치처럼 사용
RAID의 종류
- 가장 대중적인 RAID0, RAID1, RAID4, RAID5, RAID6
- 레이드 혼합 방식(Nested RAID)
- 예) RAID 0, RAID 1 혼합 → RAID 10
RAID 0
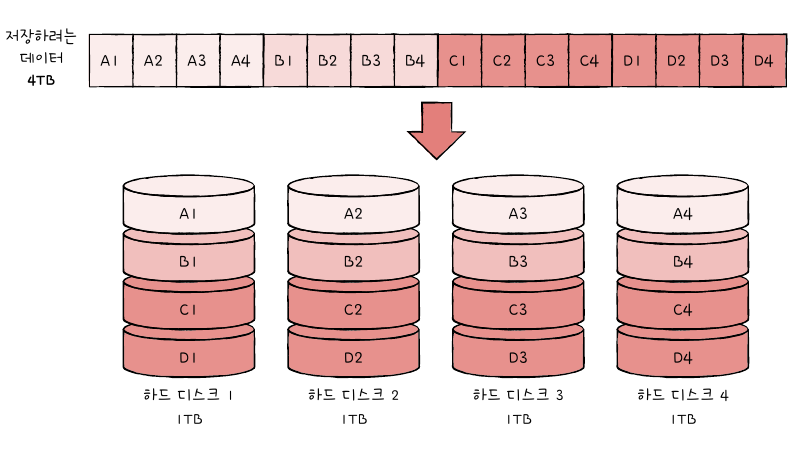
- stripe: 줄무늬처럼 분산되어 저장된 데이터
- striping: 분산하여 저장하는 것
- 데이터가 스트라이핑 되면 저장된 데이터를 읽고 쓰는 속도가 빨라진다.
- 단점: 하드 디스크 중 하나에 문제가 생긴다면 모든 하드 디스크의 정보를 읽는데 문제가 발생할 수 있음
RAID 1
- 복사본을 만드는 방식(mirroring)
- 장점: 복구가 매우 간단하다
- 단점: 하드 디스크 개수가 한정되었을 때 사용 가능한 용량이 줄어든다
RAID 4
- RAID 1 처럼 완전한 복사본을 만드는 대신 오류를 검출하고 복구하기 위한 정보를 저장한 장치를 두는 방식
- 페리티 비트(parity bit)
- 나머지 장치들의 오류를 검출/복구
- 본래 오래 검츌용 정보지만, RAID에서는 오류 복구도 가능
- 단점: 새로운 데이터가 저장될 때마다 페리티를 저장하는 디스크에도 데이터를 쓰게 됨. 고로, 병목 현상 발생 문제
RAID 5
- 페리티 정보를 분산하여 저장하는 방식, RAID 4의 병목 현상 해소
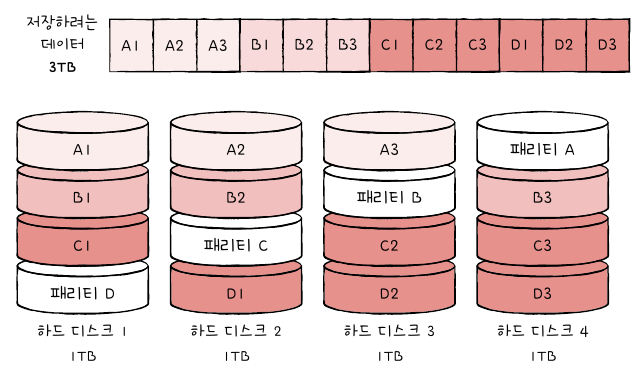
RAID 6
- 기본적으로 RAID 5와 같으나, 두 개의 다른 패리티를 두는 방식
⬆️ 복구에 대해서 찾아보기

수학을 사랑하는 애독자📚 Stop dreaming. Start living. - 'The Secret Life of Walter Mitty'