Quantization
- 기존 high precision(일반적으로 fp32)의 신경망 wwights와 activation을 더 적은 bit(low precision)으로 변환하는 것.
- Post Training Quantization (PTQ)
: 학습 후에 quantization parameter(scale,shift)를 결정 - Quantization Aware Training (QAT): 학습과정에 quantization을 emulate함으로써, 성능하락을 완화.
- Quantization 방법 선택
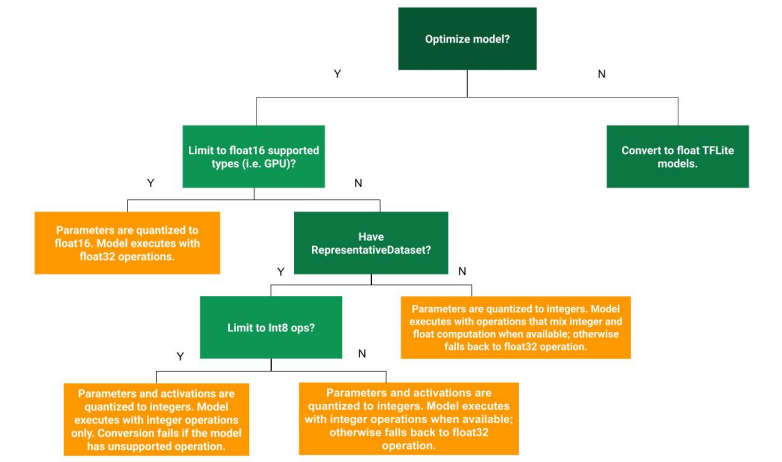
- workflows
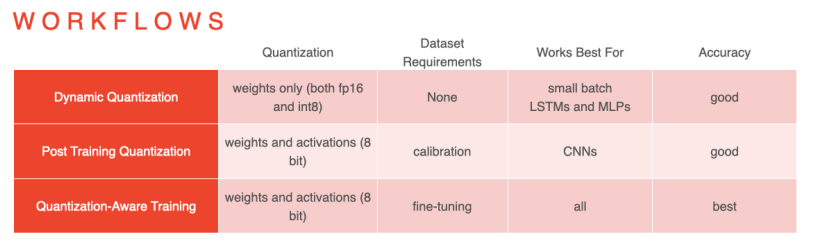
PTQ
- Dynamic range quantization(weight only quantization): weight만 quantize(8bit)하고 추론시 floating point로 변환하여 수행.
- 별도의 calibration(validation)데이터가 필요하지 않음
- 모델 용량 축소 (1/4)
- 실제 연산은 floating으로..(단점)
- Full integer quantization(weight and activation quantization): weight와 더불어 모델의 입력 데이터, activation들 또한 quantize.
- TensorRT(NVIDIA)
- 모델의 용량 축소(1/4)
- 더 적은 메모리 사용량, cache 재사용성 증가
- 빠른연산
- 하지만, activation parameter를 결정하기위해 calibration데이터가 필요
- Float 16 quantization: fp32 -> fp 16
- 모델 용량 축소(1/2)
- 적은 성능 저하
- GPU상의 빠른 연산
- CPU상에서는 fixed point만큼의 연산속도 향상이 없음
QAT
: 학습과정에서 quantization을 emulate하여 추론시에 발생하는 quantization error를 training 시점에 반영하는 방법.
- 이반적인 방법으로 학습 후 fine-tuning으로 QAT적용
- 학습과정에 emulate된 quantization 파라미터를 inference에도 사용
- PTQ보다는 성능하락이 적음.
- 학습과정
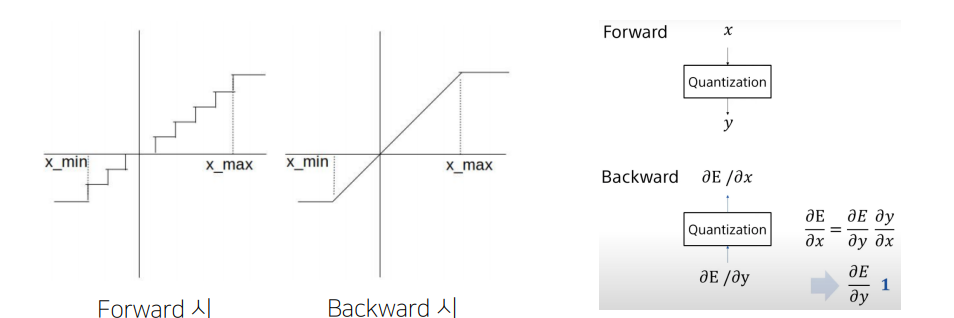
- 학습 과정 중 quantization을 적용하고, 다시 floating point로 변환함 (backprop을 계산하기 위해서)
- IN-Out에 대한 gradient를 linear로 가정(stragiht-through estimator)함으로써 네트워크 학습을 진행

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)