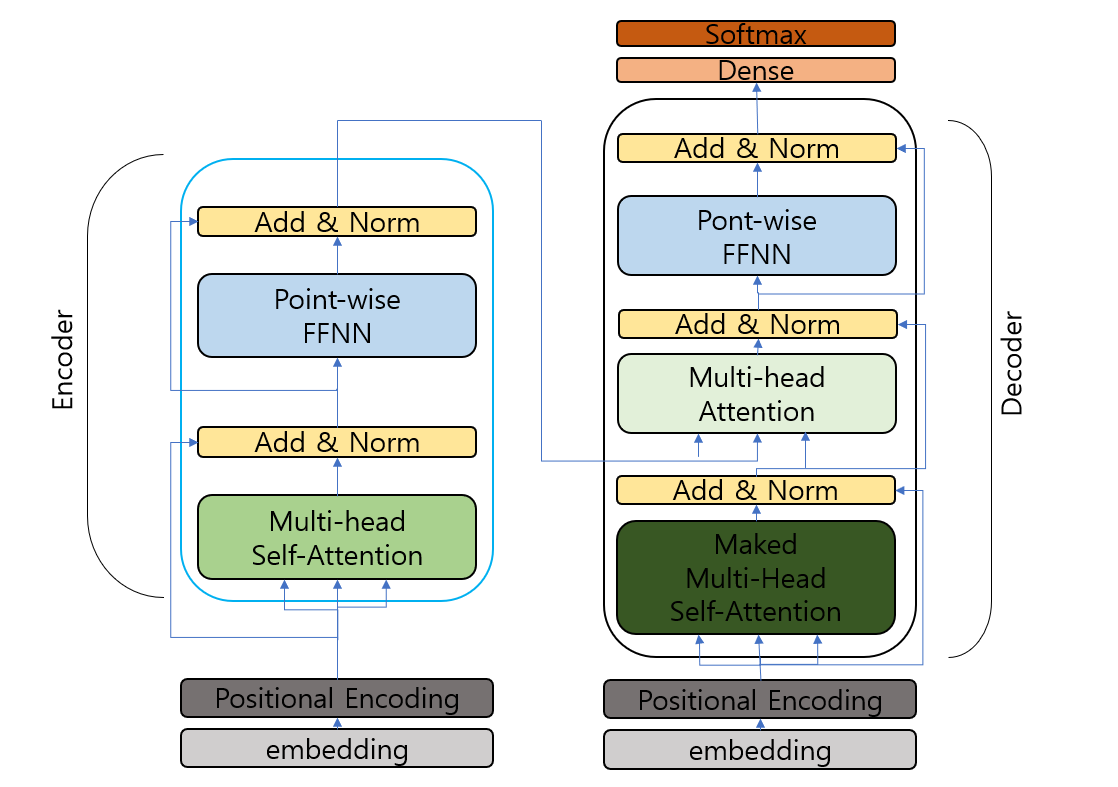
Transformer
- RNN을 사용하지 않고, 인코더와 디코더, 그리고 인코더에서 정보가 손실될 수 있음을 보완한 어텐션 구조로 이루어진 seq2seq모델.
구성
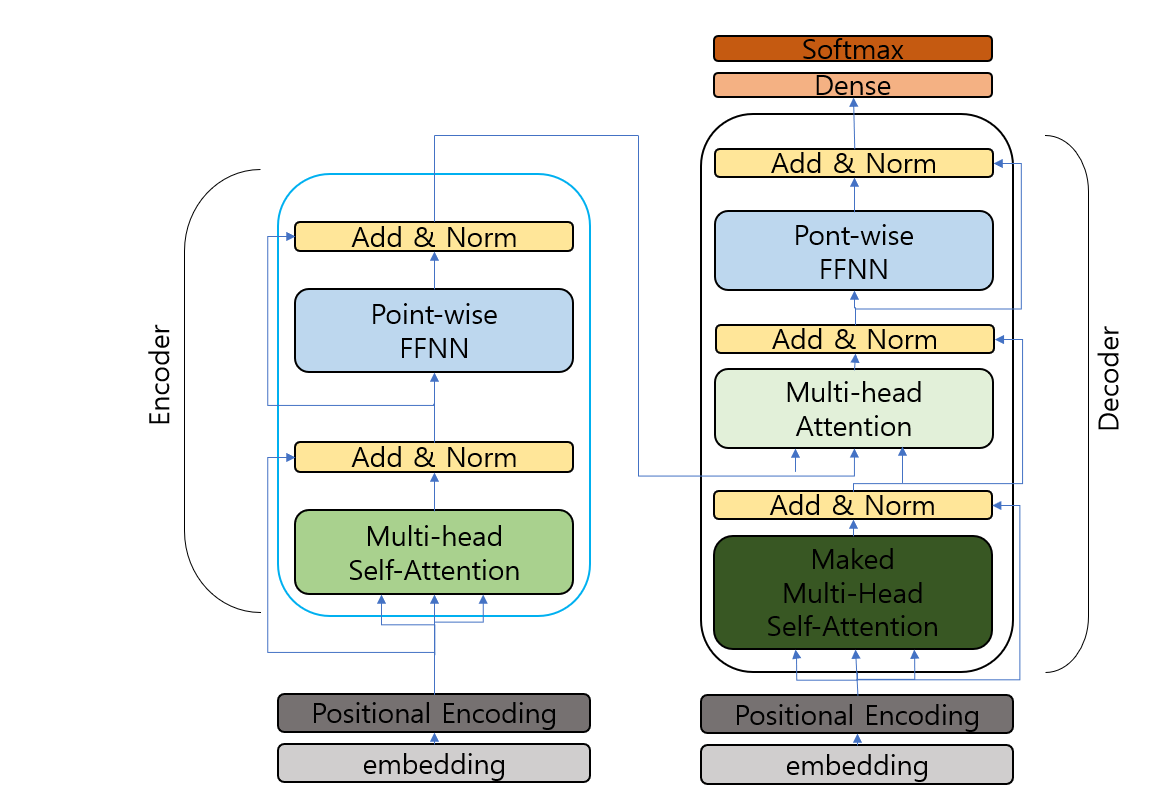
(오타 정정: Maked -> Masked)
- Ecoders & Decoders
- Encoder (N개): 입력 sequence를 하나의 벡터로 압축.
- Decoder (N개): 출력된 벡터를 다시 sequence로 변환.
- Positional Encoding
: RNN은 단어를 순차적으로 입력받았다면, transformer는 위치정보를 가진다. 따라서 각 단어의 임베딩 벡터에 positional information을 합쳐 입력으로 사용한다. - Attention
- Encoder Self-Attention (Encoder)
- Masked Decoder Self-Attention (Decoder)
- Encoder-Decoder Attention (Decoder)
Attention Machanism
: Attention 함수는 주어지는 Query에 대해서 모든 key와 유사도를 구한다. 이후 해당 유사도를 가중치로 하여 key와 매핀되어 있는 각각의 value에 반영해주고 다시 가중합하여 리턴한다.
- Query, Key, Value
- 입력되는 각 단어 벡터를 가중치 행렬을 곱하여 부터 Q,K,V벡터를 얻는다. 초기입력보다 작은 차원의 벡터 형태(논문: 초기 입력 벡터 512, Q,K,V 64).
- Query : 디코더의 이전 레이어 hidden state, t시점의 디코더 셀에서의 은닉상태
- Key : 인코더의 output state, 모든 시점의 인코더 셀의 은닉 상태들
- Value : 인코더의 output state, 모든 시점의 인코더 셀의 은닉상태들
Dot-Product Attention
1. Attention Score 구하기
- Attenstion Score: 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉상태() 각각이 현시점의 디코더의 은닉상태()와 얼마나 유사한지 판단하는 수치.
2. Attention Distribution 구하기
- 에 Softmax를 적용하여, 모든값을 합하면 1이 되는 확률 분포를 얻어낸다. 그리고 각각을 Attention Weight라고 정의한다.
3. Attention Value 구하기
- 각 인코더의 어텐션 가중치와 은닉상태를 가중합.(=context vector)
4. Concatenate Attention value & hidden state
5. 출력층 연산의 입력이 되는 계산하기
6. 예측벡터 구하기
Scaled Dot-Product Attention
1. Attention Score 구하기
2. Attention Distribution 구하기
3. Attention Value 구하기
Multi-Head Attention
- 한번의 Attention보다 여러번 병렬로 사용하는 것이 다른 시각으로 정보들을 수집할 수 있다는 장점으로 더 효과적.
- 위의
Padding Mask
- 입력문장의 <PAD>토큰을 없애기 위해서, 어텐션 스코어 행렬의 마스킹 위치에 아주 작은 음수 값을 넣는다.
Position-wise FFNN(Feed forward Neural Network)
- 인코더와 디코더에서 공통적으로 가지고 있는 서브층.fully-connected.
Look-Ahead Mask
- 디코더에서 현재시점의 예측이 현재보다 미래의 단어들을 참고하지 못하고록 하는 방법

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)