Variational AutoEncoder 를 이해하기 위한 기초
두 번째 Auto-Encoder 이해하기 = Auto-Encoder가 나온 이유
***복습
지난 글에서 인코더는 데이터들이 가진 규칙(가정)을 찾아서 데이터를 이루는 숫자 개수를 줄여서 표현하는 것.
이 데이터를 인코딩 한다고 하였을 때, 숫자 2개를 숫자 1개로 압축을 진행
그러기 위해서는 이 데이터는 어떠한 규칙을 따른다는 가정을 찾아야함.
규칙을 찾기 어려우니 2D 데이터 이니까 xy좌표로 각 데이터를 점으로 뿌려서 어떤 특성의 데이터인지 확인.
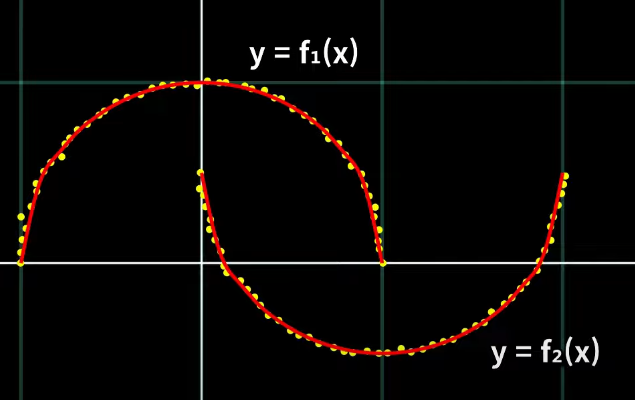
여기서 이 y좌표가 x의 어떤 함수인지 각각의 수식을 알 때, x를 알 때 y를 알 수 있어서 x만 저장해도 y까지 같이 복원할 수 있음.
예시처럼 어떤 데이터를 한 개 숫자로 줄였다가 다시 원래 데이터로 복원하는 게 인코딩 디코딩임.
하지만 직접 찾은 가정/규칙을 수동으로 인코딩 디코딩을 짜는 건 실제 데이터를 사용해서는 굉장히 복잡하고, 가정/규칙이 오차가 있으면 정확히 디코딩이 되지가 않음.
--> 그래서 나온 모델이 AutoEncoder
AutoEncoder에서의 Auto는 규칙이나 가정을 찾아서 공식을 만드는 과정을 자동으로 함.
e = torch.nn.Sequential(
torch.nn.Linear(2, h),
torch.nn.Tanh(),
torch.nn.Linear(h,h),
torch.nn.Tanh(),
torch.nn.Linear(h,1),
)
d = torch.nn.Sequential(
torch.nn.Linear(1,h),
torch.nn.Tanh(),
torch.nn.Linear(h,h),
torch.nn.Tanh(),
torch.nn.Linear(h,2),
)
w = torch.nn.Sequential(e, d)딥 러닝 모델로 설계한 AutoEncoder의 모델 구성은 입력이랑 출력의 차원은 같게 두고 모델의 중간 부분은 입력 출력의 숫자 개수보다 적게(더 적은 차원 공간으로) 둠.
이 모델의 학습 목표는
for i in range(20000):
opt.zero_grad()
x_hat = w(x)
l = torch.nn.functional.l1_loss(x, x_hat)
l.backward()
if i % 100 == 0:
print(f"{l.item():.3f}")
opt.step()모델 출력 x_hat이 입력이랑 정확히 같으라고 시키는 방식으로 학습이 진행.

차원이 줄어들기 때문에 데이터들이 가진 어떤 가정을 보고 경우의 수를 줄일 수 있는 어떤 방법이 있는지를 자동으로 찾음.
그리고 이 인코딩 된 숫자들로부터 최대한 복원이 가능하도록 하는 디코더 방식을 AutoEncoder
이제 마지막으로 생성 모델에서의 VAE 알기전에
생성 모델이 생성하는 법은 확률 분포에서 샘플링 하는 것
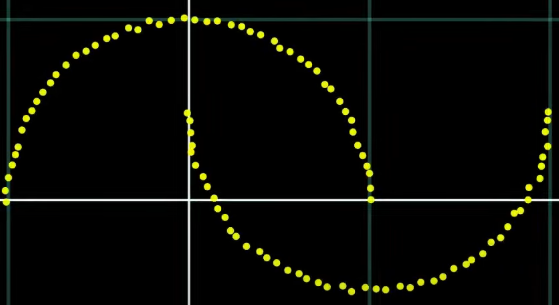
이 데이터를 어떤 쉬운 분포에서 샘플링 한다고 했을 때 그 결과는 쉽지 않음.
마찬가지로 샘플링 했을 때 고양이 이미지가 나오는 확률 분포를 설계한다는 건 매우 어려운 일.
하지만, 이 인코딩된 숫자를 쉬운 확률 분포(Gaussian)에서 샘플링 된 것 처럼 만들 수 있다면??
(인코딩인 척하는)샘플링한 숫자 -> 디코더에만 통과를 시켜주면 어려운 고양이 이미지를 생성 가능
--> 이러한 아이디를 이용하여 인코딩을 샘플링하는 Variational AutoEncoder 다음 시간에
