머신러닝 공부를 하다보면, 극한의 개념을 마주치게 된다. 그런데 극한을 정의하는게 내가 고등학생때 배운 것과는 좀 다른 것 같은데, 보통 입실론델타 논법으로 극한을 정의한다. 다음은 함수의 극한에 대한 정의이다.
- 다변수 함수의 극한
다변수 함수 에 대하여, 함수 의 정의역에 속한 점 을 생각하자. 임의의 과 를 만족하는 에 대하여 을 만족하는 이 존재할 때, 을 가 에 가까이 갈 때 의 극한이라 하고 다음과 같이 나타낸다.
이것이 입실론과 델타를 이용한 전통적인 극한의 정의이다. 그런데 문제는 잘 와닿지 않는다는 것이다. 이 문제를 한번 발로 그려보겠다. (그림 편의상 일변수함수에서 그린다.)
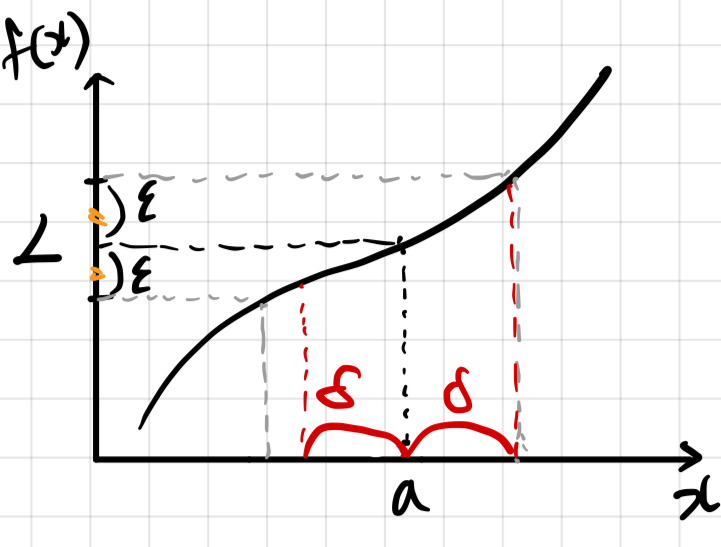
그림에서 보듯이, 내가 특정 L 값에서 같은 크기로 만큼의 갭을 잡았을 때 그 사이에 해당하는 값들만큼 x값에서 내가 크기를 잡아서 전부 사이로 보낼 수 있다면, 그때의 값은 극한 값이 된다. 이와 같은 상황에서는 값을 엄청 늘리든 엄청 작게하든 언제든 값을 잡을 수 있다. 그런데 다음과 같은 상황에서는 를 잡을 수 없다.
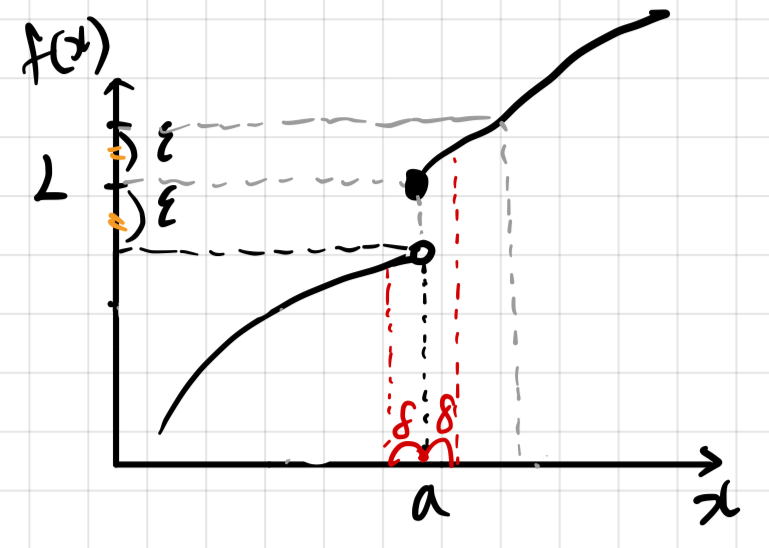
그림에서 보듯이, 내가 특정 L 값에서 같은 크기로 만큼의 갭을 잡았는데 위 그림과 같이 값이 continuous 하지 못한 곳에서는 내가 아무리 값을 정해도 값을 사이에로 보낼 수 없다.
즉, 정리해보면 이 어떻게 주어지더라도, 와 사이의 거리를 충분히 작게 함으로써 와 사이의 거리를 보다 작게 할 수 있다는 것이다.
이 개념을 알고 있어야 되나 싶기는 하지만, 미분이 중요한 머신러닝에서 언젠가 필요한 기본배경이 되지 않을까 싶다.

Deep Learning, Multi-Agent RL, Large Language Model, Statistics