1. Elasticsearch란
Elasticsearch는 오픈소스 분산 검색 및 분석 엔진입니다.
대규모 데이터셋에서 실시간으로 텍스트, 숫자, 지리정보 등을 검색/분석할 수 있도록 설계되었습니다.
분산 아키텍처와 강력한 검색 기능으로 인해 실시간 데이터 분석에 적합하며, 로그 메트릭 또는 소셜 미디어 업데이트와 같은 실시간 데이터를 처리할 때 효율적입니다.
핵심 개념
- 문서(Document) 기반 저장 : JSON 형태의 문서 단위로 데이터를 저장
- 역색인(Inverted Index) : 빠른 검색을 위해 단어 단위 색인 생성
- 분산형 아키텍처 : 여러 서버에 데이터를 자동 분산 저장
- RESTful API : HTTP를 통한 모든 조작 가능
- Near Real-Time : 색인 후 몇 초 내 검색 가능
주요 특징
- 문서 지향 저장소 : JSON 기반 문서 색인
- 역색인 검색 엔진 : 고속 검색
- 수평 확장 : 노드 추가로 용량·성능 증가
- RESTful API : HTTP 요청으로 조작
- Near Real-Time : 수초 내 검색 가능
- 스키마 유연성 : 새로운 필드 자동 매핑
2. Elasticsearch vs RDBMS
| 구분 | RDBMS (관계형 DB) | Elasticsearch |
|---|---|---|
| 데이터 모델 | 테이블(스키마 엄격) | JSON 문서(스키마 유연) |
| 저장 방식 | Row 중심 | 역색인(Inverted Index) 기반 |
| 질의 언어 | SQL | Query DSL(JSON 기반) |
| 트랜잭션 | 완전 ACID 지원 | 일부 일관성 보장(Eventual Consistency) |
| 스케일링 | 주로 수직 확장 | 수평 확장(샤드/레플리카 기반) |
| 검색 속도 | 기본 LIKE 검색 느림 | 매우 빠른 전문 검색 |
| 활용 분야 | 트랜잭션 처리, 관계 데이터 관리 | 로그 분석, 검색, 모니터링 |
언제 무엇을 쓰나?
- 트랜잭션 무결성과 관계 데이터: RDBMS
- 대규모 검색과 실시간 분석: Elasticsearch
3. ELK vs EFK
Elasticsearch 단독으로는 수집과 시각화가 어려워, 통합 스택을 사용합니다.
ELK
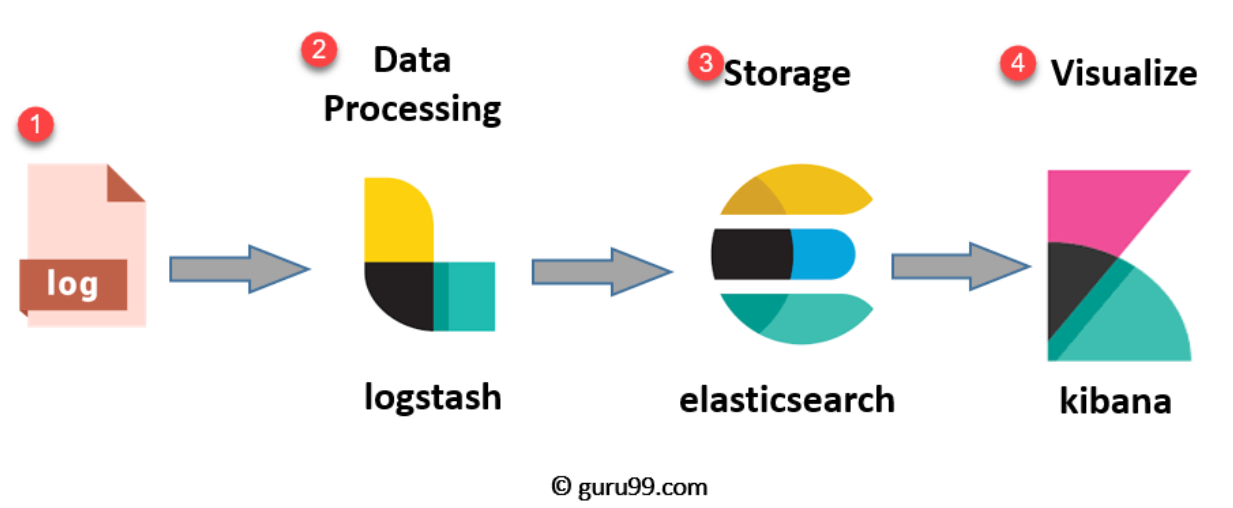
출처 : https://www.guru99.com/ko/elk-stack-tutorial.html
| 구성요소 | 역할 |
|---|---|
| Elasticsearch | - JSON 기반의 분산형 검색 및 분석 엔진 - 데이터 저장소. 빅데이터 처리할 때 매우 유용 - 확장성(json 문법만 가능)이 매우 좋은 java로 구현된 오픈소스 검색엔진 |
| Beats | - 데이터 수집 및 전송 - 단일 장치의 데이터를 전송하는 경량 데이터 수집기 플랫폼 - ElasticSearch 5.0.0버전부터 Beats 포함됨 |
| Logstash | - 데이터 수집·가공·전송 파이프라인 - 다양한 소스(파일, syslog, Redis 등)로부터 로그를 수집하고, 다양한 필터를 통해 로그 가공 - 장점 : 강력한 이벤트 처리 및 필터링 기능. 다양한 입출력 플러그인. Elasticsearch와의 긴밀한 통합 - 단점 : java 기반으로 메모리 사용량이 높고 리소스 집약적. 복잡한 설정. 확장성 부족 |
| Kibana | - 데이터 시각화 대시보드 - 확장형 사용자 인터페이스로 데이터를 구체적으로 시각화 (oracle의 sqlplus와 흡사) |
특징
- Logstash가 다양한 플러그인과 강력한 데이터 처리 기능을 제공.
- 대규모 로그 파싱에 적합하나 무겁다.
EFK
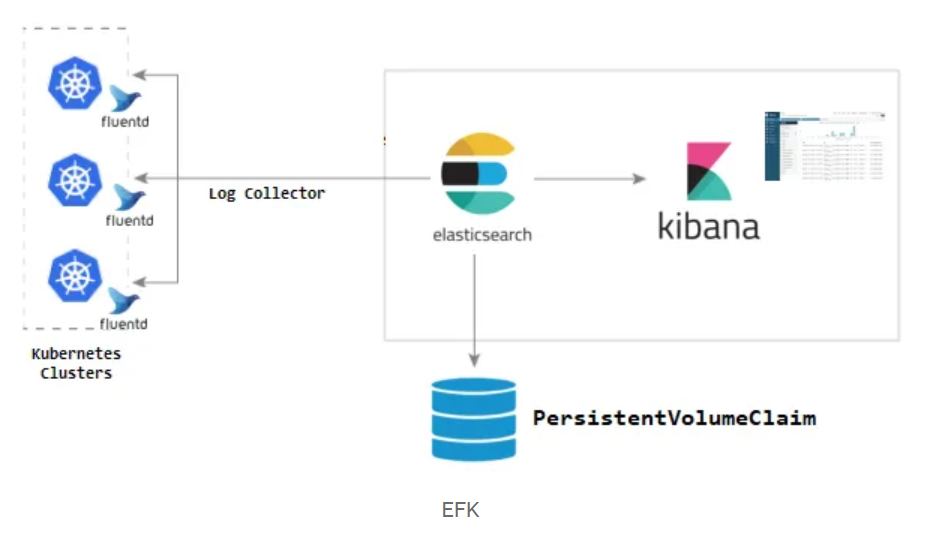
출처 : https://medium.com/avmconsulting-blog/how-to-deploy-an-efk-stack-to-kubernetes-ebc1b539d063
| 구성요소 | 역할 |
|---|---|
| Elasticsearch | - 저장 및 검색 |
| Fluentd | - 경량 로그 수집·전송 에이전트 - 데이터가 만들어지는 곳에 붙어 해당 데이터 수집 - 장점 : 경량. 높은 성능과 확장성. 단순한 설정. 풍부한 클러그인 생태계. 클라우드 네이티브 - 단점 : 이젠트 처리 및 필터링 기능이 logstash에 비해 다소 제한적 |
| Kibana | - 데이터 시각화 대시보드 |
특징
- Fluentd는 클라우드·Kubernetes 환경에 최적화.
- 리소스 소모가 적고, yaml 방식 설정이 용이.
ELK vs EFK 요약표
| 구분 | ELK | EFK |
|---|---|---|
| 수집 도구 | Logstash | Fluentd |
| 리소스 사용 | 상대적으로 무겁다 | 경량, 클라우드 친화 |
| 환경 | 온프레미스, 서버 중심 | Kubernetes, 클라우드 네이티브 |
| 설정 | Grok 패턴 DSL | Yaml 설정 |
4. 샤딩, 파티셔닝, 레플리카
Elasticsearch의 분산 아키텍처를 이해하기 위한 용어들
샤딩(Sharding)
-
대규모 인덱스를 여러 작은 단위로 분리하는 것
-
각 샤드는 독립적인 Lucene 인스턴스
-
클러스터 노드에 자동 분산
-
검색/색인 작업 병렬 처리로 성능 향상
예시
1억 건 데이터 → 5 샤드 → 각 샤드 2천만 건씩 분산 저장
파티셔닝(Partitioning)
-
데이터를 나누는 일반적 개념
- 샤딩 = Elasticsearch의 파티셔닝 방식 중 하나
- RDBMS에서는 Range Partition, List Partition 등 사용
차이
용어 설명 파티셔닝 논리적으로 데이터를 여러 부분으로 나누는 것 샤딩 파티셔닝 + 노드 분산 저장 (분산 처리 전제)
레플리카(Replica)
-
샤드를 복제한 사본
-
장애 대비 고가용성 확보
-
검색 부하 분산에 활용
-
권장 설정: 1개 샤드 + 2개 레플리카
예시
5 샤드, 레플리카 1개 → 총 10개의 물리적 샤드
정리
| 구분 | 샤드(Shard) | 파티션(Partition) | 레플리카(Replica) |
|---|---|---|---|
| 목적 | 데이터 분산 저장 및 병렬 처리 | 데이터 논리 분리 | 데이터 복제 및 가용성 확보 |
| 저장 위치 | 클러스터 내 여러 노드 | 단일/분산 저장 모두 가능 | 원본 샤드와 다른 노드에 저장 |
| 특징 | Elasticsearch 고유 개념 | 범용 개념(RDBMS, NoSQL 포함) | Elasticsearch 고유 개념 |
참고 자료

말하는 고구마