
1. 역 인덱스 (Inverted Index)
- 일반 RDB는
LIKE '%fox%'로 전체 로우 탐색 - Elasticsearch는 term → 문서 ID 목록 구조로 빠른 검색 가능
2. 텍스트 분석 (Text Analysis)
전체 흐름
- Character Filter: 전처리 (HTML 제거, 치환 등)
- Tokenizer: 텍스트 → 토큰 분리
- Token Filter: 소문자화, 불용어 제거, 형태소 분석 등
"The quick brown fox" → whitespace tokenizer → lowercase → stop → snowball 적용 → "quick", "brown", "fox"
3. _analyze와 Term 쿼리
3.1 _analyze API
POST /_analyze { "analyzer": "standard", "text": "Hello, HELLO, World!" }→ "hello", "world"
3.2 term 쿼리
- 정확히 일치하는 토큰 검색
"term": { "username": "kimgn" }
4. 사용자 정의 Analyzer
PUT my_index3 { "settings": { "index": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "whitespace", "filter": ["lowercase", "stop", "snowball"] } } } } } }
- 분석 결과 확인:
GET my_index3/_analyze { "analyzer": "my_custom_analyzer", "text": ["The quick brown fox jumps over the lazy dog"] }→ "quick", "brown", "fox", "jump", "over", "lazy", "dog"
5. _termvectors API
- 특정 문서의 term frequency, 위치, offset 등을 확인
GET my_index3/_termvectors/1?fields=message
6. Character Filters
6.1 html_strip
- HTML 태그 제거
{ "tokenizer": "standard", "char_filter": ["html_strip"], "text": "<p>Hello <b>World</b></p>" }→ "hello", "world"
6.2 mapping
- 문자열 치환
"mappings": ["C++ => C_plus_plus"]→ "c_plus_plus"
6.3 pattern_replace
- CamelCase → 공백 삽입
"pattern": "(?<=\\p{Lower})(?=\\p{Upper})"→ "camelCaseWord" → "camel", "case", "word"
7. Tokenizer
7.1 기본 Tokenizer
| 이름 | 기능 | 예시 |
|---|---|---|
standard | 문장 분석 | Quick, Fox, 123 |
letter | 문자 단위 | Quick, Fox |
whitespace | 공백 분리 | Quick-Fox, 123 |
7.2 uax_url_email
- URL, 이메일 통째로 토큰화
7.3 pattern
- 쉼표/공백 기준 분리
"pattern": "[,|\\s]+"→ "apple, banana orange" → "apple", "banana", "orange"
7.4 path_hierarchy
- 파일 경로 분리
"/home/user/docs" → "/home", "/home/user", "/home/user/docs"
8. Token Filter
8.1 lowercase / uppercase
"Fox" → "fox"
"fox" → "FOX"
8.2 stop
- "the", "is" 제거
8.3 synonym
- 동의어 매핑
"synonyms": ["usa, united states"]→ 동일하게 처리
8.4 ngram, edge_ngram, shingle
"quick" → "q", "qu", "qui" 등
8.5 unique
- 중복 제거
"fox", "fox" → "fox"
9. 형태소 분석기
9.1 snowball
- 영어 기반 어간 추출
"jumps", "jumped" → "jump"
9.2 nori
- 한국어 분석기
"삼성전자의 주가가 상승했다" → "삼성전자", "주가", "상승"
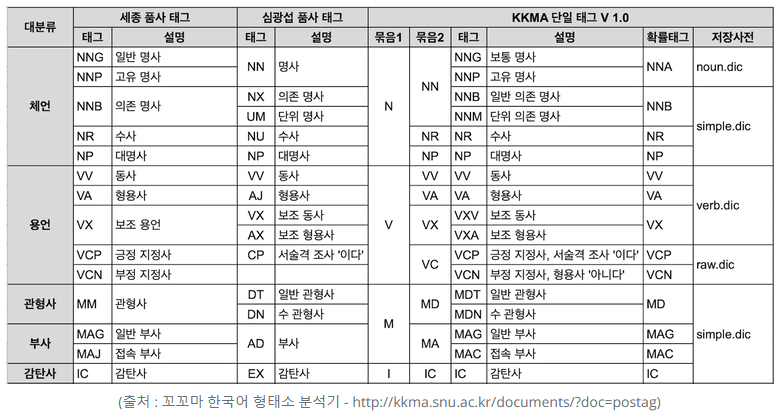
참고

말하는 고구마